
人工智慧、機器學習和深度學習的區別?
作者:育心
連結:https://www.zhihu.com/question/57770020/answer/249708509
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
人工智慧的浪潮正在席捲全球,諸多詞彙時刻縈繞在我們耳邊:人工智慧(Artificial Intelligence)、機器學習(Machine Learning)、深度學習(Deep Learning)。不少人對這些高頻詞彙的含義及其背後的關係總是似懂非懂、一知半解。
為了幫助大家更好地理解人工智慧,這篇文章用最簡單的語言解釋了這些詞彙的含義,理清它們之間的關係,希望對剛入門的同行有所幫助。

圖一 人工智慧的應用
人工智慧:從概念提出到走向繁榮
1956年,幾個電腦科學家相聚在達特茅斯會議,提出了“人工智慧”的概念,夢想著用當時剛剛出現的計算機來構造複雜的、擁有與人類智慧同樣本質特性的機器。其後,人工智慧就一直縈繞於人們的腦海之中,並在科研實驗室中慢慢孵化。之後的幾十年,人工智慧一直在兩極反轉,或被稱作人類文明耀眼未來的預言,或被當成技術瘋子的狂想扔到垃圾堆裡。直到2012年之前,這兩種聲音還在同時存在。
2012年以後,得益於資料量的上漲、運算力的提升和機器學習新演算法(深度學習)的出現,人工智慧開始大爆發。據領英近日釋出的《全球AI領域人才報告》顯示,截至2017年一季度,基於領英平臺的全球AI(人工智慧)領域技術人才數量超過190萬,僅國內人工智慧人才缺口達到500多萬。
人工智慧的研究領域也在不斷擴大,圖二展示了人工智慧研究的各個分支,包括專家系統、機器學習、進化計算、模糊邏輯、計算機視覺、自然語言處理、推薦系統等。
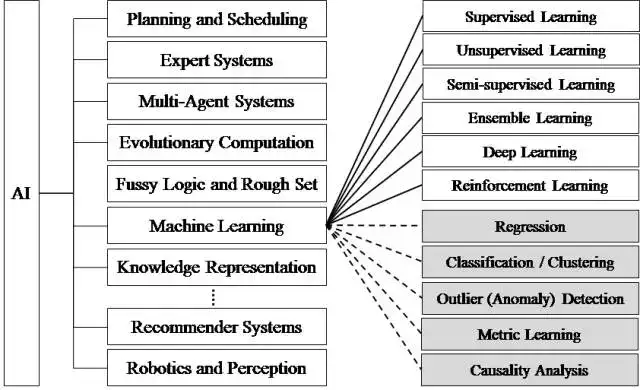
圖二 人工智慧研究分支
但目前的科研工作都集中在弱人工智慧這部分,並很有希望在近期取得重大突破,電影裡的人工智慧多半都是在描繪強人工智慧,而這部分在目前的現實世界裡難以真正實現(通常將人工智慧分為弱人工智慧和強人工智慧,前者讓機器具備觀察和感知的能力,可以做到一定程度的理解和推理,而強人工智慧讓機器獲得自適應能力,解決一些之前沒有遇到過的問題)。
弱人工智慧有希望取得突破,是如何實現的,“智慧”又從何而來呢?這主要歸功於一種實現人工智慧的方法——機器學習。
機器學習:一種實現人工智慧的方法
機器學習最基本的做法,是使用演算法來解析資料、從中學習,然後對真實世界中的事件做出決策和預測。與傳統的為解決特定任務、硬編碼的軟體程式不同,機器學習是用大量的資料來“訓練”,通過各種演算法從資料中學習如何完成任務。
舉個簡單的例子,當我們瀏覽網上商城時,經常會出現商品推薦的資訊。這是商城根據你往期的購物記錄和冗長的收藏清單,識別出這其中哪些是你真正感興趣,並且願意購買的產品。這樣的決策模型,可以幫助商城為客戶提供建議並鼓勵產品消費。
機器學習直接來源於早期的人工智慧領域,傳統的演算法包括決策樹、聚類、貝葉斯分類、支援向量機、EM、Adaboost等等。從學習方法上來分,機器學習演算法可以分為監督學習(如分類問題)、無監督學習(如聚類問題)、半監督學習、整合學習、深度學習和強化學習。
傳統的機器學習演算法在指紋識別、基於Haar的人臉檢測、基於HoG特徵的物體檢測等領域的應用基本達到了商業化的要求或者特定場景的商業化水平,但每前進一步都異常艱難,直到深度學習演算法的出現。
傳統的機器學習:
機器學習(ML)技術在預測中發揮了重要的作用,ML經歷了多代的發展,形成了具有豐富的模型結構,例如:
1.線性迴歸。
2.邏輯迴歸。
3.決策樹。
4.支援向量機。
5.貝葉斯模型。
6.正則化模型。
7.模型整合(ensemble)。
8.神經網路。
這些預測模型中的每一個都基於特定的演算法結構,引數都是可調的。訓練預測模型涉及以下步驟:
1. 選擇一個模型結構(例如邏輯迴歸,隨機森林等)。
2. 用訓練資料(輸入和輸出)輸入模型。
3. 學習演算法將輸出最優模型(即具有使訓練錯誤最小化的特定引數的模型)。
每種模式都有自己的特點,在一些任務中表現不錯,但在其他方面表現不佳。但總的來說,我們可以把它們分成低功耗(簡單)模型和高功耗(複雜)模型。選擇不同的模型是一個非常棘手的問題。
由於以下原因,使用低功率/簡單模型是優於使用高功率/複雜模型:
- 在我們擁有強大的處理能力之前,訓練高功率模型將需要很長的時間。
- 在我們擁有大量資料之前,訓練高功率模型會導致過度擬合問題(因為高功率模型具有豐富的引數並且可以適應廣泛的資料形狀,所以我們最終可能訓練一個適合於特定到當前的訓練資料,而不是推廣到足以對未來的資料做好預測)。
作者:阿里云云棲社群
連結:https://www.zhihu.com/question/57770020/answer/345340746
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
深度學習:一種實現機器學習的技術
深度學習本來並不是一種獨立的學習方法,其本身也會用到有監督和無監督的學習方法來訓練深度神經網路。但由於近幾年該領域發展迅猛,一些特有的學習手段相繼被提出(如殘差網路),因此越來越多的人將其單獨看作一種學習的方法。
最初的深度學習是利用深度神經網路來解決特徵表達的一種學習過程。深度神經網路本身並不是一個全新的概念,可大致理解為包含多個隱含層的神經網路結構。為了提高深層神經網路的訓練效果,人們對神經元的連線方法和啟用函式等方面做出相應的調整。其實有不少想法早年間也曾有過,但由於當時訓練資料量不足、計算能力落後,因此最終的效果不盡如人意。
深度學習摧枯拉朽般地實現了各種任務,使得似乎所有的機器輔助功能都變為可能。無人駕駛汽車,預防性醫療保健,甚至是更好的電影推薦,都近在眼前,或者即將實現。
三者的區別和聯絡
機器學習是一種實現人工智慧的方法,深度學習是一種實現機器學習的技術。我們就用最簡單的方法——同心圓,視覺化地展現出它們三者的關係。
圖三 三者關係示意圖
目前,業界有一種錯誤的較為普遍的意識,即“深度學習最終可能會淘汰掉其他所有機器學習演算法”。這種意識的產生主要是因為,當下深度學習在計算機視覺、自然語言處理領域的應用遠超過傳統的機器學習方法,並且媒體對深度學習進行了大肆誇大的報道。
深度學習,作為目前最熱的機器學習方法,但並不意味著是機器學習的終點。起碼目前存在以下問題:
1. 深度學習模型需要大量的訓練資料,才能展現出神奇的效果,但現實生活中往往會遇到小樣本問題,此時深度學習方法無法入手,傳統的機器學習方法就可以處理;
2. 有些領域,採用傳統的簡單的機器學習方法,可以很好地解決了,沒必要非得用複雜的深度學習方法;
3. 深度學習的思想,來源於人腦的啟發,但絕不是人腦的模擬,舉個例子,給一個三四歲的小孩看一輛自行車之後,再見到哪怕外觀完全不同的自行車,小孩也十有八九能做出那是一輛自行車的判斷,也就是說,人類的學習過程往往不需要大規模的訓練資料,而現在的深度學習方法顯然不是對人腦的模擬。
深度學習大佬 Yoshua Bengio 在 Quora 上回答一個類似的問題時,有一段話講得特別好,這裡引用一下,以回答上述問題:
Science is NOT a battle, it is a collaboration. We all build on each other's ideas. Science is an act of love, not war. Love for the beauty in the world that surrounds us and love to share and build something together. That makes science a highly satisfying activity, emotionally speaking!
這段話的大致意思是,科學不是戰爭而是合作,任何學科的發展從來都不是一條路走到黑,而是同行之間互相學習、互相借鑑、博採眾長、相得益彰,站在巨人的肩膀上不斷前行。機器學習的研究也是一樣,你死我活那是邪教,開放包容才是正道。
結合機器學習2000年以來的發展,再來看Bengio的這段話,深有感觸。進入21世紀,縱觀機器學習發展歷程,研究熱點可以簡單總結為2000-2006年的流形學習、2006年-2011年的稀疏學習、2012年至今的深度學習。未來哪種機器學習演算法會成為熱點呢?深度學習三大巨頭之一吳恩達曾表示,“在繼深度學習之後,遷移學習將引領下一波機器學習技術”。但最終機器學習的下一個熱點是什麼,誰又能說得準呢。