
剖析Disruptor:為什麼會這麼快?(三)揭祕記憶體屏障
譯者:杜建雄 校對:歐振聰
最近我部落格文章更新有點慢,因為我在忙著寫一篇介紹記憶體屏障(Memory Barries)以及如何將其應用於Disruptor的文章。問題是,無論我翻閱了多少資料,向耐心的Martin和Mike請教了多少遍,以試圖理清一些知識點,可我總是不能直觀地抓到重點。大概是因為我不具備深厚的背景知識來幫助我透徹理解。
所以,與其像個傻瓜一樣試圖去解釋一些自己都沒完全弄懂的東西,還不如在抽象和大量簡化的層次上,把我在該領域所掌握的知識分享給大家 。Martin已經寫了一篇文章《going into memory barriers》介紹記憶體屏障的一些具體細節,所以我就略過不說了。
免責宣告:文章中如有錯誤全由本人負責,與Disruptor的實現和LMAX裡真正懂這些知識的大牛們無關。
主題是什麼?
我寫這個系列的部落格主要目的是解析Disruptor是如何工作的,並深入瞭解下為什麼這樣工作。理論上,我應該從可能準備使用disruptor的開發人員的角度來寫,以便在程式碼和技術論文[Disruptor-1.0.pdf]之間搭建一座橋樑。這篇文章提及到了記憶體屏障,我想弄清楚它們到底是什麼,以及它們是如何應用於實踐中的。
什麼是記憶體屏障?
它是一個CPU指令。沒錯,又一次,我們在討論CPU級別的東西,以便獲得我們想要的效能(Martin著名的Mechanical Sympathy理論)。基本上,它是這樣一條指令: a)確保一些特定操作執行的順序; b)影響一些資料的可見性(可能是某些指令執行後的結果)。
編譯器和CPU可以在保證輸出結果一樣的情況下對指令重排序,使效能得到優化。插入一個記憶體屏障,相當於告訴CPU和編譯器先於這個命令的必須先執行,後於這個命令的必須後執行。正如去拉斯維加斯旅途中各個站點的先後順序在你心中都一清二楚。
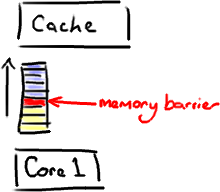
記憶體屏障另一個作用是強制更新一次不同CPU的快取。例如,一個寫屏障會把這個屏障前寫入的資料重新整理到快取,這樣任何試圖讀取該資料的執行緒將得到最新值,而不用考慮到底是被哪個cpu核心或者哪顆CPU執行的。
和Java有什麼關係?
現在我知道你在想什麼——這不是彙編程式。它是Java。
這裡有個神奇咒語叫volatile(我覺得這個詞在Java規範中從未被解釋清楚)。如果你的欄位是volatile,Java記憶體模型將在寫操作後插入一個寫屏障指令,在讀操作前插入一個讀屏障指令。
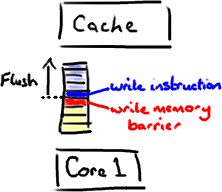
這意味著如果你對一個volatile欄位進行寫操作,你必須知道:
1、一旦你完成寫入,任何訪問這個欄位的執行緒將會得到最新的值。
2、在你寫入前,會保證所有之前發生的事已經發生,並且任何更新過的資料值也是可見的,因為記憶體屏障會把之前的寫入值都重新整理到快取。
舉個例子唄!
很高興你這樣說了。又是時候讓我來畫幾個甜甜圈了。
RingBuffer的指標(cursor)(譯註:指向隊尾元素)屬於一個神奇的volatile變數,同時也是我們能夠不用鎖操作就能實現Disruptor的原因之一。
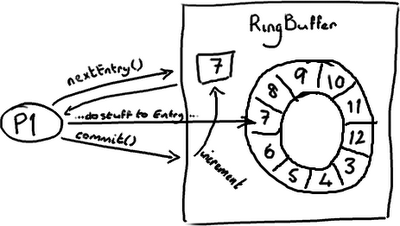
生產者將會取得下一個Entry(或者是一批),並可對它(們)作任意改動, 把它(們)更新為任何想要的值。如你所知,在所有改動都完成後,生產者對ring buffer呼叫commit方法來更新序列號(譯註:把cursor更新為該Entry的序列號)。對volatile欄位(cursor)的寫操作建立了一個記憶體屏障,這個屏障將重新整理所有快取裡的值(或者至少相應地使得快取失效)。
這時候,消費者們能獲得最新的序列號碼(8),並且因為記憶體屏障保證了它之前執行的指令的順序,消費者們可以確信生產者對7號Entry所作的改動已經可用。
…那麼消費者那邊會發生什麼?
消費者中的序列號是volatile型別的,會被若干個外部物件讀取——其他的下游消費者可能在跟蹤這個消費者。ProducerBarrier/RingBuffer(取決於你看的是舊的還是新的程式碼)跟蹤它以確保環沒有出現重疊(wrap)的情況(譯註:為了防止下游的消費者和上游的消費者對同一個Entry競爭消費,導致在環形佇列中互相覆蓋資料,下游消費者要對上游消費者的消費情況進行跟蹤)。
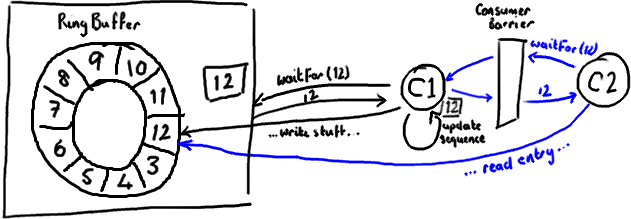
所以,如果你的下游消費者(C2)看見前一個消費者(C1)在消費號碼為12的Entry,當C2的讀取也到了12,它在更新序列號前將可以獲得C1對該Entry的所作的更新。
基本來說就是,C1更新序列號前對ring buffer的所有操作(如上圖黑色所示),必須先發生,待C2拿到C1更新過的序列號之後,C2才可以為所欲為(如上圖藍色所示)。
對效能的影響
記憶體屏障作為另一個CPU級的指令,沒有鎖那樣大的開銷。核心並沒有在多個執行緒間干涉和排程。但凡事都是有代價的。記憶體屏障的確是有開銷的——編譯器/cpu不能重排序指令,導致不可以儘可能地高效利用CPU,另外重新整理快取亦會有開銷。所以不要以為用volatile代替鎖操作就一點事都沒。
你會注意到Disruptor的實現對序列號的讀寫頻率儘量降到最低。對volatile欄位的每次讀或寫都是相對高成本的操作。但是,也應該認識到在批量的情況下可以獲得很好的表現。如果你知道不應對序列號頻繁讀寫,那麼很合理的想到,先獲得一整批Entries,並在更新序列號前處理它們。這個技巧對生產者和消費者都適用。以下的例子來自BatchConsumer:
long nextSequence = sequence + 1;
while (running)
{
try
{
final long availableSequence = consumerBarrier.waitFor(nextSequence);
while (nextSequence <= availableSequence)
{
entry = consumerBarrier.getEntry(nextSequence);
handler.onAvailable(entry);
nextSequence++;
}
handler.onEndOfBatch();
sequence = entry.getSequence();
}
…
catch (final Exception ex)
{
exceptionHandler.handle(ex, entry);
sequence = entry.getSequence();
nextSequence = entry.getSequence() + 1;
}
}
(你會注意到,這是個舊式的程式碼和命名習慣,因為這是摘自我以前的部落格文章,我認為如果直接轉換為新式的程式碼和命名習慣會讓人有點混亂)
在上面的程式碼中,我們在消費者處理entries的迴圈中用一個區域性變數(nextSequence)來遞增。這表明我們想盡可能地減少對volatile型別的序列號的進行讀寫。
總結
記憶體屏障是CPU指令,它允許你對資料什麼時候對其他程序可見作出假設。在Java裡,你使用volatile關鍵字來實現記憶體屏障。使用volatile意味著你不用被迫選擇加鎖,並且還能讓你獲得性能的提升。
但是,你需要對你的設計進行一些更細緻的思考,特別是你對volatile欄位的使用有多頻繁,以及對它們的讀寫有多頻繁。
PS:上文中講到的Disruptor中使用的New World Order 是一種完全不同於我目前為止所發表的博文中的命名習慣。我想下一篇文章會對舊式的和新式的命名習慣做一個對照。
延伸閱讀:

