
高效能佇列disruptor為什麼這麼快?
背景
 Disruptor是LMAX開發的一個高效能佇列,研發的初衷是解決記憶體佇列的延遲問題(在效能測試中發現竟然與I/O操作處於同樣的數量級)。基於Disruptor開發的系統單執行緒能支撐每秒600萬訂單,2010年在QCon演講後,獲得了業界關注。2011年,企業應用軟體專家Martin Fowler專門撰寫長文介紹。同年它還獲得了Oracle官方的Duke大獎。
Disruptor是LMAX開發的一個高效能佇列,研發的初衷是解決記憶體佇列的延遲問題(在效能測試中發現竟然與I/O操作處於同樣的數量級)。基於Disruptor開發的系統單執行緒能支撐每秒600萬訂單,2010年在QCon演講後,獲得了業界關注。2011年,企業應用軟體專家Martin Fowler專門撰寫長文介紹。同年它還獲得了Oracle官方的Duke大獎。
目前,包括Apache Storm、Camel、Log4j2在內的很多知名專案都應用了Disruptor以獲取高效能。
我們先知道disruptor是幹什麼的,然後筆者帶你們原始碼搞一波,再來看看在log4j2中的運用。
一、Disruptor是什麼?
可以這樣總結,Disruptor是LMAX開源的、用於替代併發執行緒間資料交換的環形佇列的、基本無鎖的(只有部分等待策略存在)、高效能的執行緒間通訊框架。
Disruptor唯一可能遇到Java鎖的時候,就是在消費者等待可用事件進行消費時。而Disruptor為這個等待過程,編寫了包括使用鎖和不使用鎖的多種策略,可根據不同場景和需求進行選擇。
開源:https://github.com/LMAX-Exchange/disruptor
二、Disruptor為什麼這麼快
1、環形佇列RingBuffer
一個環形佇列,意味著首尾相連,對列可以迴圈使用,使用陣列來儲存。環形佇列在JVM生命週期中通常是永生的,GC的壓力更小
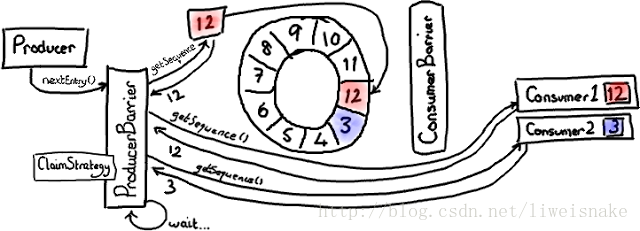
我們來解釋一下這個圖:當前有一個consumer,停留在位置12,這時producer假設在位置3,這時producer的下一步是如何處理的呢?producer會嘗試讀取4,發現下一個可以獲取,所以可以安全獲取,並且通知一個阻塞的consumer起來活動。如此一直到下一圈11都是安全的(這裡我們假設生產者比較快),當producer嘗試訪問12時發現不能繼續,於是自旋等待;當consumer消費時,會呼叫barrier的waitFor方法,waitFor看到前面最近的安全節點已經到了下一圈的11,於是consumer可以無鎖的去消費當前12到下一圈11所有資料,可以想象,這種方式比起synchronized要快上很多倍。
2、棄用鎖機制使用CAS
在高度競爭的情況下,鎖的效能將超過原子變數的效能,但是更真實的競爭情況下,原子變數的效能將超過鎖的效能。同時原子變數不會有死鎖等活躍性問題。能不用鎖,就不使用鎖,如果使用,也要將鎖的粒度最小化。
唯一使用鎖的就是消費者的等待策略實現類中,下圖。補充一句,生產者的等到策略就是LockSupport.parkNanos(1),再自旋判斷。
| 名稱 | 措施 | 適用場景 |
|---|---|---|
| BlockingWaitStrategy | 加鎖 | CPU資源緊缺,吞吐量和延遲並不重要的場景 |
| BusySpinWaitStrategy | 自旋 | 通過不斷重試,減少切換執行緒導致的系統呼叫,而降低延遲。推薦線上程繫結到固定的CPU的場景下使用 |
| PhasedBackoffWaitStrategy | 自旋 + yield + 自定義策略 | CPU資源緊缺,吞吐量和延遲並不重要的場景 |
| SleepingWaitStrategy | 自旋 + yield + sleep | 效能和CPU資源之間有很好的折中。延遲不均勻 |
| TimeoutBlockingWaitStrategy | 加鎖,有超時限制 | CPU資源緊缺,吞吐量和延遲並不重要的場景 |
| YieldingWaitStrategy | 自旋 + yield + 自旋 | 效能和CPU資源之間有很好的折中。延遲比較均勻 |
3、解決偽共享,採用快取行填充
abstract class SingleProducerSequencerPad extends AbstractSequencer { protected long p1, p2, p3, p4, p5, p6, p7; SingleProducerSequencerPad(int bufferSize, WaitStrategy waitStrategy) { super(bufferSize, waitStrategy); } } public final class SingleProducerSequencer extends SingleProducerSequencerFields { protected long p1, p2, p3, p4, p5, p6, p7; //..省略 }
Java中通過填充快取行,來解決偽共享問題的思路,現在可能已經是老生常談,連Java8中都新增了sun.misc.Contended註解來避免偽共享問題。但在Disruptor剛出道那會兒,用快取行來優化Java資料結構,這恐怕還很新潮。
4、還有一些細節性的
1)通過sequence & (bufferSize - 1)定位元素的index比普通的求餘取模(%)要快得多。sequence >>> indexShift 快速計算出sequence/bufferSize的商flag(其實相當於當前sequence在環形跑道上跑了幾圈,在資料生產時要設定好flag。
2)合理使用Unsafe,CPU級別指令。實現更加高效地記憶體管理和原子訪問。
至於一些更細節的,下面原始碼搞起來,還是很簡單的。
原始碼分析:
正在搞。。。
參考:
https://tech.meituan.com/disruptor.html
https://www.jianshu.com/p/c3c108c3dcfd