
解讀Raft協議(一 演算法基礎)
什麼是RAFT
分散式系統除了提升整個體統的效能外還有一個重要特徵就是提高系統的可靠性。
提供可靠性可以理解為系統中一臺或多臺的機器故障不會使系統不可用(或者丟失資料)。
保證系統可靠性的關鍵就是多副本(即資料需要有備份),一旦有多副本,那麼久面臨多副本之間的一致性問題。
一致性演算法正是用於解決分散式環境下多副本之間資料一致性的問題的。
業界最著名的一致性演算法就是大名鼎鼎的Paxos(Chubby的作者曾說過:世上只有一種一致性演算法,就是Paxos)。但Paxos是出了名的難懂,而Raft正是為了探索一種更易於理解的一致性演算法而產生的。
Raft is a consensus algorithm for managing a replicated log.
Raft是一種管理複製日誌的一致性演算法。
它的首要設計目的就是易於理解,所以在選主的衝突處理等方式上它都選擇了非常簡單明瞭的解決方案。
Raft將一致性拆分為幾個關鍵元素:
- Leader選舉
- 日誌複製
- 安全性
Raft演算法
所有一致性演算法都會涉及到狀態機,而狀態機保證系統從一個一致的狀態開始,以相同的順序執行一些列指令最終會達到另一個一致的狀態。
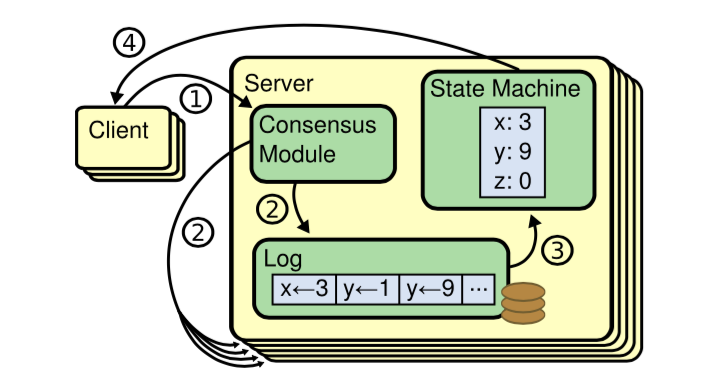
以上是狀態機的示意圖。所有的節點以相同的順序處理日誌,那麼最終x、y、z的值在多個節點中都是一致的。
演算法基礎
角色
Raft通過選舉Leader並由Leader節點負責管理日誌複製來實現多副本的一致性。
在Raft中,節點有三種角色:
- Leader:負責接收客戶端的請求,將日誌複製到其他節點並告知其他節點何時應用這些日誌是安全的
- Candidate:用於選舉Leader的一種角色
- Follower:負責響應來自Leader或者Candidate的請求
角色轉換如下圖所示:
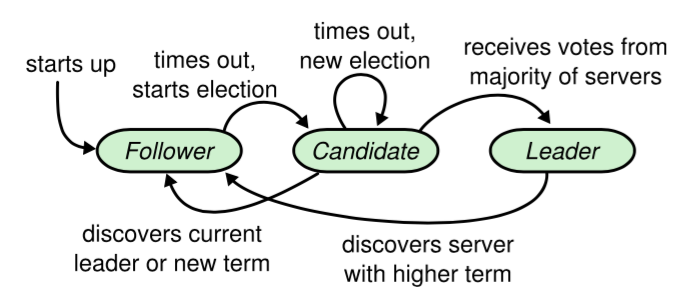
- 所有節點初始狀態都是Follower角色
- 超時時間內沒有收到Leader的請求則轉換為Candidate進行選舉
- Candidate收到大多數節點的選票則轉換為Leader;發現Leader或者收到更高任期的請求則轉換為Follower
- Leader在收到更高任期的請求後轉換為Follower
任期
Raft把時間切割為任意長度的任期,每個任期都有一個任期號,採用連續的整數。
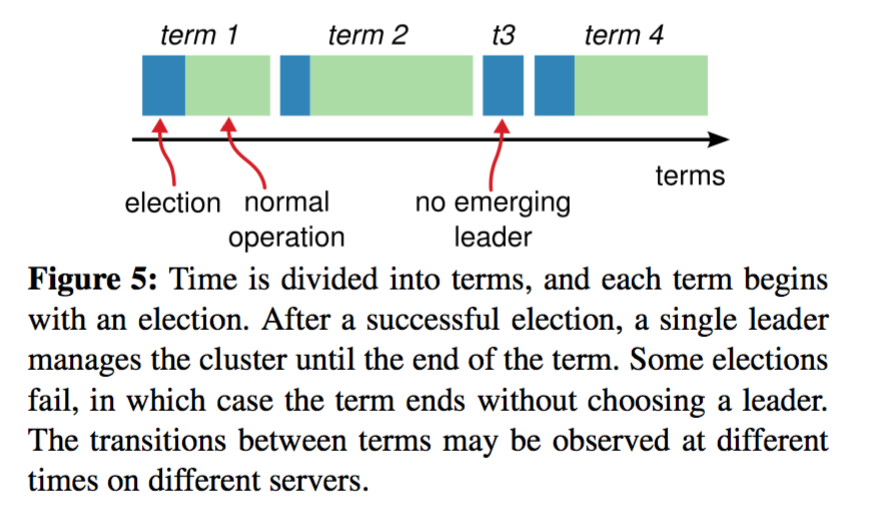
每個任期都由一次選舉開始,若選舉失敗則這個任期內沒有Leader;如果選舉出了Leader則這個任期內有Leader負責叢集狀態管理。
演算法
狀態
| 狀態 | 所有節點上持久化的狀態(在響應RPC請求之前變更且持久化的狀態) |
|---|---|
| currentTerm | 伺服器的任期,初始為0,遞增 |
| votedFor | 在當前獲得選票的候選人的 Id |
| log[] | 日誌條目集;每一個條目包含一個使用者狀態機執行的指令,和收到時的任期號 |
| 狀態 | 所有節點上非持久化的狀態 |
|---|---|
| commitIndex | 最大的已經被commit的日誌的index |
| lastApplied | 最大的已經被應用到狀態機的index |
| 狀態 | Leader節點上非持久化的狀態(選舉後重新初始化) |
|---|---|
| nextIndex[] | 每個節點下一次應該接收的日誌的index(初始化為Leader節點最後一個日誌的Index + 1) |
| matchIndex[] | 每個節點已經複製的日誌的最大的索引(初始化為0,之後遞增) |
AppendEntries RPC
用於Leader節點複製日誌給其他節點,也作為心跳。
| 引數 | 解釋 |
|---|---|
| term | Leader節點的任期 |
| leaderId | Leader節點的ID |
| prevLogIndex | 此次追加請求的上一個日誌的索引 |
| prevLogTerm | 此次追加請求的上一個日誌的任期 |
| entries[] | 追加的日誌(空則為心跳請求) |
| leaderCommit | Leader上已經Commit的Index |
prevLogIndex和prevLogTerm表示上一次傳送的日誌的索引和任期,用於保證收到的日誌是連續的。
| 返回值 | 解釋 |
|---|---|
| term | 當前任期號,用於Leader節點更新自己的任期(應該說是如果這個返回值比Leader自身的任期大,那麼Leader需要更新自己的任期) |
| success | 如何Follower節點匹配prevLogIndex和prevLogTerm,返回true |
接收者實現邏輯
- 返回false,如果收到的任期比當前任期小
- 返回false,如果不包含之前的日誌條目(沒有匹配prevLogIndex和prevLogTerm)
- 如果存在index相同但是term不相同的日誌,刪除從該位置開始所有的日誌
- 追加所有不存在的日誌
- 如果leaderCommit>commitIndex,將commitIndex設定為commitIndex = min(leaderCommit, index of last new entry)
RequestVote RPC
用於Candidate獲取選票。
| 引數 | 解釋 |
|---|---|
| term | Candidate的任期 |
| candidateId | Candidate的ID |
| lastLogIndex | Candidate最後一條日誌的索引 |
| lastLogTerm | Candidate最後一條日誌的任期 |
| 引數 | 解釋 |
|---|---|
| term | 當前任期,用於Candidate更新自己的任期 |
| voteGranted | true表示給Candidate投票 |
接收者的實現邏輯
- 返回false,如果收到的任期比當前任期小
- 如果本地狀態中votedFor為null或者candidateId,且candidate的日誌等於或多餘(按照index判斷)接收者的日誌,則接收者投票給candidate,即返回true
節點的執行規則
所有節點
- 如果commitIndex > lastApplied,應用log[lastApplied]到狀態機,增加lastApplied
- 如果RPC請求或者響應包含的任期T > currentTerm,將currentTerm設定為T並轉換為Follower
Followers
- 響應來自Leader和Candidate的RPC請求
- 如果在選舉超時週期內沒有收到AppendEntries的請求或者給Candidate投票,轉換為Candidate角色
Candidates
- 轉換為candidate角色,開始選舉:
- 遞增currentTerm
- 給自己投票
- 重置選舉時間
- 傳送RequestVote給其他所有節點
- 如果收到了大多數節點的選票,轉換為Leader節點
- 如果收到Leader節點的AppendEntries請求,轉換為Follower節點
- 如果選舉超時,重新開始新一輪的選舉
Leaders
- 一旦選舉完成:傳送心跳給所有節點;在空閒的週期內不斷髮送心跳保持Leader身份
- 如果收到客戶端的請求,將日誌追加到本地log,在日誌被應用到狀態機後響應給客戶端
- 如果對於一個跟隨者,最後日誌條目的索引值大於等於 nextIndex,那麼:傳送從 nextIndex 開始的所有日誌條目:
- 如果成功:更新相應跟隨者的 nextIndex 和 matchIndex
- 如果因為日誌不一致而失敗,減少 nextIndex 重試
- 如果存在一個滿足N > commitIndex的 N,並且大多數的matchIndex[i] ≥ N成立,並且log[N].term == currentTerm成立,那麼令commitIndex等於這個N
將在下一篇介紹Raft協議的Leader選舉和日誌複製,歡迎關注公眾號交流。


