
Mysql中使用JDBC流式查詢避免資料量過大導致OOM
阿新 • • 發佈:2018-12-22
一、前言
java 中MySQL JDBC 封裝了流式查詢操作,通過設定幾個引數,就可以避免一次返回資料過大導致 OOM。
二、如何使用
2.1 之前查詢
public void selectData(String sqlCmd) throws SQLException {
validate(sqlCmd);
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null; try {
conn = petadataSource.getConnection();
stmt = conn.prepareStatement(sqlCmd);
rs = stmt.executeQuery(); try 2.2 現在流式查詢
public void selectData(String sqlCmd,) throws SQLException {
validate(sqlCmd);
Connection conn = null 可知只是prepareStatement時候改變了引數,並且設定了PreparedStatement的fetchsize為Integer.MIN_VALUE。
三、 結果對比
對於同一個sqlCmd,同一批資料,使用兩種方式佔用記憶體對比如下:
- 非流式程式設計
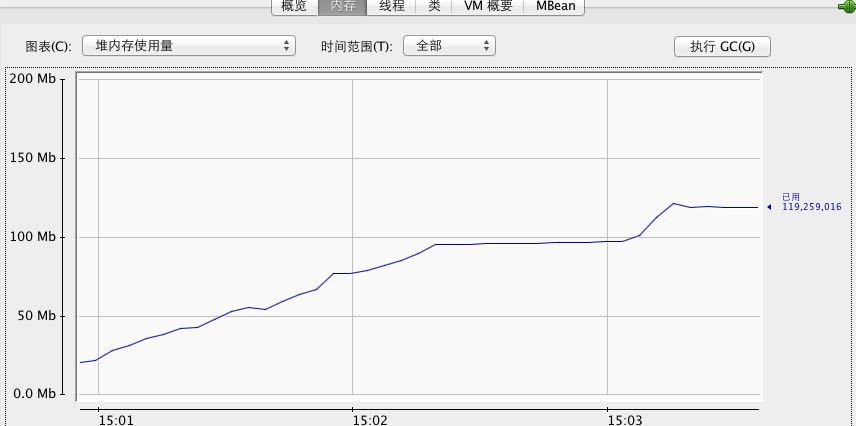
- 流式程式設計
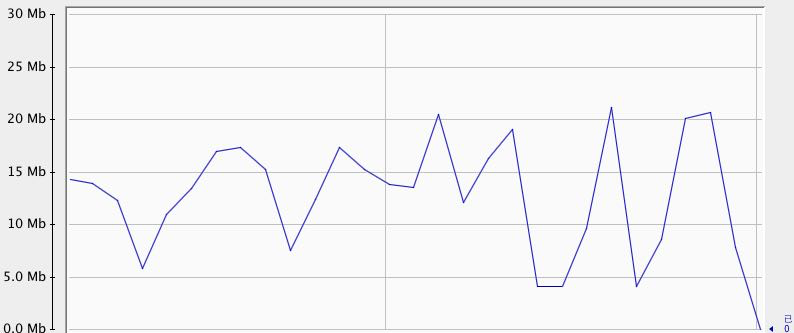
另外非流式方式由於是把符合條件的資料一下子全部加在到記憶體,並且由於資料量比較大,mysql準備資料的時間比較長,我測試情況下需要一分鐘才會返回結果到記憶體(資料量比較大),然後才能通過資料集訪問資料。
而流式方式是每次返回一個記錄到記憶體,所以佔用記憶體開銷比較小,並且呼叫後會馬上可以訪問資料集的資料。

