
springcloud坑之 feign 消費者呼叫生產者 資料量過大時報Request header is too large
這是由於tomcat限制了header的長度,如果你請求的資料量超過了預設的長度就會丟擲越界,
解決方法
1.springboot是內建tomcat的所以不能修改tomcat的檔案內容,在springboot的xxxx.yml加上
server:
#tomcat:
#max-http-post-size: -1
max-http-header-size: 4048576即可如果配置檔案型別為xxxx.propertis則
server.max-http-header-size=4048576
max-http-post-size2.修改tomcat中的server.xml
在此處加上
maxPostSize="8000000" <Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" maxPostSize="8000000"/>相關推薦
springcloud坑之 feign 消費者呼叫生產者 資料量過大時報Request header is too large
這是由於tomcat限制了header的長度,如果你請求的資料量超過了預設的長度就會丟擲越界,解決方法 1.springboot是內建tomcat的所以不能修改tomcat的檔案內容,在springboot的xxxx.yml加上server: #tomcat:
Feign請求中報錯:Request header is too large 的解決方案。
現在我們專案中都已遷入spring boot和spring cloud。 服務間呼叫現在都改成feign的呼叫方式,但是上次在實際使用過程中出現過:Request header is too large 的情況。 這裡重現下場景: 1,呼叫其他服務提供方的介面 2,POST請求,傳遞的引數包含資料較大 3,本
MySQL Insert資料量過大導致報錯 MySQL server has gone away
接手了同事的專案,其中有一個功能是儲存郵件模板(包含圖片),同事之前的做法是把圖片進行base64編碼然後存在mysql資料庫中(欄位型別為mediumtext)然後儲存三張圖片(大概400k)的時候報錯MySQL server has gone away 然後檢視官方文件https://dev.mysql
Mybatis中使用流式查詢避免資料量過大導致OOM
一、前言 前面介紹了裸露JDBC 方式使用流式程式設計,下面介紹下MYbatis中兩種使用流式查詢方法 二、Mybaits中MyBatisCursorItemReader的使用 2.1 配置 MyBatisCursorItemReader的注入 <bean id="myMyBa
Mysql中使用JDBC流式查詢避免資料量過大導致OOM
一、前言 java 中MySQL JDBC 封裝了流式查詢操作,通過設定幾個引數,就可以避免一次返回資料過大導致 OOM。 二、如何使用 2.1 之前查詢 public void selectData(String sqlCmd) throws SQLException { v
記kafka partition資料量過大導致不能正確重啟
某臺kafka伺服器負載過高,機器掛掉一段是時間後,kill掉佔用記憶體的程序,然後重啟kafka服務,但是一直不能完成啟動和資料同步,日誌如下fset 0 to broker BrokerEndPoint(11,192.168.207.79,9092)] ) (kafka
WCF入門(一)--Request Entity Too large 傳輸的資料量過大
通過WCF進行資料的查詢或者新增的時候,如果資料量過大,一般會報出如下的錯誤: 1、已超過傳入訊息(65536)的最大訊息大小配額。若要增加配額,請使用相應繫結元素上的MaxRe
struts2 資料傳輸問題---“POST方式提交資料量過大,在後臺接收不到資料”問題的解決
最近做用struts2做專案的時候,發現一個問題,就是當通過POST方式提交資料量過大,在後臺接收不到資料,後來通過檢視資料,發現tomcat預設傳輸最大的資料限制為2M,最後的解決辦法是設大tomcat的conf下的server.xml中8080Connector的max
關於資料量過大,且SQL已經不能再優化的檢視的解決辦法(二)
一般情況下在上篇文章的處理後,利用物化檢視,已經能夠解決複雜檢視的查詢效率了,但是有時候資料量是在過大,且檢視中使用了很多自定義的函式。這兩種情況單單是建物化檢視也提升不了效率。 第一,資料量過大,物化檢視的建立及其緩慢,而且由於由於是做資料介面,要求
java匯出excel資料量過大解決方案
@RequestMapping("/export") public void export(HttpServletRequest request, HttpServletResponse response, FullProcess fullProcess) { /
如何應對資料庫表資料量過大而導致的響應速度變慢
1.我們知道最直接最簡單的方法就是把該表的資料量變小,那麼把表資料變少有什麼辦法呢?最簡單最直接的方法就是再建立一張具有相同結構的資料表,建好表之後,再把不需要經常呼叫的資料放到該備用表中,當需要查詢的時候,再查該表,這種方法雖笨但很直接,我以oracle為例,oracle
springcloud入門之服務消費者Feign
之前就使用ribbon搭建了一個服務消費者,今天嘗試使用Feign搭建一個服務消費者專案。 Feign介紹 Feign是一個宣告式的web service客戶端,使用Feign搭建專案十分簡便,只需要建立一個介面並註解等幾個步驟就可以實現,具有可插拔
SpringCloud學習之feign
ice pin tro 分享 int 關於 security eve ket 一.關於feigin feigin是一種模板化,聲明式的http客戶端,feign可以通過註解綁定到接口上來簡化Http請求訪問。當然我們也可以在創建Feign對象時定制自定義解碼器(xml
SpringCloud(二)之feign和ribbon
SpringCloud(二)之feign和ribbon 1.ribbon ribbon的作用,如果像上篇一樣我們呼叫的話寫死固定的節點,這樣我們的服務還是一個單點呼叫。ribbon就是實現服務多個提供者之間的負載均衡的一個外掛。 整合ribbon a.匯入rib
RabbitMQ訊息佇列之二:消費者和生產者 Demo
在使用RabbitMQ之前,需要了解RabbitMQ的工作原理。 RabbitMQ的工作原理 RabbitMQ是訊息代理。從本質上說,它接受來自生產者的資訊,並將它們傳遞給消費者。在兩者之間,它可以根據你給它的路由,緩衝規則進行傳遞訊息。 示例圖
從零搭建一個SpringCloud專案之Feign搭建
# 從零搭建一個SpringCloud專案之Feign搭建 ## 工程簡述 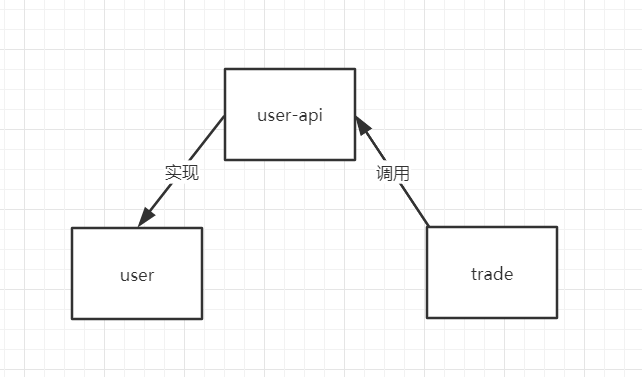 目的:實現trade服務通過feign呼叫
java爬坑之路(一)——編譯可以正常編譯,執行時報unsupported major.minor version 52.0
寫了一個很簡單的helloworld,編譯可以正常編譯,執行時報unsupported major.minor version 52.0錯誤。 java程式碼如下: 用javac Hello.java命令編譯時,是沒有問題的,用java Hello執行時,怎麼也執行不了 後
MySQL單表資料量過千萬,採坑優化記錄,完美解決方案
問題概述 使用阿里雲rds for MySQL資料庫(就是MySQL5.6版本),有個使用者上網記錄表6個月的資料量近2000萬,保留最近一年的資料量達到4000萬,查詢速度極慢,日常卡死。嚴重影響業務。 問題前提:老系統,當時設計系統的人大概是大學沒畢業,表設計和sql語句寫的不僅僅是垃圾
mysql查詢哪個表資料量最大
use information_schema;select table_name,table_rows from tables where table_schema='cargo_new' order by table_rows desc limit 3 -- cargo_new (選擇資料庫)
介面資料量太大,導致記憶體溢位,解決辦法
通常我們使用介面呼叫資料總是返回一段我們需要的資訊,或者是json 格式資訊,通過接收將資料儲存到程式當中,再對接收到的資料進行轉換成對應的模型格式 。目前遇到的問題是接收的資料量過於巨大,導致完整接收將導致記憶體溢位,無法進行接下去的工作 。 解決辦法: 我們將資料儲存到本地檔案 ,再通過