
乾貨 | Elasticsearch叢集黃色原因的終極探祕
1、Elasticsearch叢集不同顏色代表什麼?
綠色——最健康的狀態,代表所有的主分片和副本分片都可用;
黃色——所有的主分片可用,但是部分副本分片不可用;
紅色——部分主分片不可用。(此時執行查詢部分資料仍然可以查到,遇到這種情況,還是趕快解決比較好。
2、Elasticsearch 叢集顏色變黃色了要不要緊?
Elasticsearch叢集黃色代表:
- 分配了所有主分片,但至少缺少一個副本。
- 沒有資料丟失,因此搜尋結果仍將完整。
注意:您的高可用性在某種程度上會受到影響。
如果更多分片消失,您可能會丟失資料。 將黃色視為應該提示調查的警告。
3、Elasticsearch叢集健康狀態如何排查?
3.1 叢集狀態檢視
curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
{
"cluster_name" : "astrung",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 22,
"active_shards" : 22,
"relocating_shards" : 0,
"initializing_shards" 3.2 分片狀態檢視
curl -XGET 'http://localhost:9200/_cat/shards?v'
index shard prirep state docs store ip node
_river 0 p STARTED 2 8.1kb 192.168.1.3 One
_river 0 r UNASSIGNED
megacorp 4 3.3 檢視unsigned 的原因
GET /_cluster/allocation/explain3.4 檢視叢集中不同節點、不同索引的狀態
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason3.5 Head外掛直觀排查
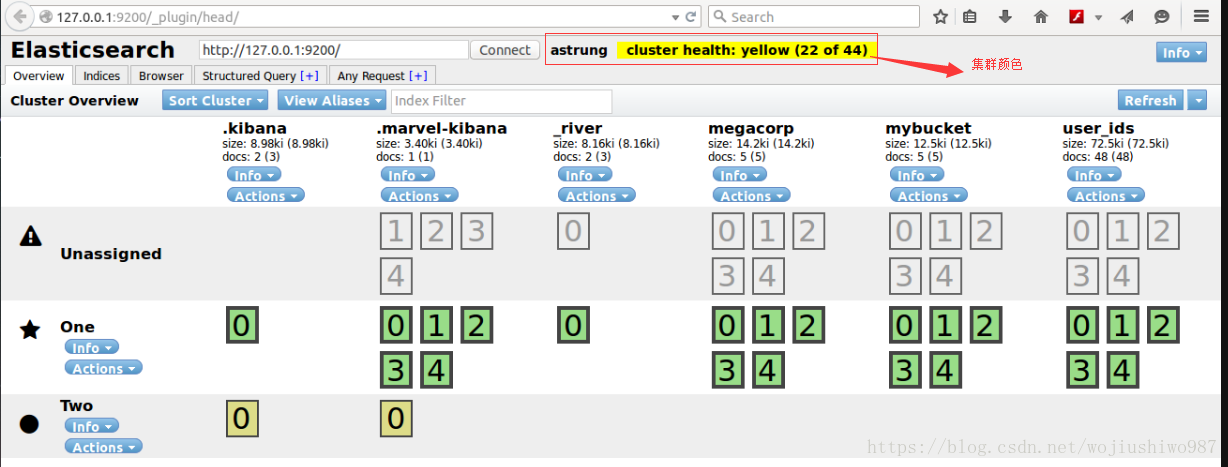
4、Elasticsearch叢集黃色的原因排查及解決方案
4.1 原因1:Elasticsearch採用預設配置(5分片,1副本),但實際只部署了單節點叢集。
由於只有一個節點,因此群集無法放置副本,因此處於黃色狀態。
elasticsearch 索引的預設配置如下:
index.number_of_shards:5
index.number_of_replicas:1解決方案如下:
您可以將副本計數降低到0或將第二個節點新增到群集,以便可以將主分片和副本分片安全地放在不同的節點上。
這樣做以後,如果您的節點崩潰,群集中的另一個節點將擁有該分片的副本。
(1)設定副本數為0,操作如下:
PUT /cs_indexs/_settings
{
"number_of_replicas": 0
}進行段合併,提升訪問效率,操作如下:
POST /cs_indexs/_forcemerge?max_num_segments=1
(2)不再物理擴充套件叢集,將後續所有的索引自動建立的副本設定為 0。
PUT /_template/index_defaults
{
"template": "*",
"settings": {
"number_of_replicas": 0
}
}4.2 原因2:Elasticsearch分配分片錯誤。
進一步可能的原因:您已經為叢集中的節點數過分分配了副本分片的數量,則分片將保持UNASSIGNED狀態。其錯誤碼為:ALLOCATION_FAILED。
解決方案如下:
reroute:重新路由命令允許手動更改群集中各個分片的分配。
核心操作如下:
POST /_cluster/reroute
{
"commands": [
{
"allocate_replica": {
"index": "cs_indexs",
"shard": 0, # 重新分配的分片(標記黃色的分片)
"node": "es-2"
}
}
]
}reroute擴充套件使用——可以顯式地將分片從一個節點移動到另一個節點,可以取消分配,
並且可以將未分配的分片顯式分配給特定節點。
舉例使用模板如下:
POST /_cluster/reroute
{
"commands" : [
{
"move" : {
"index" : "test", "shard" : 0,
"from_node" : "node1", "to_node" : "node2"
}
},
{
"allocate_replica" : {
"index" : "test", "shard" : 1,
"node" : "node3"
}
}
]
}其中:
1)move代表移動;
2)allocate_replica 代表重新分配;
3)cancel 代表取消;
4.3 磁碟使用過載。
原因3:磁碟使用超過設定百分比85%。
cluster.routing.allocation.disk.watermark.low——控制磁碟使用的低水位線。 它預設為85%,這意味著Elasticsearch不會將分片分配給使用磁碟超過85%的節點。 它也可以設定為絕對位元組值(如500mb),以防止Elasticsearch在小於指定的可用空間量時分配分片。
解決方案:
(1)檢視磁碟空間是否超過85%。
[root@localhost home]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/xvda1 1014M 165M 849M 17% /boot
/dev/mapper/cl-home 694G 597G 98G 86% /home(2)刪除不必要的索引,以釋放更多的空間。
DELETE cs_indexs4.4 磁碟路徑許可權問題。
原因4:磁碟路徑許可權問題。安全起見,預設Elasticsearch非root賬戶和啟動。
相關的Elasticsearch資料路徑也是非root許可權。
解決方案:
去資料儲存路徑排查許可權,或者在data的最外層設定:
chown -R elasticsearch:elasticsearch data參考:

打造Elasticsearch基礎、進階、實戰第一公眾號!