
談一談Elasticsearch的叢集部署
Elasticsearch天生就支援分散式部署,通過叢集部署可以提高系統的可用性。本文重點談一談Elasticsearch的叢集節點相關問題,搞清楚這些是進行Elasticsearch叢集部署和拓撲結構設計的前提。關於如何配置叢集的配置檔案不會在本文中提及。(本文寫作背景是Elasticsearch 2.3)
節點型別
1. 候選主節點(Master-eligible node)
一個節點啟動後,就會使用Zen Discovery機制去尋找叢集中的其他節點,並與之建立連線。叢集中會從候選主節點中選舉出一個主節點,主節點負責建立索引、刪除索引、分配分片、追蹤叢集中的節點狀態等工作。Elasticsearch中的主節點的工作量相對較輕,使用者的請求可以發往任何一個節點,由該節點負責分發和返回結果,而不需要經過主節點轉發。
正常情況下,叢集中的所有節點,應該對主節點的選擇是一致的,即一個叢集中只有一個選舉出來的主節點。然而,在某些情況下,比如網路通訊出現問題、主節點因為負載過大停止響應等等,就會導致重新選舉主節點,此時可能會出現叢集中有多個主節點的現象,即節點對叢集狀態的認知不一致,稱之為腦裂現象
候選主節點的設定方法是設定node.mater為true,預設情況下,node.mater和node.data的值都為true,即該節點既可以做候選主節點也可以做資料節點。由於資料節點承載了資料的操作,負載通常都很高,所以隨著叢集的擴大,建議將二者分離,設定專用的候選主節點。當我們設定node.data為false,就將節點設定為專用的候選主節點了。
node.master = true
node.data = false
2. 資料節點(Data node)
資料節點負責資料的儲存和相關具體操作,比如CRUD、搜尋、聚合。所以,資料節點對機器配置要求比較高,首先需要有足夠的磁碟空間來儲存資料,其次資料操作對系統CPU、Memory和IO的效能消耗都很大。通常隨著叢集的擴大,需要增加更多的資料節點來提高可用性。
前面提到預設情況下節點既可以做候選主節點也可以做資料節點,但是資料節點的負載較重,所以需要考慮將二者分離開,設定專用的資料節點,避免因資料節點負載重導致主節點不響應。
node.master = false node.data = true
3. 客戶端節點(Client node)
按照官方的介紹,客戶端節點就是既不做候選主節點也不做資料節點的節點,只負責請求的分發、彙總等等,也就是下面要說到的協調節點的角色。這樣的工作,其實任何一個節點都可以完成,單獨增加這樣的節點更多是為了負載均衡。
node.master = false
node.data = false
4. 協調節點(Coordinating node)
協調節點,是一種角色,而不是真實的Elasticsearch的節點,你沒有辦法通過配置項來配置哪個節點為協調節點。叢集中的任何節點,都可以充當協調節點的角色。當一個節點A收到使用者的查詢請求後,會把查詢子句分發到其它的節點,然後合併各個節點返回的查詢結果,最後返回一個完整的資料集給使用者。在這個過程中,節點A扮演的就是協調節點的角色。毫無疑問,協調節點會對CPU、Memory要求比較高。
分片與叢集狀態
分片(Shard),是Elasticsearch中的最小儲存單元。一個索引(Index)中的資料通常會分散儲存在多個分片中,而這些分片可能在同一臺機器,也可能分散在多臺機器中。這樣做的優勢是有利於水平擴充套件,解決單臺機器磁碟空間和效能有限的問題,試想一下如果有幾十TB的資料都儲存同一臺機器,那麼儲存空間和訪問時的效能消耗都是問題。
預設情況下,Elasticsearch會為每個索引分配5個分片,但是這並不代表你必須使用5個分片,同時也不說分片越多效能就越好。一切都取決對你的資料量的評估和權衡。雖然跨分片查詢是並行的,但是請求分發、結果合併都是需要消耗效能和時間的,所以在資料量較小的情況下,將資料分散到多個分片中反而會降低效率。如果說一定要給一個數據的話,筆者現在的每個分片資料量大概在20GB左右。
關於多分片與多索引的問題。一個索引可以有多個分片來完成儲存,但是主分片的數量是在索引建立時就指定好的,且無法修改,所以儘量不要只為資料儲存建立一個索引,否則後面資料膨脹時就無法調整了。筆者的建議是對於同一型別的資料,根據時間來分拆索引,比如一週建一個索引,具體取決於資料增長速度。
上面說的是主分片(Primary Shard),為了提高服務可靠性和容災能力,通常還會分配複製分片(Replica Shard)來增加資料冗餘性。比如設定複製分片的數量為1時,就會對每個主分片做一個備份。
通過API( http://localhost:9200/_cluster/health?pretty )可以檢視叢集的狀態,通常叢集的狀態分為三種:
- Red,表示有主分片沒有分配,某些資料不可用。
- Yellow,表示主分片都已分配,資料都可用,但是有複製分片沒有分配。
- Green,表示主分片和複製分片都已分配,一切正常。
部署拓撲
最後,來看兩個叢集部署的拓撲圖,這裡我們不考慮單個節點的調優。拓撲圖一是一個簡單的叢集部署,適用於資料量較小的場景。叢集中有三個節點,三個都是候選主節點,因此我們可以設定最少可工作候選主節點個數為2。節點1和2同時作為資料節點,兩個節點的資料相互備份。這樣的部署結構在擴充套件過程中,通常是先根據需要逐步加入專用的資料節點,最後考慮將資料節點和候選主節點分離,也就發展為了拓撲圖二的結構。在拓撲圖二中,有三個專用的候選主節點,用來做叢集狀態維護,資料節點根據需要進行增加,注意只增加專用的資料節點即可。
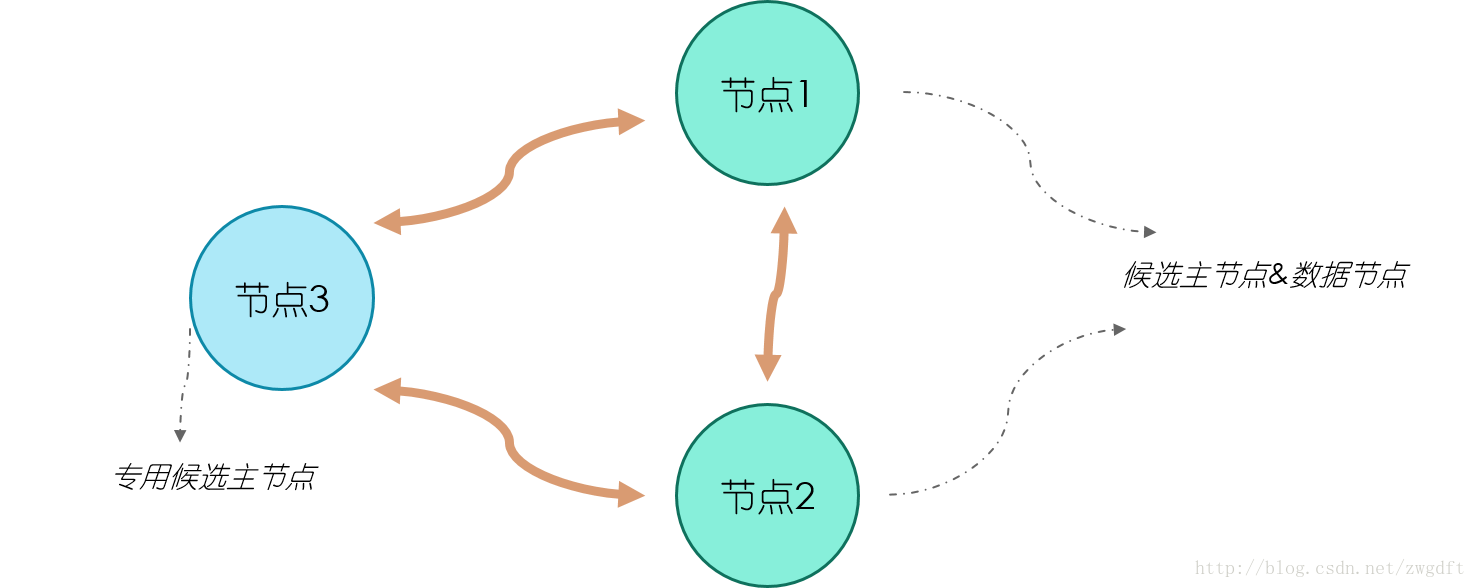 拓撲圖一
拓撲圖一
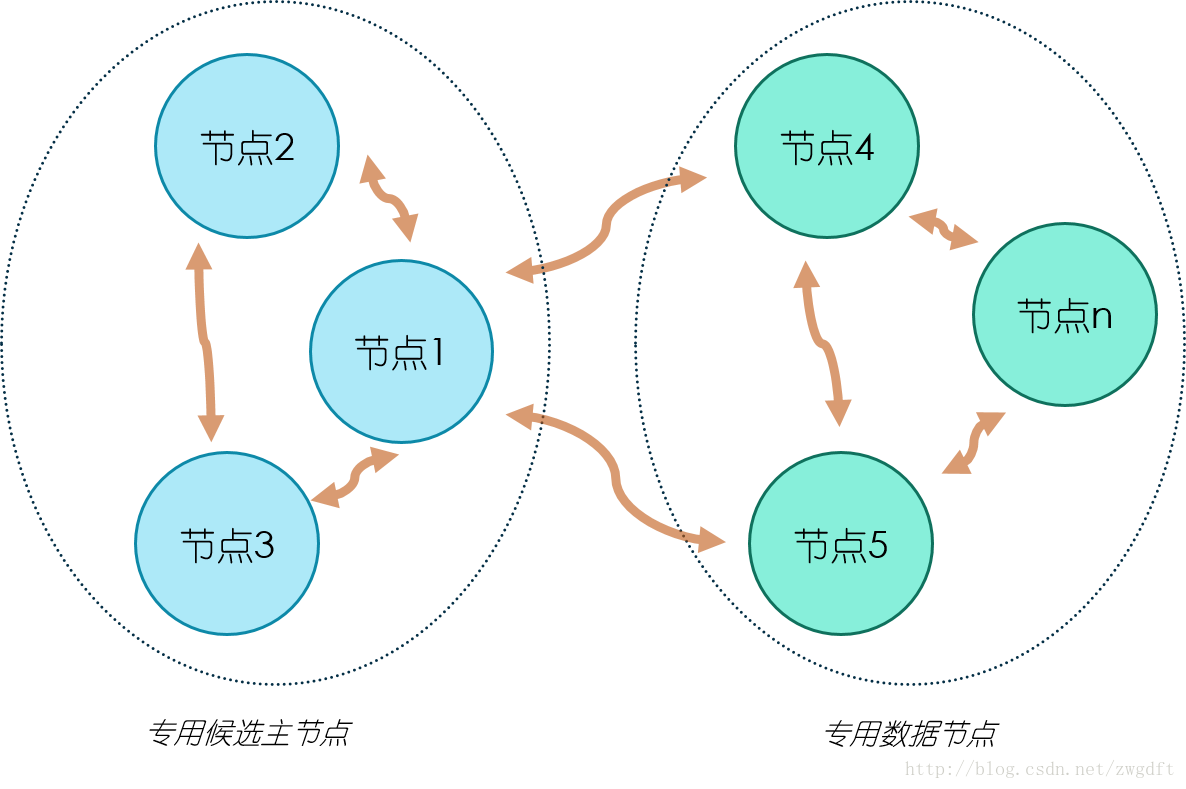 拓撲圖二
拓撲圖二