
47.Elasticsearch的使用場景深入詳解(Elasticsearch實戰篇)
瞭解了ES的使用場景,ES的研究、使用、推廣才更有價值和意義。
1、場景—:使用Elasticsearch作為主要的後端
傳統專案中,搜尋引擎是部署在成熟的資料儲存的頂部,以提供快速且相關的搜尋能力。這是因為早期的搜尋引擎不能提供耐用的儲存或其他經常需要的功能,如統計。 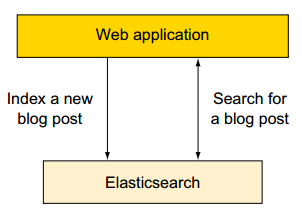
Elasticsearch是提供持久儲存、統計等多項功能的現代搜尋引擎。
如果你開始一個新專案,我們建議您考慮使用Elasticsearch作為唯一的資料儲存,以幫助保持你的設計儘可能簡單。
此種場景不支援包含頻繁更新、事務(transaction)的操作。
舉例如下:新建一個部落格系統使用es作為儲存。
1)我們可以向ES提交新的博文;
2)使用ES檢索、搜尋、統計資料。
ES作為儲存的優勢:
如果一臺伺服器出現故障時會發生什麼?你可以通過複製 資料到不同的伺服器以達到容錯的目的。
注意:
整體架構設計時,需要我們權衡是否有必要增加額外的儲存。
2、場景二:在現有系統中增加elasticsearch
由於ES不能提供儲存的所有功能,一些場景下需要在現有系統資料儲存的基礎上新增ES支援。 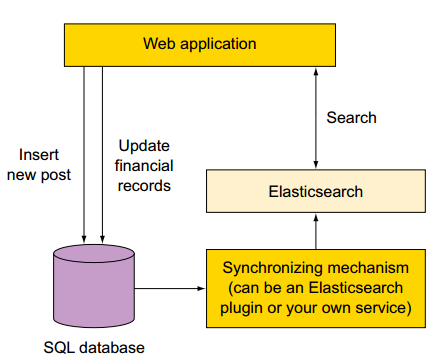
舉例1:ES不支援事務、複雜的關係(至少1.X版本不支援,2.X有改善,但支援的仍然不好),如果你的系統中需要上述特徵的支援,需要考慮在原有架構、原有儲存的基礎上的新增ES的支援。
舉例2:如果你已經有一個在執行的複雜的系統,你的需求之一是在現有系統中新增檢索服務。一種非常冒險的方式是重構系統以支援ES。而相對安全的方式是:將ES作為新的元件新增到現有系統中。
如果你使用瞭如下圖所示的SQL資料庫和ES儲存,你需要找到一種方式使得兩儲存之間實時同步。需要根據資料的組成、資料庫選擇對應的同步外掛。可供選擇的外掛包括:
1)mysql、oracle選擇 logstash-input-jdbc 外掛。
2)mongo選擇 mongo-connector工具。
假設你的線上零售商店的產品資訊儲存在SQL資料庫中。 為了快速且相關的搜尋,你安裝Elasticsearch。
為了索引資料,您需要部署一個同步機制,該同步機制可以是Elasticsearch外掛或你建立一個自定義的服務。此同步機制可以將對應於每個產品的所有資料和索引都儲存在Elasticsearch,每個產品作為一個document儲存(這裡的document相當於關係型資料庫中的一行/row資料)。
當在該網頁上的搜尋條件中輸入“使用者的型別”,店面網路應用程式通過Elasticsearch查詢該資訊。 Elasticsearch返回符合標準的產品documents,並根據你喜歡的方式來分類文件。 排序可以根據每個產品的被搜尋次數所得到的相關分數,或任何儲存在產品document資訊,例如:最新最近加入的產品、平均得分,或者是那些插入或更新資訊。 所以你可以只使用Elasticsearch處理搜尋。這取決於同步機制來保持Elasticsearch獲取最新變化。
3、場景三:使用elasticsearch和現有的工具
在一些使用情況下,您不必寫一行程式碼就能通過elasticssearch完成一項工作。很多工具都可以與Elasticsearch一起工作,所以你不必到你從頭開始編寫。
例如,假設要部署一個大規模的日誌框架儲存,搜尋,並分析了大量的事件。
如圖下圖,處理日誌和輸出到Elasticsearch,您可以使用日誌記錄工具,如rsyslog(www.rsyslog.com),Logstash(www.elastic.co/products/logstash),或Apache Flume(http://flume.apache.org)。
搜尋和視覺化介面分析這些日誌,你可以使用Kibana(www.elastic.co/產品/ kibana)。

為什麼那麼多工具適配Elasticsearch?主要原因如下:
1)Elasticsearch是開源的。
2)Elasticsearch提供了JAVA API介面。
3)Elasticsearch提供了RESTful API介面(不管程式用什麼語言開發,任何程式都可以訪問)
4)更重要的是,REST請求和應答是典型的JSON(JavaScript物件 符號)格式。通常情況下,一個REST請求包含一個JSON檔案,其回覆都 也是一個JSON檔案。