
CNN目標檢測(二):YOLO
↑↑↑↑目錄在這裡↑↑↑↑
縮排YOLO全稱You Only Look Once: Unified, Real-Time Object Detection,是在CVPR2016提出的一種目標檢測演算法,核心思想是將目標檢測轉化為迴歸問題求解,並基於一個單獨的end-to-end網路,完成從原始影象的輸入到物體位置和類別的輸出。YOLO與Faster RCNN有以下區別:
- Faster RCNN將目標檢測分解為分類為題和迴歸問題分別求解:首先採用獨立的RPN網路專門求取region proposal,即計算圖1中的 P(objetness);然後對利用bounding box regression對提取的region proposal進行位置修正,即計算圖1中的Box offsets(迴歸問題);最後採用softmax進行分類(分類問題)。
- YOLO將物體檢測作為一個迴歸問題進行求解:輸入影象經過一次網路,便能得到影象中所有物體的位置和其所屬類別及相應的置信概率。
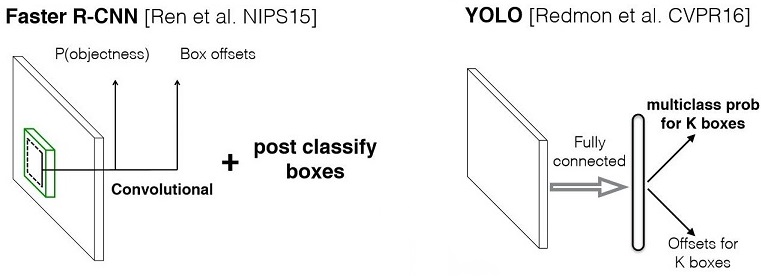
縮排可以看出,YOLO將整個檢測問題整合為一個迴歸問題,使得網路結構簡單,檢測速度大大加快;由於網路沒有分支,所以訓練也只需要一次即可完成。這種“把檢測轉化為迴歸問題”的思路非常有效,之後的很多檢測演算法(包括SSD)都借鑑了此思路。
1. YOLO網路結構
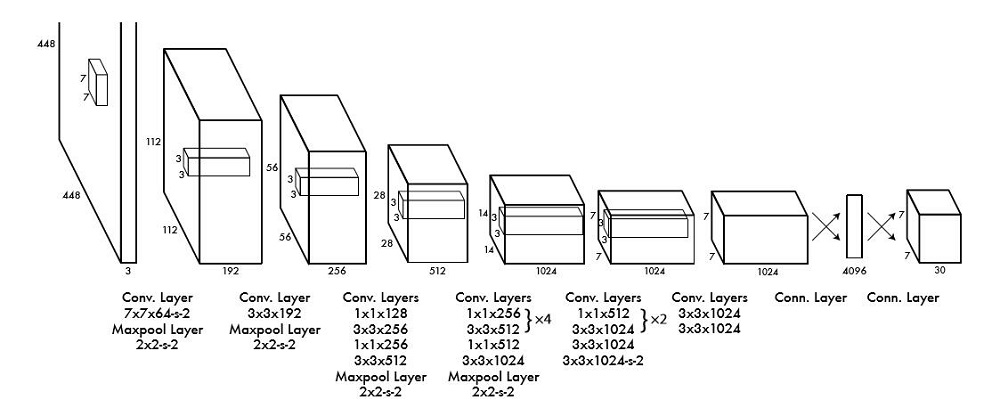
縮排上圖2中展示了YOLO的網路結構。相比Faster RCNN,YOLO結構簡單而,網路中只包含conv,relu,pooling和全連線層,以及最後用來綜合資訊的detect層。其中使用了1x1卷積用於多通道資訊融合(若不明白1x1卷積請檢視上一篇Faster RCNN文章)。
2. YOLO核心思想
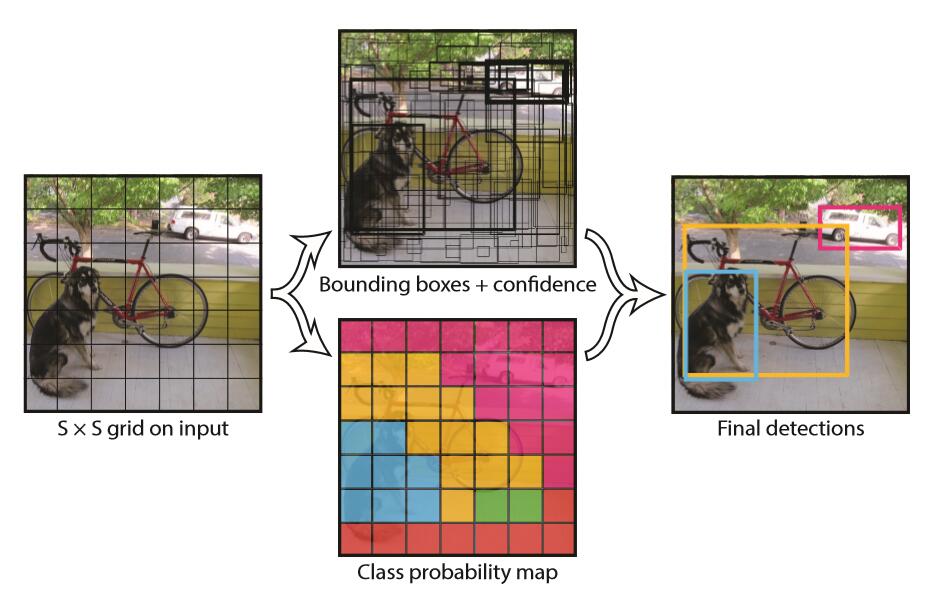
圖3
YOLO的工作過程分為以下幾個過程:
(1) 將原圖劃分為SxS的網格。如果一個目標的中心落入某個格子,這個格子就負責檢測該目標。
(2) 每個網格要預測B個bounding boxes,以及C個類別概率Pr(classi|object)。這裡解釋一下,C是網路分類總數,由訓練時決定。在作者給出的demo中C=20,包含以下類別:
人person
鳥bird、貓cat、牛cow、狗dog、馬horse、羊sheep
飛機aeroplane、自行車bicycle、船boat、巴士bus、汽車car、摩托車motorbike、火車train
瓶子bottle、椅子chair、餐桌dining table、盆景potted plant、沙發sofa、顯示器tv/monitor
在YOLO中,每個格子只有一個C類別,即相當於忽略了B個bounding boxes,每個格子只判斷一次類別,這樣做非常簡單粗暴。
(3) 每個bounding box除了要回歸自身的位置之外,還要附帶預測一個confidence值。這個confidence代表了所預測的box中含有目標的置信度和這個bounding box預測的有多準兩重資訊:
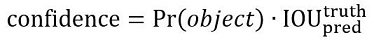
如果有目標落中心在格子裡Pr(Object)=1;否則Pr(Object)=0。 第二項是預測的bounding box和實際的ground truth之間的IOU。
縮排所以,每個bounding box都包含了5個預測量:(x, y, w, h, confidence),其中(x, y)代表預測box相對於格子的中心,(w, h)為預測box相對於圖片的width和height比例,confidence就是上述置信度。需要說明,這裡的x, y, w和h都是經過歸一化的,之後有解釋。
(4) 由於輸入影象被分為SxS網格,每個網格包括5個預測量:(x, y, w, h, confidence)和一個C類,所以網路輸出是SxSx(5xB+C)大小
(5) 在檢測目標的時候,每個網格預測的類別條件概率和bounding box預測的confidence資訊相乘,就得到每個bounding box的class-specific confidence score:

顯然這個class-specific confidence score既包含了bounding box最終屬於哪個類別的概率,又包含了bounding box位置的準確度。最後設定一個閾值與class-specific confidence score對比,過濾掉score低於閾值的boxes,然後對score高於閾值的boxes進行非極大值抑制(NMS, non-maximum suppression)後得到最終的檢測框體。
3. YOLO中的Bounding Box Normalization
縮排YOLO在實現中有一個重要細節,即對bounding box的座標(x, y, w, h)進行了normalization,以便進行迴歸。作者認為這是一個非常重要的細節。在原文2.2 Traing節中有如下一段:
Our final layer predicts both class probabilities and bounding box coordinates.
We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1.
We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.
縮排接下來分析一下到底如何實現。
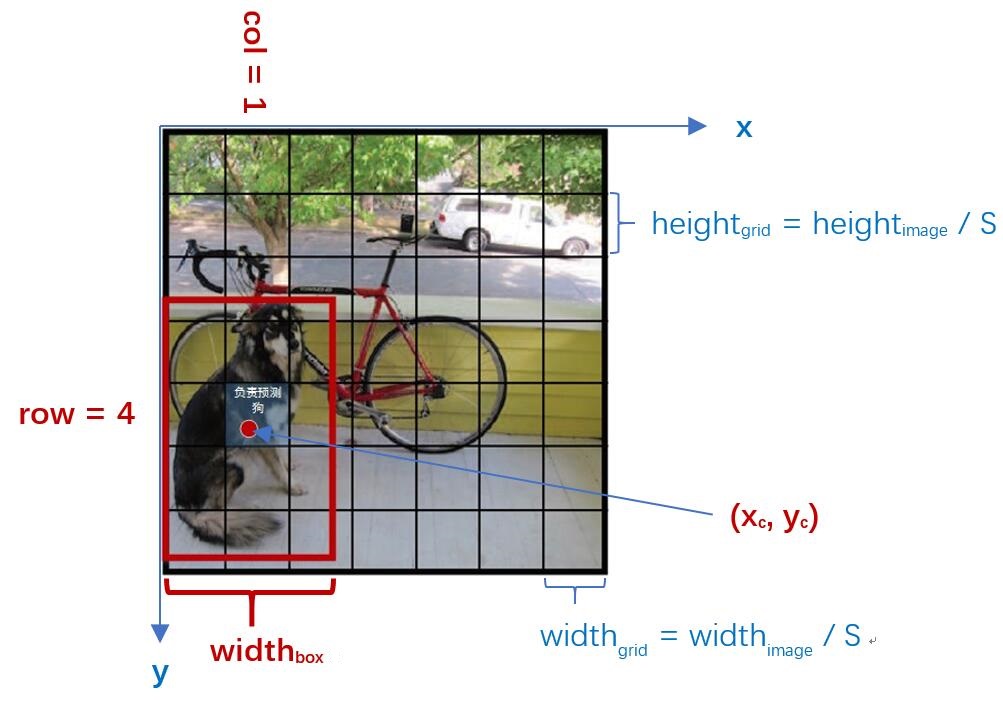
圖4 SxS網格與bounding box關係(圖中S=7,row=4且col=1)
縮排如圖4,在YOLO中輸入影象被分為SxS網格。假設有一個bounding box(如圖4紅框),其中心剛好落在了(row,col)網格中,則這個網格需要負責預測整個紅框中的dog目標。假設影象的寬為widthimage,高為heightimage;紅框中心在(xc,yc),寬為widthbox,高為heightbox那麼:
(1) 對於bounding box的寬和高做如下normalization,使得輸出寬高介於0~1:

(2) 使用(row, col)網格的offset歸一化bounding box的中心座標:
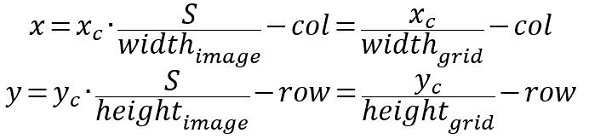
經過上述公式得到的normalization的(x, y, w, h),再加之前提到的confidence,共同組成了一個真正在網路中用於迴歸的bounding box;而當網路在Test階段(x, y, w, h)經過反向解碼又可得到目標在影象座標系的框,解碼程式碼在darknet detection_layer.c中的get_detection_boxes()函式,關鍵部分如下:
- boxes[index].x = (predictions[box_index + 0] + col) / l.side * w;
- boxes[index].y = (predictions[box_index + 1] + row) / l.side * h;
- boxes[index].w = pow(predictions[box_index + 2], (l.sqrt?2:1)) * w;
- boxes[index].h = pow(predictions[box_index + 3], (l.sqrt?2:1)) * h;
4. YOLO訓練過程
縮排對於任何一種網路,loss都是非常重要的,直接決定網路效果的好壞。YOLO的Loss函式設計時主要考慮了以下3個方面
(1) bounding box的(x, y, w, h)的座標預測誤差。
縮排在檢測演算法的實際使用中,一般都有這種經驗:對不同大小的bounding box預測中,相比於大box大小預測偏一點,小box大小測偏一點肯定更不能被忍受。所以在Loss中同等對待大小不同的box是不合理的。為了解決這個問題,作者用了一個比較取巧的辦法,即對w和h求平方根進行迴歸。從後續效果來看,這樣做很有效,但是也沒有完全解決問題。
(2) bounding box的confidence預測誤差
縮排由於絕大部分網格中不包含目標,導致絕大部分box的confidence=0,所以在設計confidence誤差時同等對待包含目標和不包含目標的box也是不合理的,否則會導致模型不穩定。作者在不含object的box的confidence預測誤差中乘以懲罰權重λnoobj=0.5。
縮排除此之外,同等對待4個值(x, y, w, h)的座標預測誤差與1個值的conference預測誤差也不合理,所以作者在座標預測誤差誤差之前乘以權重λcoord=5(至於為什麼是5而不是4,我也不知道T_T)。
(3) 分類預測誤差
縮排即每個box屬於什麼類別,需要注意一個網格只預測一次類別,即預設每個網格中的所有B個bounding box都是同一類。
所以,YOLO的最終誤差為下:
Loss = λcoord * 座標預測誤差 + (含object的box confidence預測誤差 + λnoobj * 不含object的box confidence預測誤差) + 類別預測誤差
=

-------------------------------------------------------下面是一點參考內容--------------------------------------------------------
縮排在各種常用框架中實現網路中一般需要完成forward與backward過程,forward函式只需依照Loss編碼即可,而backward函式簡需要計算殘差delta。這裡單解釋一下YOLO的負反饋,即backward的實現方法。在UFLDL教程中網路正向傳播方式定義為:
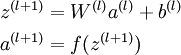
而最後一層反向傳播殘差定義為:
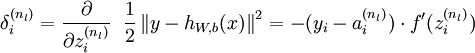
對於YOLO來說,最後一層是detection_layer,而倒數第二層是connected_layer(全連線層),之間沒有ReLU層,即相當於最後一層的啟用函式為:

那麼,對於detection_layer的殘差就變為:
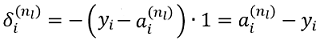
只需計算每一項的引數訓練目標值與網路輸出值之差,反向回傳即可,與程式碼對應。其他細節讀者請自行分析程式碼,不再介紹。
5. 結果分析
縮排在論文中,作者給出了YOLO與Fast RCNN檢測結果對比,如下圖。YOLO對背景的誤判率(4.75%)比Fast RCNN的誤判率(13.6%)低很多。但是YOLO的定位準確率較差,佔總誤差比例的19.0%,而fast rcnn僅為8.6%。這說明了YOLO中把檢測轉化為迴歸的思路有較好的precision,但是bounding box的定位方法還需要進一步改進。

縮排綜上所述,YOLO有如下特點:
- 快。YOLO將物體檢測作為迴歸問題進行求解,整個檢測網路pipeline簡單,且訓練只需一次完成。
- 背景誤檢率低。YOLO在訓練和推理過程中能“看到”整張影象的整體資訊,而基於region proposal的物體檢測方法(如Fast RCNN)在檢測過程中,只“看到”候選框內的區域性影象資訊。因此,若當影象背景(非物體)中的部分資料被包含在候選框中送入檢測網路進行檢測時,容易被誤檢測成物體[1]。
- 識別物體位置精準性差,√w和√h策略並沒有完全解決location準確度問題。
- 召回率低,尤其是對小目標。
----------------------------------------------------------------------
參考文獻:
[1] YOLO詳解,趙麗麗, https://zhuanlan.zhihu.com/p/25236464
[2] 論文閱讀筆記:You Only Look Once: Unified, Real-Time Object Detection,tangwei2014,http://blog.csdn.NET/tangwei2014/article/details/5091531