
驅動開發基礎 -- CPU中的cache結構以及cache一致性
一. 引子
在多執行緒環境中,經常會有一些計數操作,用來統計線上服務的一些qps、平均延時、error等。為了完成這些統計,可以實現一個多執行緒環境下的計數器類庫,方便記錄和檢視使用者程式中的各類數值。在實現這個計數器類庫時,可以利用thread local儲存來避免cache bouncing,從而提高效率。注意,這種實現方式的本質是把寫時的競爭轉移到了讀:讀得合併所有寫過的執行緒中的資料,而不可避免地變慢了。當你讀寫都很頻繁並得基於數值做一些邏輯判斷時,你不應該用前述的實現方式。那麼,cache bouncing是什麼?下面詳細說明一下。
二. 什麼是cache bouncing?
為了以較低的成本大幅提高效能,現代CPU都有cache。cpu cache已經發展到了三級快取結構,基本上現在買的個人電腦都是L3結構。其中L1和L2cache為每個核獨有,L3則所有核共享。為了保證所有的核看到正確的記憶體資料,一個核在寫入自己的L1 cache後,CPU會執行Cache一致性演算法把對應的cacheline(一般是64位元組)同步到其他核。這個過程並不很快,是微秒級的,相比之下寫入L1 cache只需要若干納秒。當很多執行緒在頻繁修改某個欄位時,這個欄位所在的cacheline被不停地同步到不同的核上,就像在核間彈來彈去,這個現象就叫做cache bouncing。由於實現cache一致性往往有硬體鎖,cache bouncing是一種隱式的的全域性競爭。
cache bouncing使訪問頻繁修改的變數的開銷陡增,甚至還會使訪問同一個cacheline中不常修改的變數也變慢,這個現象是false sharing。按cacheline對齊能避免false sharing,但在某些情況下,我們甚至還能避免修改“必須”修改的變數。當很多執行緒都在累加一個計數器時,我們讓每個執行緒累加私有的變數而不參與全域性競爭,在讀取時我們累加所有執行緒的私有變數。雖然讀比之前慢多了,但由於這類計數器的讀多為低頻展現,慢點無所謂。而寫就快多了,從微秒到納秒,幾百倍的差距。
三. cache
1. cache的意義
為什麼需要CPU cache?因為CPU的頻率太快了,快到主存跟不上,這樣在處理器時鐘週期內,CPU常常需要等待主存,浪費資源。所以cache的出現,是為了緩解CPU和記憶體之間速度的不匹配問題(結構:cpu -> cache -> memory)。
CPU cache有什麼意義?cache的容量遠遠小於主存,因此出現cache miss在所難免,既然cache不能包含CPU所需要的所有資料,那麼cache的存在真的有意義嗎?當然是有意義的——區域性性原理。
A. 時間區域性性:如果某個資料被訪問,那麼在不久的將來它很可能被再次訪問;
B. 空間區域性性:如果某個資料被訪問,那麼與它相鄰的資料很快也可能被訪問;
2. cache和暫存器
儲存器的三個效能指標——速度、容量和每位價格——導致了計算機組成中儲存器的多級層次結構,其中主要是快取和主存、主存和磁碟的結構。那麼在主存之上,cache和暫存器之間的關係是?
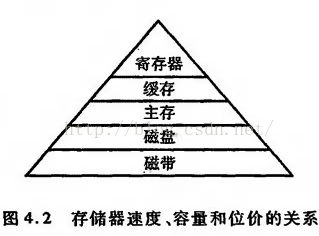
舉個例子,當你在思考一個問題的時候,暫存器存放的是你當前正在思考的內容,cache存放的是與該問題相關的記憶,主存則存放無論與該問題是否有關的所有記憶,所以,暫存器存放的是當前CPU執行的資料,而cache則快取與該資料相關的部分資料,因此只要保證了cache的一致性,那麼暫存器拿到的資料也必然具備一致性。
四. CPU cache結構
1. 單核CPU cache結構
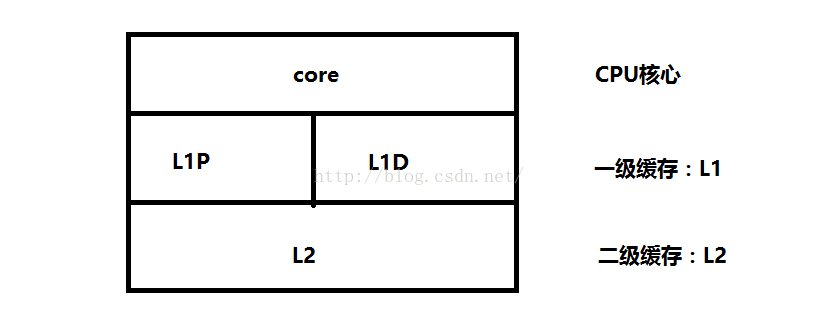
在單核CPU結構中,為了緩解CPU指令流水中cycle衝突,L1分成了指令(L1P)和資料(L1D)兩部分,而L2則是指令和資料共存。
2. 多核CPU cache結構
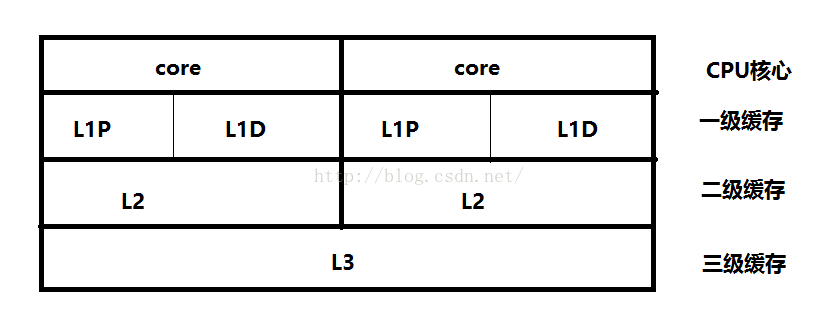
多核CPU的結構與單核相似,但是多了所有CPU共享的L3三級快取。在多核CPU的結構中,L1和L2是CPU私有的,L3則是所有CPU核心共享的。
五. MESI(快取一致性)
快取一致性:用於保證多個CPU cache之間快取共享資料的一致。
至於MESI,則是快取一致性協議中的一個,到底怎麼實現,還是得看具體的處理器指令集。
1. cache的寫方式
cache的寫操作方式可以追溯到大學教程《計算機組成原理》一書。
A. write through(寫通):每次CPU修改了cache中的內容,立即更新到記憶體,也就意味著每次CPU寫共享資料,都會導致匯流排事務,因此這種方式常常會引起匯流排事務的競爭,高一致性,但是效率非常低;
B. write back(寫回):每次CPU修改了cache中的資料,不會立即更新到記憶體,而是等到cache line在某一個必須或合適的時機才會更新到記憶體中;
無論是寫通還是寫回,在多執行緒環境下都需要處理快取cache一致性問題。為了保證快取一致性,處理器又提供了寫失效(write invalidate)和寫更新(write update)兩個操作來保證cache一致性。
寫失效:當一個CPU修改了資料,如果其他CPU有該資料,則通知其為無效;
寫更新:當一個CPU修改了資料,如果其他CPU有該資料,則通知其跟新資料;
寫更新會導致大量的更新操作,因此在MESI協議中,採取的是寫失效(即MESI中的I:ivalid,如果採用的是寫更新,那麼就不是MESI協議了,而是MESU協議)。
2. cache line

cache line是cache與記憶體資料交換的最小單位,根據作業系統一般是32byte或64byte。在MESI協議中,狀態可以是M、E、S、I,地址則是cache line中對映的記憶體地址,資料則是從記憶體中讀取的資料。
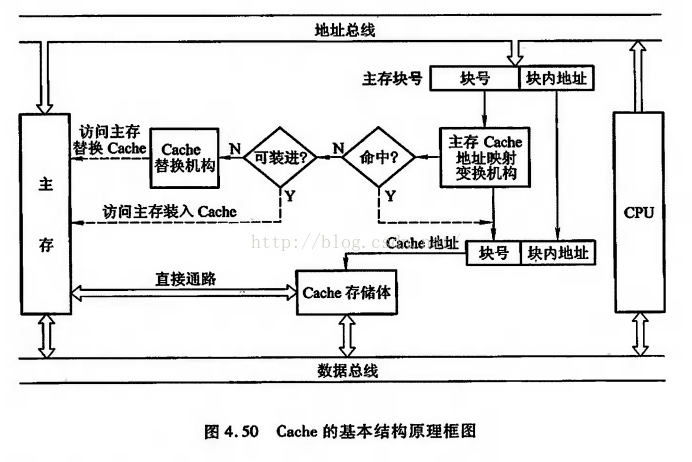
工作方式:當CPU從cache中讀取資料的時候,會比較地址是否相同,如果相同則檢查cache line的狀態,再決定該資料是否有效,無效則從主存中獲取資料,發起一次RR(remote read);
工作效率:當CPU能夠從cache中拿到有效資料的時候,消耗幾個CPU cycle,如果發生cache miss,則會消耗幾十上百個CPU cycle;
cache的工作原理以及在主機板上的結構如下兩圖所示:
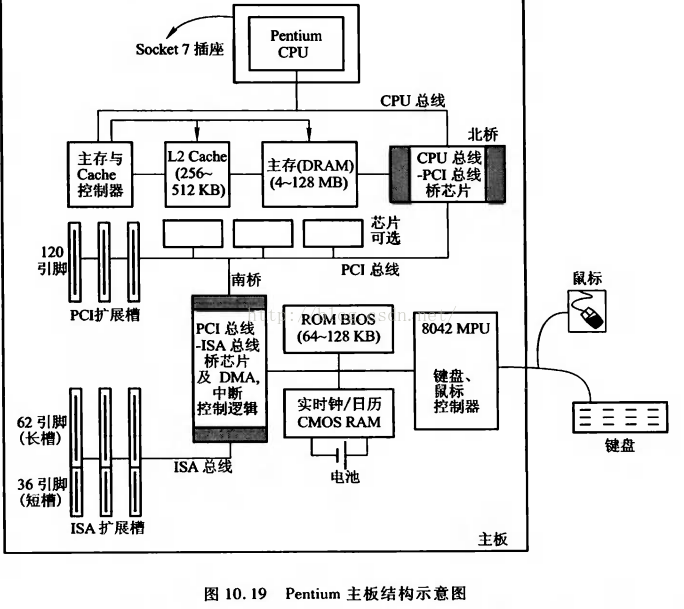
3. 狀態介紹
MESI協議將cache line的狀態分成modify、exclusive、shared、invalid,分別是修改、獨佔、共享和失效。
modify:當前CPU cache擁有最新資料(最新的cache line),其他CPU擁有失效資料(cache line的狀態是invalid),雖然當前CPU中的資料和主存是不一致的,但是以當前CPU的資料為準;
exclusive:只有當前CPU中有資料,其他CPU中沒有改資料,當前CPU的資料和主存中的資料是一致的;
shared:當前CPU和其他CPU中都有共同資料,並且和主存中的資料一致;
invalid:當前CPU中的資料失效,資料應該從主存中獲取,其他CPU中可能有資料也可能無資料,當前CPU中的資料和主存被認為是不一致的;
對於invalid而言,在MESI協議中採取的是寫失效(write invalidate)。
4. cache操作
MESI協議中,每個cache的控制器不僅知道自己的操作(local read和local write),通過監聽也知道其他CPU中cache的操作(remote read和remote write)。對於自己本地快取有的資料,CPU僅需要發起local操作,否則發起remote操作,從主存中讀取資料,cache控制器通過匯流排監聽,僅能夠知道其他CPU發起的remote操作,但是如果local操作會導致資料不一致性,cache控制器會通知其他CPU的cache控制器修改狀態。
local read(LR):讀本地cache中的資料;
local write(LW):將資料寫到本地cache;
remote read(RR):讀取記憶體中的資料;
remote write(RW):將資料寫通到主存;
5. 狀態轉換和cache操作
如上文內容所述,MESI協議中cache line資料狀態有4種,引起資料狀態轉換的CPU cache操作也有4種,因此要理解MESI協議,就要將這16種狀態轉換的情況討論清楚。
初始場景:在最初的時候,所有CPU中都沒有資料,某一個CPU發生讀操作,此時發生RR,資料從主存中讀取到當前CPU的cache,狀態為E(獨佔,只有當前CPU有資料,且和主存一致),此時如果有其他CPU也讀取資料,則狀態修改為S(共享,多個CPU之間擁有相同資料,並且和主存保持一致),如果其中某一個CPU發生資料修改,那麼該CPU中資料狀態修改為M(擁有最新資料,和主存不一致,但是以當前CPU中的為準),並通知其他擁有該資料的CPU資料失效,其他CPU中的cache line狀態修改為I(失效,和主存中的資料被認為不一致,資料不可用應該重新獲取)。
5.1 modify
場景:當前CPU中資料的狀態是modify,表示當前CPU中擁有最新資料,雖然主存中的資料和當前CPU中的資料不一致,但是以當前CPU中的資料為準;
LR:此時如果發生local read,即當前CPU讀資料,直接從cache中獲取資料,擁有最新資料,因此狀態不變;
LW:直接修改本地cache資料,修改後也是當前CPU擁有最新資料,因此狀態不變;
RR:因為本地記憶體中有最新資料,因此當前CPU不會發生RR和RW,當本地cache控制器監聽到總線上有RR發生的時,必然是其他CPU發生了讀主存的操作,此時為了保證一致性,當前CPU應該將資料寫回主存,而隨後的RR將會使得其他CPU和當前CPU擁有共同的資料,因此狀態修改為S;
RW:同RR,當cache控制器監聽到匯流排發生RW,當前CPU會將資料寫回主存,因為隨後的RW將會導致主存的資料修改,因此狀態修改成I;
5.2 exclusive
場景:當前CPU中的資料狀態是exclusive,表示當前CPU獨佔資料(其他CPU沒有資料),並且和主存的資料一致;
LR:從本地cache中直接獲取資料,狀態不變;
LW:修改本地cache中的資料,狀態修改成M(因為其他CPU中並沒有該資料,因此不存在共享問題,不需要通知其他CPU修改cache line的狀態為I);
RR:因為本地cache中有最新資料,因此當前CPU cache操作不會發生RR和RW,當cache控制器監聽到總線上發生RR的時候,必然是其他CPU發生了讀取主存的操作,而RR操作不會導致資料修改,因此兩個CPU中的資料和主存中的資料一致,此時cache line狀態修改為S;
RW:同RR,當cache控制器監聽到匯流排發生RW,發生其他CPU將最新資料寫回到主存,此時為了保證快取一致性,當前CPU的資料狀態修改為I;
5.3 shared
場景:當前CPU中的資料狀態是shared,表示當前CPU和其他CPU共享資料,且資料在多個CPU之間一致、多個CPU之間的資料和主存一致;
LR:直接從cache中讀取資料,狀態不變;
LW:發生本地寫,並不會將資料立即寫回主存,而是在稍後的一個時間再寫回主存,因此為了保證快取一致性,當前CPU的cache line狀態修改為M,並通知其他擁有該資料的CPU該資料失效,其他CPU將cache line狀態修改為I;
RR:狀態不變,因為多個CPU中的資料和主存一致;
RW:當監聽到匯流排發生了RW,意味著其他CPU發生了寫主存操作,此時本地cache中的資料既不是最新資料,和主存也不再一致,因此當前CPU的cache line狀態修改為I;
5.4 invalid
場景:當前CPU中的資料狀態是invalid,表示當前CPU中是髒資料,不可用,其他CPU可能有資料、也可能沒有資料;
LR:因為當前CPU的cache line資料不可用,因此會發生RR操作,此時的情形如下。
A. 如果其他CPU中無資料則狀態修改為E;
B. 如果其他CPU中有資料且狀態為S或E則狀態修改為S;
C. 如果其他CPU中有資料且狀態為M,那麼其他CPU首先發生RW將M狀態的資料寫回主存並修改狀態為S,隨後當前CPU讀取主存資料,也將狀態修改為S;
LW:因為當前CPU的cache line資料無效,因此發生LW會直接操作本地cache,此時的情形如下。
A. 如果其他CPU中無資料,則將本地cache line的狀態修改為M;
B. 如果其他CPU中有資料且狀態為S或E,則修改本地cache,通知其他CPU將資料修改為I,當前CPU中的cache line狀態修改為M;
C. 如果其他CPU中有資料且狀態為M,則其他CPU首先將資料寫回主存,並將狀態修改為I,當前CPU中的cache line轉檯修改為M;
RR:監聽到匯流排發生RR操作,表示有其他CPU讀取記憶體,和本地cache無關,狀態不變;
RW:監聽到匯流排發生RW操作,表示有其他CPU寫主存,和本地cache無關,狀態不變;
5.5 總結
MESI協議為了保證多個CPU cache中共享資料的一致性,定義了cache line的四種狀態,而CPU對cache的4種操作可能會產生不一致狀態,因此cache控制器監聽到本地操作和遠端操作的時候,需要對地址一致的cache line狀態做出一定的修改,從而保證資料在多個cache之間流轉的一致性。
參考資料:
http://blog.csdn.net/reliveit/article/details/50450136