
NLP︱LDA主題模型的應用難題、使用心得及從多元統計角度剖析
將LDA跟多元統計分析結合起來看,那麼LDA中的主題就像詞主成分,其把主成分-樣本之間的關係說清楚了。多元學的時候聚類分為Q型聚類、R型聚類以及主成分分析。R型聚類、主成分分析針對變數,Q型聚類針對樣本。
PCA主要將的是主成分-變數之間的關係,在文字中LDA也有同樣的效果,將一撮詞(變數)變成話題(主成分),同時通過畫像主成分,可以知道人群喜歡什麼樣子的話題;
Q型聚類代表樣本之間的群落關係。
LDA假設前提:主題模型中最主要的假設是詞袋假設(bag of words),指通過交換文件內詞的次序而不影響模型訓練的結果,模型結果與詞的順序無關。
主題模型中最重要的引數就是各個文件的主題概率分佈和各個主題下的詞項概率分佈。
———————————————————————————————————————————————————
1)整個文件集合中存在k個互相獨立的主題;
2)每一個主題是詞上的多項分佈;
3)每一個文件由k個主題隨機混合組成;
4)每一個文件是k個主題上的多項分佈;
5)每一個文件的主題概率分佈的先驗分佈是Dirichlet分佈;
6)每一個主題中詞的概率分佈的先驗分佈是Dirichlet分佈。
文件的生成過程如下:
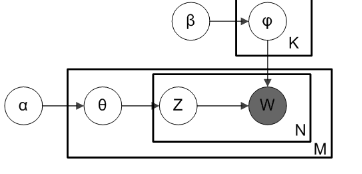
1)對於文件集合M,從引數為β的Dirichlet分佈中取樣topic生成word的分佈引數φ;
2)對於每個M中的文件m,從引數為α的Dirichlet分佈中取樣doc對topic的分佈引數θ;
3)對於文件m中的第n個詞語W_mn,先按照θ分佈取樣文件m的一個隱含的主題Z_m,再按照φ分佈取樣主題Z_m的一個詞語W_mn。
———————————————————————————————————————————————————
兩種的估計方法——VEM 以及 gibbs
通常逼近這個後驗分佈的方法可以分為兩類:
1. 變異演算法(variational algorithms),這是一種決定論式的方法。變異式演算法假設一些引數分佈,並根據這些理想中的分佈與後驗的資料相比較,並從中找到最接近的。由此,將一個估計問題轉化為最優化問題。最主要的演算法是變異式的期望最大化演算法(variational expectation-maximization,VEM)。這個方法是最主要使用的方法。在R軟體的tomicmodels包中被重點使用。
2. 基於抽樣的演算法。抽樣的演算法,如吉布斯抽樣(gibbs sampling)主要是構造一個馬爾科夫鏈,從後驗的實證的分佈中抽取一些樣本,以之估計後驗分佈。吉布斯抽樣的方法在R軟體的lda包中廣泛使用。
R包列舉——lda和topicmodel
在R語言中,有兩個包(package)提供了LDA模型:lda和topicmodels。
lda提供了基於Gibbs取樣的經典LDA、MMSB(the mixed-membership stochastic blockmodel )、RTM(Relational Topic Model)和基於VEM(variational expectation-maximization)的sLDA (supervised LDA)、RTM.。
topicmodels基於包tm,提供LDA_VEM、LDA_Gibbs、CTM_VEM(correlated topics model)三種模型。
另外包textir也提供了其他型別的主題模型。
——————————————————————————————————————————
但是主題模型存在一個非常大的問題:模型質量問題
1、模型質量較差,話題出來的無效詞較多且較難清洗乾淨;
2、話題之間,區別不夠顯著,效果不佳;
3、話題內,詞和詞的關聯性很低。
4、反映不出場景,筆者最開始希望得到的是一個話題,裡面有場景詞+使用者態度、情緒、事件詞,構成一個比較完善的系統,但是比較天真...
5、話題命名是個難點,基本詞語如果效果差了,話題畫像也很難了。
——————————————————————————————————————————
一、騰訊Peacock案例
來看看騰訊peacock的應用案例:
輸入一個詞,然後跳出來兩個內容:搜尋詞-主題列表(主題裡面有很多詞語);搜尋詞-文件列表。
筆者猜測實現三個距離計算的過程:
先計算搜尋詞向量和主題詞向量距離,主題排序;
再計算搜尋詞和主題下各個詞語向量的距離,詞語排序;
最後計算搜尋詞和文件向量的距離,文件排序。
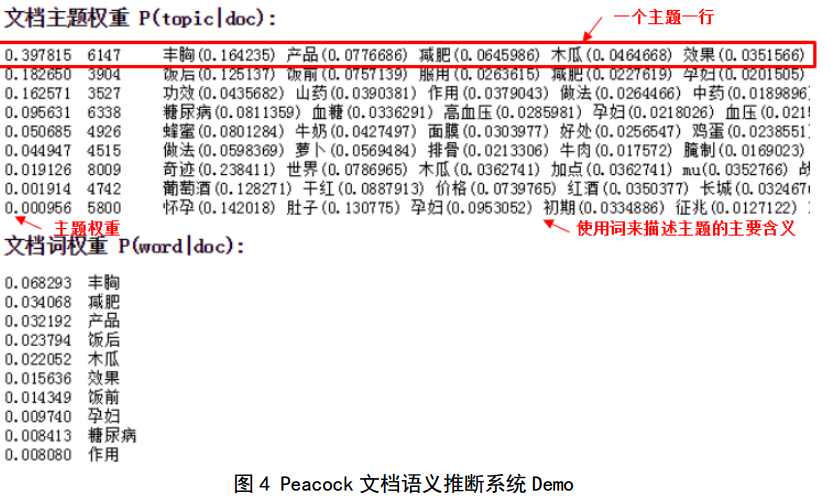
騰訊花了大力氣做的主題系統,從中可以看到這樣幾個資訊:
1、總體來看,詞和詞之間的關聯性也不是那麼強烈;
2、詞性基本都是名詞,少有動作、形容詞。
該系統還做了一些好玩的嘗試:利用使用者-QQ群矩陣,做主題模型,將QQ群進行聚類,可以很好的瞭解,不同使用者群喜歡什麼樣子話題群,人數的多少。
——————————————————————————————————————————
二、主題模型主要作用(參考部落格)
有了主題模型,我們該怎麼使用它呢?它有什麼優點呢?我總結了以下幾點:
1)它可以衡量文件之間的語義相似性。對於一篇文件,我們求出來的主題分佈可以看作是對它的一個抽象表示。對於概率分佈,我們可以通過一些距離公式(比如KL距離)來計算出兩篇文件的語義距離,從而得到它們之間的相似度。
2)它可以解決多義詞的問題。回想最開始的例子,“蘋果”可能是水果,也可能指蘋果公司。通過我們求出來的“詞語-主題”概率分佈,我們就可以知道“蘋果”都屬於哪些主題,就可以通過主題的匹配來計算它與其他文字之間的相似度。
3)它可以排除文件中噪音的影響。一般來說,文件中的噪音往往處於次要主題中,我們可以把它們忽略掉,只保持文件中最主要的主題。
4)它是無監督的,完全自動化的。我們只需要提供訓練文件,它就可以自動訓練出各種概率,無需任何人工標註過程。
5)它是跟語言無關的。任何語言只要能夠對它進行分詞,就可以進行訓練,得到它的主題分佈。
綜上所述,主題模型是一個能夠挖掘語言背後隱含資訊的利器。近些年來各大搜索引擎公司都已經開始重視這方面的研發工作。語義分析的技術正在逐步深入到搜尋領域的各個產品中去。在不久的將來,我們的搜尋將會變得更加智慧,讓我們拭目以待吧。
——————————————————————————————————————————
三、主題模型的一些延伸
模型的延伸可以看看
用在情感分析中:主題情感偏向性得分,對主題進行打分然後根據主題-文件矩陣,對每個文件的情感進行打分。
主題之間的關聯性:根據主題分佈的點積相似性,確定相關文字,建立主題之間的關聯
時序文字,動態主題模型。
短文字,消除歧義,建立語義相似性聚類;
知識圖譜的構建,知識圖譜中需要一些集合,潛變數,那麼主題建模比較適合作為一個大的包容的集合;
稀疏性利用,在模型中主題-詞語矩陣,會有很低頻的資料,那麼可以強行讓其變成0,減少影響。
2、摘錄:LDA使用心得
- 如果要訓練一個主題模型用於預測,資料量要足夠大;
- 理論上講,詞彙長度越長,表達的主題越明確,這需要一個優秀的詞庫;
- 如果想要主題劃分的更細或突出專業主題,需要專業的詞典;
- LDA的引數alpha對計算效率和模型結果影響非常大,選擇合適的alpha可以提高效率和模型可靠性;
- 主題數的確定沒有特別突出的方法,更多需要經驗;
- 根據時間軸探測熱點話題和話題趨勢,主題模型是一個不錯的選擇;
- 前面提到的正面詞彙和負面詞彙,如何利用,本文沒有找到合適的方法;
3、摘錄:LDA使用心得
整個過程中有很多不甚明朗的地方,我且謹列幾條如下:
(1) doc應該怎樣定義,是應該以每人為單位訓練topicmodel還是應該以每條微博為單位?經過比較我發現以每條微博為單位訓練的topicmodel中的每個topic的term類別更加一致;因此我選擇了以微博為doc單位訓練,並以人為doc單位做inference;不過我沒有找到關於這個問題更詳細的reference,看到的幾篇關於twitter、microblog的topicmodel應用也是用逐條微博作為處理單位。
(2)不同的估計方法之間有什麼區別?R包提供的有VEM、Gibbs、CTM等,這裡沒有做細節的比較,本文後文結果全部以Gibbs估計結果為主。
(3)topicmodel適不適合做短文字的分析?sparsity會帶來怎樣的問題?實際上以逐條微博為doc單位分析正會導致sparsity的問題,不過我還沒意識到它潛在帶來的問題。
(4)中文的文字處理感覺很捉急啊……除了分詞之外的詞性標註、句法分析、同義詞等等都沒有專門處理的R包,本文也僅做了初步的處理。
(5)最後的聚類效果不僅僅考慮名人的專業領域,也考慮了其生活中的情感狀態、愛好興趣等,是一個綜合的結果,選取不同的專業領域可以通過選取不同topic做聚類分析而得。
————————————————————————————————————
延伸一:主題模型在關鍵詞提取的應用
根據按行業分類的使用者生成文件,同時在關鍵字和短語抽取使用主題建模。同時,可以利用行業資訊作為輸入話題敏感的排名演算法提高搜尋精度。
參考部落格:http://bugra.github.io/work/notes/2017-02-05/topic-modeling-for-keyword-extraction/
————————————————————————————————————
延伸二:LDA相似文章聚類
論文:《Clustering Similar Stories Using LDA | Flipboard Engineering》by Arnab Bhadury
去掉一些噪音詞,然後LDA模型後用向量來表徵文章,提供了一個低緯度、穩健性較強的詞向量表達方式。
部落格地址:http://engineering.flipboard.com/2017/02/storyclustering
————————————————————————————————————
延伸三:中文標籤/話題提取/推薦
1、按照關鍵詞的權值如tfidf值從高到底推薦TopN個關鍵詞作為文字標籤推薦給使用者。
2、LDA,首先計算各中文文字的K個主題分佈,取概率最大的主題,然後取該主題下概率最大的TopN個詞作為標籤推薦給使用者,但是該方法K值不容易確定,最後計算出來的效果還不如第一種方法好。不過,LDA 不適合解決細粒度標籤問題,比如提取某個例項名稱。
3、標籤分發模型(NTDM),來源於社會媒體使用者標籤的分析與推薦(https://wenku.baidu.com/view/e57ba9c0f121dd36a32d82db.html)
4、抽取關鍵詞還有一個常用的方法就是 TextRank ,基於詞的視窗共現或者相似度來構建詞網,然後基於 PageRank 演算法計算詞的權重。
————————————————————————————————————延伸四:文字挖掘中主題追蹤的視覺化呈現
做進行主題分類時候,想做每個時間段的一個主題模型趨勢,就是在不同時間段進行建模,但是這樣的內容如何視覺化呢?
————————————————————————————————————
延伸五:迭代的LDA模型
LDA本身作為一種非監督的演算法模型,同時也可能由於訓練集本身存在有大量的噪聲資料,可能導致模型在效果上並不能滿足工業上的需求。比如我們經過一次LDA過程之後,得到的每個Topic的詞列表(xxx.twords)中,多多少少的混雜有其他Topic的詞語或噪聲詞語等,這就導致後邊的inference的正確率不理想。在LDA過程完成,得到xxx.twords檔案之後,我們可以嘗試根據“專家經驗”,手動去除每個Topic中不應該屬於該主題的詞。處理完之後,相當於我們得到一個比較理想、比較乾淨的“先驗知識”。
得到這樣的“先驗知識”之後,我們就可以將它當做變數傳入下一次的LDA過程,並在模型初始化時,將“先驗知識”中的詞以較大概率落到相應的Topic中。同樣的訓練集、同樣的引數再次迭代LDA過程。兩三次這樣的迭代之後,效果應該就有一定改進。
雖然能在一定程度上改進模型效果,但是這樣做也有一定的弊端:大大增大了人工成本,同時如果Topic個數過多(幾千上萬個),也很難一個個去篩選“先驗知識”。
————————————————————————————————————
延伸六:高效的主題模型如何建立?
1,文字要長,要長。不長要想辦法拼湊變長2,語料要好,多下功夫去掉翔
3,規模要大。兩層意思,一是文件數大,二是主題數多4,演算法上,plda+能支援中等規模; lightlda能支援大規模(本寶寶有點小貢獻,插播個廣告); warplda應該也可以,不過沒開源,實現應該不復雜。
5、應用場景要靠譜。直覺上講,分類等任務還是要有監督的,不太適合無監督的方法去辦。而類似基於內容的推薦應用,這種感覺的東西,LDA是靠譜的。6、短文字別用。要用也要用twitter lda~~~~Topic Model最適合的變種是加入先驗資訊:
我相信題主使用的是完全無監督的Topic Model,然而這實在是過於不work~~~浪費了現實生活中那麼多的標註資料,有監督的模型一定比無監督的好~所以!可以試試Supervised Topic Model利用你在現實中已有的標註來提高模型準確度~比如利用知乎的tag來train個有監督Topic Model~~~一定會詞聚類效果好不少。