
IK分詞器下載、使用和測試
對於Win10x86、Ubuntu環境均適用~
1.下載
為什麼要使用IK分詞器呢?最後面有測評~
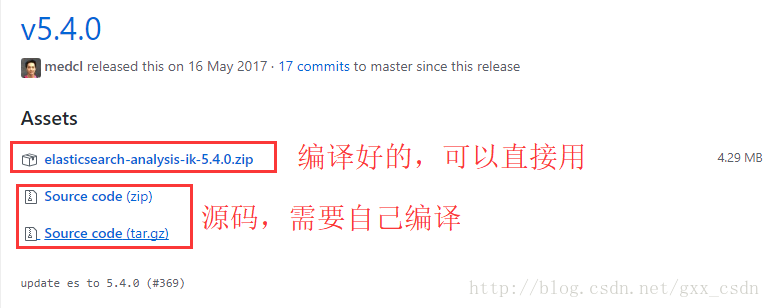
如果選擇下載原始碼然後自己編譯的話,使用maven進行編譯:
在該目錄下,首先執行:mvn compile;,會生成一個target目錄,然後執行mvn package;,會在target目錄下生成一個releases目錄,在該目錄下有一個壓縮包,這就是編譯好的,與直接下載編譯好是一樣的~
或者把該專案在IDEA開啟,在客戶端執行maven的clear、compile和package命令,效果都是一樣的,但是用命令列編譯好像稍微快一點~
2.使用
在es目錄下的plugins
ik,然後把上面的壓縮包中的內容解壓到該目錄中。
比如在Ubuntu中,把解壓出來的內容放到es/plugins/ik中:

之後,需要重新啟動es。
3.測試
1). 建立索引,指定分詞器為“ik_max_word”
PUT index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word" 2). 寫入資料到索引中
POST index/test1/1
{
"content": "裡皮是一位牌足夠大、支援率足夠高的教練" 3). 執行搜尋,比如匹配有“教練”字樣的文件
GET index/_search
{
"query": {
"match": {
"content": "教練"
}
},
"highlight": {
"pre_tags": ["<span style = 'color:red'>"],
"post_tags": ["</span>"],
"fields": {"content": {}}
}
}4). 搜尋效果
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.18232156,
"hits": [
{
"_index": "index",
"_type": "test1",
"_id": "1",
"_score": 0.18232156,
"_source": {
"content": "裡皮是一位牌足夠大、支援率足夠高的教練"
},
"highlight": {
"content": [
"裡皮是一位牌足夠大、支援率足夠高的<span style = 'color:red'>教練</span>"
]
}
},
{
"_index": "index",
"_type": "test1",
"_id": "3",
"_score": 0.16203022,
"_source": {
"content": "教練還帶領廣州恆大稱霸中超並首次奪得亞冠聯賽"
},
"highlight": {
"content": [
"<span style = 'color:red'>教練</span>還帶領廣州恆大稱霸中超並首次奪得亞冠聯賽"
]
}
}
]
}
}沒有問題哦~
4.關於IK分詞器的幾點說明
IK分詞器對中文具有良好支援的分詞器,相比於ES自帶的分詞器,IK分詞器更能適用中文博大精深的語言環境,
此外,IK分詞器包括ik_max_word和ik_smart,它們有什麼區別呢?
ik_max_word會將文字做最細粒度的拆分;
ik_smart 會做最粗粒度的拆分。
可通過下面的測試自己感受它們的不同,測試語句為“這是一個對分詞器的測試”,測試效果如下:
1). ik_max_word
GET index/_analyze?analyzer=ik_max_word
{
"text": "這是一個對分詞器的測試"
}分詞結果:
{
"tokens": [
{
"token": "這是",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "一個",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "一",
"start_offset": 2,
"end_offset": 3,
"type": "TYPE_CNUM",
"position": 2
},
{
"token": "個",
"start_offset": 3,
"end_offset": 4,
"type": "COUNT",
"position": 3
},
{
"token": "對分",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 4
},
{
"token": "分詞器",
"start_offset": 5,
"end_offset": 8,
"type": "CN_WORD",
"position": 5
},
{
"token": "分詞",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "詞",
"start_offset": 6,
"end_offset": 7,
"type": "CN_WORD",
"position": 7
},
{
"token": "器",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 8
},
{
"token": "測試",
"start_offset": 9,
"end_offset": 11,
"type": "CN_WORD",
"position": 9
}
]
}2). ik_smart
GET index/_analyze?analyzer=ik_smart
{
"text": "這是一個對分詞器的測試"
}分詞結果:
{
"tokens": [
{
"token": "這是",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "一個",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "分詞器",
"start_offset": 5,
"end_offset": 8,
"type": "CN_WORD",
"position": 2
},
{
"token": "測試",
"start_offset": 9,
"end_offset": 11,
"type": "CN_WORD",
"position": 3
}
]
}3). 自帶的分詞器
GET index/_analyze?analyzer=standard
{
"text": "這是一個對分詞器的測試"
}分詞結果:
{
"tokens": [
{
"token": "這",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "一",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "個",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "對",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "分",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "詞",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "器",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "的",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "測",
"start_offset": 9,
"end_offset": 10,
"type": "<IDEOGRAPHIC>",
"position": 9
},
{
"token": "試",
"start_offset": 10,
"end_offset": 11,
"type": "<IDEOGRAPHIC>",
"position": 10
}
]
}綜上,同樣是對“這是一個對分詞器的測試”進行分詞,不同的分詞器分詞結果不同:
ik_max_word:這是/一個/一/個/對分/分詞器/分詞/詞/器/測試
ik_smart:這是/一個/分詞器/測試
standard:這/是/一/個/對/分/詞/器/的/測/試
體會一下,嘿嘿~
