
以太坊原始碼解讀(8)以太坊的P2P模組解析——節點發現和K-桶維護
回顧一下,前面說到以太坊分散式網路採用了Kademlia協議,它的特點是:
1、採用了二叉樹的拓撲結構;
2、每個節點都對整樹進行拆分,分成n棵子樹;
3、從每棵樹中取K個節點,構成“k-桶”,每個節點控制著n個k-桶;
4、節點的距離是通過異或的二進位制運算得到的;
5、k桶中的節點不是固定不變的,而是不斷重新整理變化的。
下面,我們來看看Kademlia協議在以太坊中的具體實現。
一、以太坊的k桶
以太坊的k值是16,也就是說每個k桶包含16個節點,一共256個k桶。K桶中記錄了節點的NodeId,distance,endpoint,ip等資訊,按照與target節點的距離進行排序。
| distance 0:[2^0, 2^1) | node0 | node1 | node2 | ... | node15 |
| distance 1:[2^1, 2^2) | node0 | node1 | node2 | ... | node15 |
| distance 2:[2^2, 2^3) | node0 | node1 | node2 | ... | node15 |
| distance 3:[2^3, 2^4) | node0 | node1 | node2 | ... | node15 |
| ... | node0 | node1 | node2 | ... | node15 |
| distance 255:[2^255, 2^256) | node0 | node1 | node2 | ... | node15 |
這個表在原始碼裡為Table物件(p2p/discover/table.go):
type Table struct { mutex sync.Mutex // protects buckets, bucket content, nursery, rand buckets [nBuckets]*bucket // index of known nodes by distance nursery []*Node // bootstrap nodes rand *mrand.Rand // source of randomness, periodically reseeded ips netutil.DistinctNetSet db *nodeDB // database of known nodes refreshReq chan chan struct{} initDone chan struct{} closeReq chan struct{} closed chan struct{} nodeAddedHook func(*Node) // for testing net transport self *Node // metadata of the local node }
這裡有幾項是比較重要的:
1)buckets 型別是[nBuckets]*bucket,可以看到這是一個數組,一個bucket就是一個K-桶,一共256個bucket;
2)nursery 信任的種子節點,一個節點啟動的時候首先最多能夠連線35個種子節點,其中5個是由以太坊官方提供的,另外30個是從資料庫裡取的;
3)db 以太坊中有兩個資料庫例項,一個是用來儲存區塊鏈,另一個用來儲存p2p的節點。
4)refreshReq 重新整理K桶事件的管道,其他節點或者其他應用場景可以通過這個管道強制重新整理該節點的k桶。
二、table物件的相關方法
1、newTable()新建table
task1:根據外部或預設引數初始化Table類
task2:載入種子節點
task3:啟動資料庫重新整理go程
task4:啟動事件監聽go程
func newTable(t transport, ourID NodeID, ourAddr *net.UDPAddr, nodeDBPath string, bootnodes []*Node)
(*Table, error) {
// If no node database was given, use an in-memory one
db, err := newNodeDB(nodeDBPath, nodeDBVersion, ourID)
if err != nil {
return nil, err
}
// 初始化Table類
tab := &Table{
net: t,
db: db,
self: NewNode(ourID, ourAddr.IP, uint16(ourAddr.Port), uint16(ourAddr.Port)),
refreshReq: make(chan chan struct{}),
initDone: make(chan struct{}),
closeReq: make(chan struct{}),
closed: make(chan struct{}),
rand: mrand.New(mrand.NewSource(0)),
ips: netutil.DistinctNetSet{Subnet: tableSubnet, Limit: tableIPLimit},
}
// 載入種子節點
// 首先,初始化K桶
if err := tab.setFallbackNodes(bootnodes); err != nil {
return nil, err
}
for i := range tab.buckets {
tab.buckets[i] = &bucket{
ips: netutil.DistinctNetSet{Subnet: bucketSubnet, Limit: bucketIPLimit},
}
}
tab.seedRand()
tab.loadSeedNodes() //從table.buckets中隨機取30個節點載入種子節點到相應的bucket
// 啟動重新整理資料庫的go程
tab.db.ensureExpirer()
// 事件監聽go程
go tab.loop()
return tab, nil
}2、載入種子節點 loadSeedNodes()
func (tab *Table) loadSeedNodes() {
seeds := tab.db.querySeeds(seedCount, seedMaxAge)
seeds = append(seeds, tab.nursery...)
for i := range seeds {
seed := seeds[i]
age := log.Lazy{Fn: func() interface{} { return time.Since(tab.db.lastPongReceived(seed.ID)) }}
log.Debug("Found seed node in database", "id", seed.ID, "addr", seed.addr(), "age", age)
tab.add(seed)
}
}首先是從資料庫裡隨機選取30個節點(seedCount),然後使用table.add()方法將每個節點載入到相應的bucket中。
func (tab *Table) add(n *Node) {
tab.mutex.Lock()
defer tab.mutex.Unlock()
b := tab.bucket(n.sha)
if !tab.bumpOrAdd(b, n) {
// Node is not in table. Add it to the replacement list.
tab.addReplacement(b, n)
}
}這裡的新增不是直接新增,我們可以看到bucket的結構中有一個replacement列表,當entries是滿的時候,新找到的節點不是直接拋棄,而是放到replacement列表中。
type bucket struct {
entries []*Node // live entries, sorted by time of last contact
replacements []*Node // recently seen nodes to be used if revalidation fails
ips netutil.DistinctNetSet
}我們來總結一下k-桶初始化的過程:
1、先新建table物件,連線本地database,如果本地沒有database,則先新建一個空的database;
2、初始化K-桶,先獲得k-桶資訊的源節點:
a. 通過setFallbackNodes(bootnodes)來獲得5個nursey節點;
b. 通過tab.loadSeedNodes()——>tab.db.querySeeds()來從本地database獲得最多30個節點;
3、把上面的節點存入seeds,進行for迴圈;
4、在迴圈內執行tab.add(seed),計算seed節點與本節點的距離,選擇相應距離的bucket。如果bucket不滿,則用bump()存入bucket;如果bucket已滿,則放入replacements。
3、重新整理資料庫 expireNodes()
實際上是要定期(1小時,nodeDBCleanupCycle = time.Hour)刪除資料庫中過期的節點。什麼是過期的節點?在discovery/database.go中定義了nodeDBNodeExpiration = 24*time.Hour,即只有24小時之內ping過的節點才能得以保留。
func (db *nodeDB) expireNodes() error {
threshold := time.Now().Add(-nodeDBNodeExpiration)
// Find discovered nodes that are older than the allowance
it := db.lvl.NewIterator(nil, nil)
defer it.Release()
for it.Next() {
// Skip the item if not a discovery node
id, field := splitKey(it.Key())
if field != nodeDBDiscoverRoot {
continue
}
// Skip the node if not expired yet (and not self)
if !bytes.Equal(id[:], db.self[:]) {
if seen := db.lastPongReceived(id); seen.After(threshold) {
continue
}
}
// Otherwise delete all associated information
db.deleteNode(id)
}
return nil
}4、事件監聽 loop()
// loop schedules refresh, revalidate runs and coordinates shutdown.
func (tab *Table) loop() {
var (
revalidate = time.NewTimer(tab.nextRevalidateTime()) // 驗證節點是否可以ping通的時間通道
refresh = time.NewTicker(refreshInterval)
copyNodes = time.NewTicker(copyNodesInterval)
revalidateDone = make(chan struct{})
refreshDone = make(chan struct{}) // where doRefresh reports completion
waiting = []chan struct{}{tab.initDone} // holds waiting callers while doRefresh runs
)
defer refresh.Stop()
defer revalidate.Stop()
defer copyNodes.Stop()
// doRefresh用於執行lookup以保證k-桶是滿的狀態
go tab.doRefresh(refreshDone)
loop:
for {
select {
case <-refresh.C: // 定時重新整理k桶事件,refreshInterval=30 min
tab.seedRand()
if refreshDone == nil {
refreshDone = make(chan struct{})
go tab.doRefresh(refreshDone)
}
case req := <-tab.refreshReq: // 重新整理k桶的請求事件
waiting = append(waiting, req)
if refreshDone == nil {
refreshDone = make(chan struct{})
go tab.doRefresh(refreshDone)
}
case <-refreshDone:
for _, ch := range waiting {
close(ch)
}
waiting, refreshDone = nil, nil
case <-revalidate.C: // 驗證k桶節點有效性,10 second
go tab.doRevalidate(revalidateDone)
case <-revalidateDone:
revalidate.Reset(tab.nextRevalidateTime())
case <-copyNodes.C: // 定時(30秒)將節點存入資料庫,如果某個節點在k桶中存在超過5分鐘,則認為它是一個穩定的節點
go tab.copyLiveNodes()
case <-tab.closeReq:
break loop
}
}
if tab.net != nil {
tab.net.close()
}
if refreshDone != nil {
<-refreshDone
}
for _, ch := range waiting {
close(ch)
}
tab.db.close()
close(tab.closed)
}通過這個函式,我們看到我們的table以及k-桶是如何維護的:
1、每30分鐘自動重新整理k-桶(重新整理k-桶可以補充或保持table是滿的狀態,剛初始化的table可能並不是滿的,需要不斷的補充和更新);
2、每10秒鐘就去驗證k-桶中的節點是否可以ping通;
3、每30秒就將k-桶中存在超過5分鐘的節點存入本地資料庫,視作穩定節點;
三、節點的查詢doRefresh()、lookup()
1、doRefresh()
// doRefresh通過lookup()去查詢一個隨機的節點來保持bucket滿載。
func (tab *Table) doRefresh(done chan struct{}) {
defer close(done)
// 載入節點,這些節點在最近一次看見時依然是活動的
tab.loadSeedNodes()
// 先用自己的節點ID,執行lookup來發現鄰居節點
tab.lookup(tab.self.ID, false)
for i := 0; i < 3; i++ {
var target NodeID
// 隨機一個target,進行lookup
crand.Read(target[:])
tab.lookup(target, false)
}
}
2、lookup函式
task1:從k桶中查詢16個離target最近的節點,儲存到result切片中;
task2:節點發現主迴圈(使用上一步中查詢到的節點進行挨個詢問最近的節點,更新result,保證result中的16個節點是最近的)
流程圖

func (tab *Table) lookup(targetID NodeID, refreshIfEmpty bool) []*Node {
var (
target = crypto.Keccak256Hash(targetID[:])
asked = make(map[NodeID]bool) // 被訪問過並接收到返回result切片的節點
seen = make(map[NodeID]bool) // 在result切片中但還沒有訪問的節點
reply = make(chan []*Node, alpha)
pendingQueries = 0
result *nodesByDistance
)
// 不需要詢問自己,放在asked裡就不用再訪問
asked[tab.self.ID] = true
// ---------------------------------------------------------
// task1:從k桶中查詢16個離targetId最近的點
// ---------------------------------------------------------
for {
tab.mutex.Lock()
// 初始化result切片,從k桶中最多取離目標最近的16個非初始節點
// closest採用最笨的辦法,就是遍歷table中的每一個節點,比較距離
result = tab.closest(target, bucketSize)
tab.mutex.Unlock()
// 如果從k桶中獲取的節點數量大於0,或者上一次迴圈沒有獲取到初始節點,直接退出本次lookup
if len(result.entries) > 0 || !refreshIfEmpty {
break
}
// 如果一個都沒找到,則傳送重新整理事件,從資料庫中重新載入種子節點
<-tab.refresh()
refreshIfEmpty = false
}
// --------------------------------------------------------
// task2:對result中16個節點進行鄰近節點查詢
// 執行至此,說明result中不為空
// --------------------------------------------------------
for {
// 併發查詢,同時最多3個goroutine併發請求(通過pendingQueries引數進行控制)
for i := 0; i < len(result.entries) && pendingQueries < alpha; i++ {
n := result.entries[i]
if !asked[n.ID] { // 只有未查詢過的才能查詢
asked[n.ID] = true
pendingQueries++
go tab.findnode(n, targetID, reply)
}
}
// 如果沒有goroutine在請求,說明result中的節點都是最新的,且都詢問過
if pendingQueries == 0 {
// we have asked all closest nodes, stop the search
break
}
// 上面啟動的3個goroutine返回值為reply,檢查如果reply非空且沒有seen過
for _, n := range <-reply {
if n != nil && !seen[n.ID] {
seen[n.ID] = true
// push函式將節點放入result中,保證result數量不超過16
result.push(n, bucketSize)
}
}
// 到這裡說明某個節點返回了結果,pendingQueries減少後又可以啟動新的go程
pendingQueries--
}
return result.entries
}看到這裡,我們發現lookup只返回了一個result.entries,但是這些新找到的節點如何更新到K桶裡呢?原來在lookup執行的過程中,就開啟了go程,執行tab.findnode(),這個函式直接將找到的節點add進了K桶中。
func (tab *Table) findnode(n *Node, targetID NodeID, reply chan<- []*Node) {
// 查詢失敗的節點會儲存在本地資料庫中
fails := tab.db.findFails(n.ID)
r, err := tab.net.findnode(n.ID, n.addr(), targetID)
if err != nil || len(r) == 0 {
fails++
tab.db.updateFindFails(n.ID, fails)
log.Trace("Findnode failed", "id", n.ID, "failcount", fails, "err", err)
// 如果有5次以上fails,該節點會被拋棄,從表中刪除
if fails >= maxFindnodeFailures {
log.Trace("Too many findnode failures, dropping", "id", n.ID, "failcount", fails)
tab.delete(n)
}
} else if fails > 0 {
tab.db.updateFindFails(n.ID, fails-1)
}
// Grab as many nodes as possible. Some of them might not be alive anymore, but we'll
// just remove those again during revalidation.
for _, n := range r {
tab.add(n)
}
reply <- r
}所以上面提到的k-桶的維護中每30分鐘就要重新整理k桶,即呼叫doRefresh(),doRefresh首先對自身的節點查詢,更新了最近的16個節點,然後又對隨機的節點進行lookup查詢,更新了相應k-桶中的16個節點。
一張圖來回顧一下整個table新建和維護的過程:
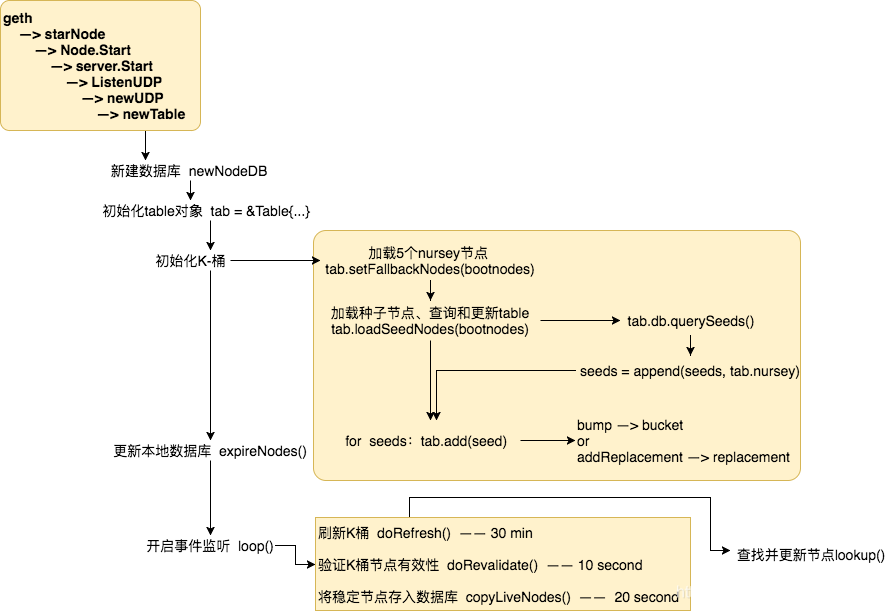
四、節點查詢的通訊協議
節點的查詢是基於UDP的通訊協議:
| 分類 | 功能描述 | 構成 |
| PING | 探測一個節點,判斷是否線上 |
|
| PONG | PING命令響應 |
|
| FINDNODE | 向節點查詢某個與目標節點ID距離接近的節點 |
|
| NEIGHBORS | FIND_NODE命令響應,傳送與目標節點ID距離接近的K桶中的節點 |
|