
創業公司做資料分析(三)使用者行為資料採集系統
作為系列文章的第三篇,本文將重點探討資料採集層中的使用者行為資料採集系統。這裡的使用者行為,指的是使用者與產品UI的互動行為,主要表現在Android App、IOS App與Web頁面上。這些互動行為,有的會與後端服務通訊,有的僅僅引起前端UI的變化,但是不管是哪種行為,其背後總是伴隨著一組屬性資料。對於與後端發生互動的行為,我們可以從後端服務日誌、業務資料庫中拿到相關資料;而對於那些僅僅發生在前端的行為,則需要依靠前端主動上報給後端才能知曉。使用者行為資料採集系統,便是負責從前端採集所需的完整的使用者行為資訊,用於資料分析和其他業務。
舉個例子,下圖所示是一次營銷活動(簡化版)的註冊流程。如果僅僅依靠後端業務資料庫,我們只能知道活動帶來了多少新註冊使用者。而通過採集使用者在前端的操作行為,則可以分析出整個活動的轉化情況:海報頁面瀏覽量—>>點選”立即註冊”跳轉註冊頁面量—>>點選“獲取驗證碼”數量—>>提交註冊資訊數量—>>真實註冊使用者量。而前端使用者行為資料的價值不僅限於這樣的轉化率分析,還可以挖掘出更多的有用資訊,甚至可以與產品業務結合,比如筆者最近在做的使用者評分系統,便會從使用者行為中抽取一部分資料作為評分依據。

在早期的產品開發中,後端研發人員每人負責一個攤子,雖然也會做些資料採集的事情,但是基本上只針對自己的功能,各做各的。通常做法是,根據產品經理提出的資料需求,設計一個結構化的資料表來儲存資料,然後開個REST API給前端,用來上報資料;前端負責在相應的位置埋點,按照協商好的資料格式上報給後端。隨著業務的發展,這樣的做法暴露了很多問題,給前後端都帶來了混亂,主要表現在:前端四處埋點,上報時呼叫的API不統一,上報的資料格式不統一;後端資料分散在多個數據表中,與業務邏輯耦合嚴重。
於是,我們考慮做一個統一的使用者行為資料採集系統,基本的原則是:統一上報方式、統一資料格式、資料集中儲存、儘可能全量採集。具體到實現上,歸納起來主要要解決三個問題:
- 採什麼。搞清楚需要什麼資料,抽象出一個統一的資料格式。
- 前端怎麼採。解決前端如何有效埋點、全量採集的問題。
- 後端怎麼存。解決資料集中儲存、易於分析的問題。
採什麼
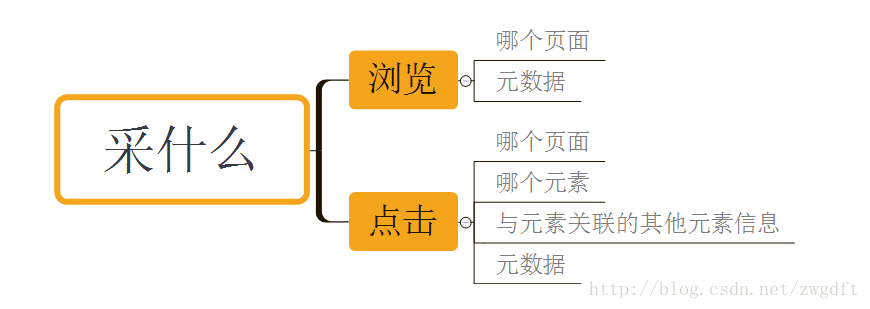
使用者在前端UI上的操作,大多數表現為兩類:第一類,開啟某個頁面,瀏覽其中的資訊,然後點選感興趣的內容進一步瀏覽;第二類,開啟某個頁面,根據UI的提示輸入相關資訊,然後點選提交。其行為可以歸納為三種:瀏覽、輸入和點選(在移動端,有時也表現為滑動)。其中,瀏覽和點選是引起頁面變化和邏輯處理的重要事件,輸入總是與點選事件關聯在一起。
因此,瀏覽和點選便是我們要採集的物件。對於瀏覽,我們關注的是瀏覽了哪個頁面,以及與之相關的元資料;對於點選,我們關注的是點選了哪個頁面的哪個元素,與該元素相關聯的其他元素的資訊,以及相關的元資料。頁面,在Android與IOS上使用View名稱來表示,在Web頁面上使用URL(hostname+pathname)來表示。元素,使用前端開發中的UI元素id來表示。與元素相關聯的其他元素資訊,指的是與“點選”相關聯的輸入/選擇資訊,比如在上面的註冊頁面中,與“提交”按鈕相關聯的資訊有手機號、驗證碼、姓名。元資料,是指頁面能提供的其他有用資訊,比如URL中的引數、App中跳轉頁面時傳遞的引數等等,這些資料往往都是很重要的維度資訊。
除了這些頁面中的資料資訊,還有兩個重要的維度資訊:使用者和時間。使用者維度,用來關聯同一使用者在某個客戶端上的行為,採用的方案是由後端生成一個隨機的UUID,前端拿到後自己快取,如果是登入使用者,可以通過元資料中的使用者id來關聯;時間維度,主要用於資料統計,考慮到前端可能延遲上報,前端上報時會加上事件的發生時間(目前大多數正常使用的移動端,時間資訊應該是自動同步的)。
綜合起來,將前端上報的資料格式定義如下。uuid、event_time、page是必填欄位,element是點選事件的必填欄位,attrs包含了上述的元資料、與元素相關聯的其他元素的資訊,是動態變化的。
{
"uuid": "2b8c376e-bd20-11e6-9ebf-525499b45be6",
"event_time": "2016-12-08T18:08:12",
"page": "www.example.com/poster.html",
"element": "register",
"attrs": {
"title": "test",
"user_id": 1234
}
}而針對不同客戶端的不同事件,通過不同的REST API來上報,每個客戶端只需呼叫與自己相關的兩個API即可。
| REST API | 說明 |
|---|---|
| /user_action/web/pv | 上報Web頁面的瀏覽事件 |
| /user_action/ios/pv | 上報IOS頁面的瀏覽事件 |
| /user_action/android/pv | 上報Android頁面的瀏覽事件 |
| /user_action/web/click | 上報Web頁面的點選事件 |
| /user_action/ios/click | 上報IOS頁面的點選事件 |
| /user_action/android/click | 上報Android頁面的點選事件 |
前端怎麼採
整理好資料格式和上報方式後,前端的重點工作便是如何埋點。傳統的埋點方式,就是在需要上報的位置組織資料、呼叫API,將資料傳給後端,比如百度統計、google analysis都是這樣做的。這是最常用的方式,缺點是需要在程式碼裡嵌入呼叫,與業務邏輯耦合在一起。近幾年,一些新的資料公司提出了“無埋點”的概念,通過在底層hook所有的點選事件,將使用者的操作儘量多的採集下來,因此也可以稱為“全埋點”。這種方式無需嵌入呼叫,程式碼耦合性弱,但是會採集較多的無用資料,可控性差。經過一番調研,結合我們自己的業務,形成了這樣幾點設計思路:
- hook底層的點選事件來做資料上報,在上報的地方統一做資料整理工作。
- 通過UI元素的屬性值來設定是否對該元素的點選事件上報。
- 通過UI元素的屬性值來設定元素的關聯關係,用於獲取上述的“與元素相關聯的其他元素的資訊”。
我們首先在Web的H5頁面中做了實踐,核心的程式碼很簡單。第一,在頁面載入時繫結所有的click事件,上報頁面瀏覽事件資料。第二,通過user_action_id屬性來表示一個元素是否需要上報點選事件,通過user_action_relation屬性來聲明當前元素被關聯到哪個元素上面,具體程式碼實現不解釋,很簡單。
$(d).ready(function() {
// 頁面瀏覽上報
pvUpload({page: getPageUrl()},
$.extend({title: getTitle()}, getUrlParams()));
// 繫結點選事件
$(d).bind('click', function(event) {
var $target = $(event.target);
// 查詢是否是需要上報的元素
var $ua = $target.closest('[user_action_id]');
if ($ua.length > 0) {
var userActionId = $ua.attr('user_action_id');
var userActionRelation = $("[user_action_relation=" + userActionId + "]");
var relationData = [];
// 查詢相關聯的元素的資料資訊
if (userActionRelation.length > 0) {
userActionRelation.each(function() {
var jsonStr = JSON.stringify({
"r_placeholder_element": $(this).get(0).tagName,
'r_placeholder_text': $(this).text()
});
jsonStr = jsonStr.replace(/\placeholder/g, $(this).attr('id'));
jsonStr = JSON.parse(jsonStr);
relationData.push(jsonStr);
});
}
// 點選事件上報
clickUpload({page: getPageUrl(), element: userActionId},
$.extend({title: getTitle()}, getUrlParams(), relationData));
}
});
});上述程式碼可以嵌入到任何HTML頁面,然後只要在對應的元素中進行申明就好了。舉個例子,
<div>
<div>
<textarea id="answer" cols="30" rows="10" user_action_relation="answer-submit"></textarea>
</div>
<button user_action_id="answer-submit">提 交</button>
</div>後端怎麼存
資料進入後臺後,首先接入Kafka佇列中,採用生產消費者模式來處理。這樣做的好處有:第一,功能分離,上報的API介面不關心資料處理功能,只負責接入資料;第二,資料緩衝,資料上報的速率是不可控的,取決於使用者使用頻率,採用該模式可以一定程度地緩衝資料;第三,易於擴充套件,在資料量大時,通過增加資料處理Worker來擴充套件,提高處理速率。
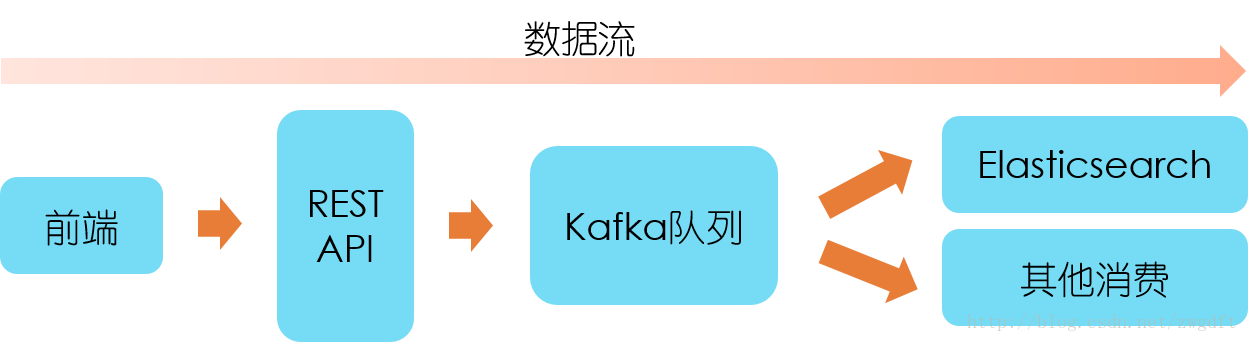
除了前端上報的資料內容外,我們還需要在後端加入一些其他的必要資訊。在資料接入Kafka佇列之前,需要加入五個維度資訊:客戶端型別(Web/Android/IOS)、事件型別(瀏覽/點選)、時間、客戶端IP和User Agent。在消費者Worker從Kafka取出資料後,需要加入一個名為event_id的欄位資料,具體含義等下解釋。因此,最後存入的資料格式便如下所示:
{
"uuid": "2b8c376e-bd20-11e6-9ebf-525499b45be6",
"event_time": "2016-12-08T18:08:12",
"page": "www.example.com/poster.html",
"element": "register",
"client_type": 0,
"event_type": 0,
"user_agent": "Mozilla\/5.0 (Linux; Android 5.1; m3 Build\/LMY47I) AppleWebKit\/537.36 (KHTML, like Gecko) Version\/4.0 Chrome\/37.0.0.0 Mobile MQQBrowser\/6.8 TBS\/036887 Safari\/537.36 MicroMessenger\/6.3.31.940 NetType\/WIFI Language\/zh_CN",
"ip": "59.174.196.123",
"timestamp": 1481218631,
"event_id": 12,
"attrs": {
"title": "test",
"user_id": 1234
}
} 再來看event_id的含義。前端傳過來的一組組資料中,通過page和element可以區分出究竟是發生了什麼事件,但是這些都是前端UI的名稱,大部分是開發者才能看懂的語言,因此我們需要為感興趣的事件新增一個通俗易懂的名稱,比如上面的資料對應的事件名稱為“在海報頁面中註冊”。將page+element、事件名稱進行關聯對映,然後將相應的資料記錄id作為event id新增到上述的資料中,方便後期做資料分析時根據跟event id來做事件聚合。做這件事有兩種方式:一種是允許相關人員通過頁面進行配置,手動關聯;一種是前端上報時帶上事件名稱,目前這兩種方式我們都在使用。
最後,來看看資料儲存的問題。傳統的關係型資料庫在儲存資料時,採用的是行列二維結構來表示資料,每一行資料都具有相同的列欄位,而這樣的儲存方式顯示不適合上面的資料格式,因為我們無法預知attrs中有哪些欄位資料。象使用者行為資料、日誌資料都屬於半結構化資料,所謂半結構化資料,就是結構變化的結構化資料(WIKI中的定義),適合使用NoSQL來做資料儲存。我們選用的是ElasticSearch來做資料儲存,主要基於這麼兩點考慮:
- Elasticsearch是一個實時的分散式搜尋引擎和分析引擎,具有很強的資料搜尋和聚合分析能力。
- 在這之前我們已經搭建了一個ELK日誌系統,可以複用Elasticsearch叢集做儲存,也可以複用Kibana來做一些基礎的資料分析視覺化。
Elasticsearch的使用方法可以參考Elasticsearch使用總結一文,這裡不做過多講解。使用Elasticsearch來做資料儲存,最重要的是兩件事:建立Elasticsearch的對映模板、批量插入。Elasticsearch會根據插入的資料自動建立缺失的index和doc type,並對欄位建立mapping,而我們要做的建立一個dynamic template,告訴Elasticsearch如何自動建立,參考如下。批量插入,可以通過Elasticsearch的bulk API輕鬆解決。
"user_action_record": {
"order": 0,
"template": "user_action_record_*",
"settings": {
},
"mappings": {
"_default_": {
"dynamic_templates": [{
"string_fields": {
"mapping": {
"type": "string",
"fields": {
"raw": {
"index": "not_analyzed",
"ignore_above": 256,
"type": "string"
}
}
},
"match_mapping_type": "string"
}
}],
"properties": {
"timestamp": {
"doc_values": true,
"type": "date"
}
},
"_all": {
"enabled": false
}
}
}
}