
用Python做股市資料分析(一)
| AAPL | GOOG | MSFT | |
|---|---|---|---|
| Date | |||
| 2016-01-04 | 1.000000 | 1.000000 | 1.000000 |
| 2016-01-05 | 0.974941 | 1.000998 | 1.004562 |
| 2016-01-06 | 0.955861 | 1.002399 | 0.986314 |
| 2016-01-07 | 0.915520 | 0.979173 | 0.952007 |
| 2016-01-08 | 0.920361 | 0.963105 | 0.954927 |
| 1 | stock_return.plot(grid=True).axhline(y=1,color="black",lw=2) |
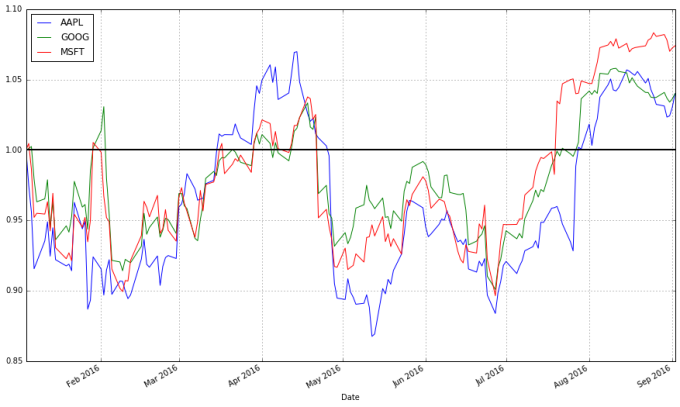
這個圖就有用多了。現在我們可以看到從我們所關心的日期算起,每支股票的收益有多高。而且我們可以看到這些股票之間的相關性很高。它們基本上朝同一個方向移動,在其他型別的圖表中很難觀察到這一現象。
我們還可以用每天的股值變化作圖。一個可行的方法是我們使用後一天$t + 1$和當天$t$的股值變化佔當天股價的比例:

我們也可以比較當天跟前一天的價格:

以上的公式並不相同,可能會讓我們得到不同的結論,但是我們可以使用對數差異來表示股票價格變化:
 - log(text{price}_{t - 1})")
(這裡的
 - log(text{price}_{t - 1})")
 - log(text{price}_{t})")
下面的程式碼演示瞭如何計算和視覺化股票的對數差異:
Python| 12345 | # Let's use NumPy's log function, though math's log function would work just as wellimportnumpy asnpstock_change=stocks.apply(lambdax:np.log(x)-np.log(x.shift(1)))# shift moves dates back by 1.stock_change.head() |
| AAPL | GOOG | MSFT | |
|---|---|---|---|
| Date | |||
| 2016-01-04 | NaN | NaN | NaN |
| 2016-01-05 | -0.025379 | 0.000997 | 0.004552 |
| 2016-01-06 | -0.019764 | 0.001400 | -0.018332 |
| 2016-01-07 | -0.043121 | -0.023443 | -0.035402 |
| 2016-01-08 | 0.005274 | -0.016546 | 0.003062 |
| 1 | stock_change.plot(grid=True).axhline(y=0,color="black",lw=2) |
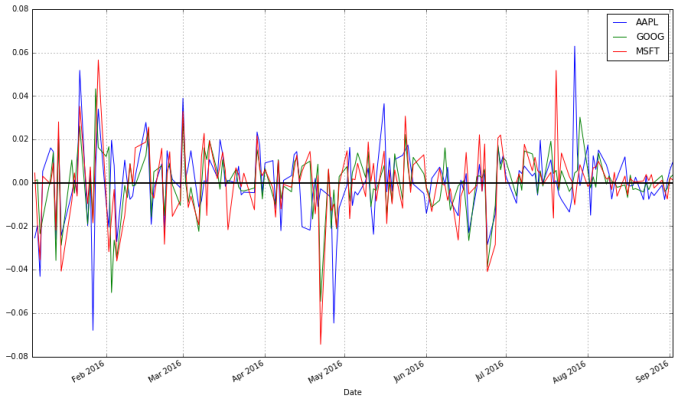
你更傾向於哪種轉換方法呢?從相對時間段開始日的收益差距可以明顯看出不同證券的總體走勢。不同交易日之間的差距被用於更多預測股市行情的方法中,它們是不容被忽視的。
移動平均值
圖表非常有用。在現實生活中,有些交易人在做決策的時候幾乎完全基於圖表(這些人是“技術人員”,從圖表中找到規律並制定交易策略被稱作技術分析,它是交易的基本教義之一。)下面讓我們來看看如何找到股票價格的變化趨勢。
一個q天的移動平均值(用

移動平均值可以讓一個系列的資料變得更平滑,有助於我們找到趨勢。q值越大,移動平均對短期的波動越不敏感。移動平均的基本目的就是從噪音中識別趨勢。快速的移動平均有偏小的q,它們更接近股票價格;而慢速的移動平均有較大的q值,這使得它們對波動不敏感從而更加穩定。
pandas提供了計算移動平均的函式。下面我將演示使用這個函式來計算蘋果公司股票價格的20天(一個月)移動平均值,並將它跟股票價格畫在一起。
Python| 12 | apple["20d"]=np.round(apple["Close"].rolling(window=20,center=False).mean(),2)pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:],otherseries="20d") |
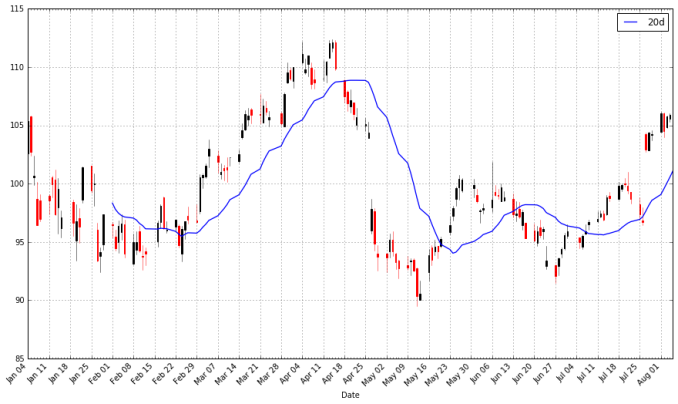
注意到平均值的起始點時間是很遲的。我們必須等到20天之後才能開始計算該值。這個問題對於更長時間段的移動平均來說是個更加嚴重的問題。因為我希望我可以計算200天的移動平均,我將擴充套件我們所得到的蘋果公司股票的資料,但我們主要還是隻關注2016。
Python| 12345 | start=datetime.datetime(2010,1,1)apple=web.DataReader("AAPL","yahoo",start,end)apple["20d"]=np.round(apple["Close"].rolling(window=20,center=False).mean(),2)pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:],otherseries="20d") |

你會發現移動平均比真實的股票價格資料平滑很多。而且這個指數是非常難改變的:一支股票的價格需要變到平局值之上或之下才能改變移動平均線的方向。因此平均線的交叉點代表了潛在的趨勢變化,需要加以注意。
交易者往往對不同的移動平均感興趣,例如20天,50天和200天。要同時生成多條移動平均線也不難:
Python| 1234 | apple["50d"]=np.round(apple["Close"].rolling(window=50,center=False).mean(),2)apple["200d"]=np.round(apple["Close"].rolling(window=200,center=False).mean(),2)pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:],otherseries=["20d","50d","200d"]) |

20天的移動平均線對小的變化非常敏感,而200天的移動平均線波動最小。這裡的200天平均線顯示出來總體的熊市趨勢:股值總體來說一直在下降。20天移動平均線所代表的資訊是熊市牛市交替,接下來有可能是牛市。這些平均線的交叉點就是交易資訊點,它們代表股票價格的趨勢會有所改變因而你需要作出能盈利的相應決策。
請移動下節內容。你將讀到如何使用移動平局線來設計和測試交易策略。
更新:該文章早期版本提到演算法交易跟高頻交易是一個意思。但是網友評論指出這並不一定:演算法可以用來進行交易但不一定就是高頻。高頻交易是演算法交易中間很大的一部分,但是兩者不等價。
相關推薦
用Python做股市資料分析(一)
AAPL GOOG MSFT Date 2016-01-04 1.000000 1.000000 1.000000 2016-01-05 0.974941 1.000998 1.004562 2016-01-06 0.955861 1.002399 0.986314 201
用 Python 做股市資料分析(2)
每次你評價交易系統的時候,都要跟買入持有策略(SPY)進行比較。除了一些信託基金和少數投資經理沒有使用它,該策略在大多時候都是無敵的。有效市場假說強調沒有人能戰勝股票市場,所以每個人都應該購入指數基金,因為它能反應整個市場的構成。SPY是一個交易型開放式指數基金(一種可以像股票一樣交易的信託基金),它的價格
循序漸進:用python做金融量化分析(二)一條移動平均線策略系統建立
在前言中我們講了些基礎知識,這一節正式開始從最簡單的移動平均線講起,移動平均線是在趨勢行情中應用最廣泛的策略,移動平均線有簡單算術平均線,指數平均線,加權平均線,還可以分為一條均線,兩條均線,三條均線策略等等,在這裡我們
註冊會計師帶你用Python進行探索性風險分析(一)
專 欄 ❈Rho,Python中文社群專欄作者,現居深圳。知乎專欄地址:https://zhuanlan.zhihu.com/BecomingaDataScientist❈ 專案介紹 所謂探索性資料分析(Exploratory Data Analysis,以下簡稱EDA),是指對已有的資料(特別是調查
【Python實戰】Pandas:讓你像寫SQL一樣做資料分析(一)
1. 引言 Pandas是一個開源的Python資料分析庫。Pandas把結構化資料分為了三類: Series,1維序列,可視作為沒有column名的、只有一個column的DataFrame; DataFrame,同Spark SQL中的DataFrame一樣,其概念來自於R語言,為多column並sch
用實戰玩轉pandas資料分析(一)——使用者消費行為分析(python)
CD商品訂單資料的分析總結。根據訂單資料(使用者的消費記錄),從時間維度和使用者維度,分析該網站使用者的消費行為。通過此案例,總結訂單資料的一些共性,能通過使用者的消費記錄挖掘出對業務有用的資訊。對其他產品的線上消費資料分析有一定的借鑑價值,能達到舉一反三的效果。 訂單交易資料分析 [
創業公司做資料分析(一)開篇
瞭解“認知心理學”的朋友應該知道:人類對事物的認知,總是由淺入深。然而,每個人思考的深度千差萬別,關鍵在於思考的方式。通過提問三部曲:WHAT->HOW->WHY,可以幫助我們一步步地從事物的表象深入到事物的本質。比如學習一個新的技術框架,需要逐步
python的計數引用分析(一)
結果 class 默認 htm ron 如果 目前 解釋器 bject python的垃圾回收采用的是引用計數機制為主和分代回收機制為輔的結合機制,當對象的引用計數變為0時,對象將被銷毀,除了解釋器默認創建的對象外。(默認對象的引用計數永遠不會變成0) 所有的計數引用+1的
用WPF做報表控制元件(一)
DataGrid是WPF自帶的報表控制元件,但其功能簡單,很多時候無法滿足我們的需求。第三方庫(如DevExpress)報表功能強大,但一方面資源消耗比較多,另一方面效能也較差,在一些比較差的電腦上執行很吃力。我之前就嘗試過在工控機上使用DevExpress,每次啟動都需要等幾秒甚至十幾秒半分鐘,體
用python來實現機器學習(一):線性迴歸(linear regression)
需要下載一個data:auto-mpg.data 第一步:顯示資料集圖 import pandas as pd import matplotlib.pyplot as plt columns = ["mpg","cylinders","displacement","horsepowe
資料分析(一)豆瓣華語電影分析
本文首發於『運籌OR帷幄』公眾號,大家也可前往公眾號檢視,《用資料帶你瞭解電影行業—華語篇》。 在之前,我們已經用通過爬蟲獲取了豆瓣華語電影共33133部電影的資料,具體爬蟲介紹請見之前的博文,爬蟲實戰(一)——利用scrapy爬取豆瓣華語電影。本文對爬蟲過程進行簡要概述後,對這部分資料
bigdata資料分析(一):Java環境配置
Java環境 1.下載jdk(用FileZilla工具連線伺服器後上傳到需要安裝的目錄) 在 /opt/deploy 下新建 java 資料夾: # mkdir / opt/deploy /java 解壓命令:tar zxvf 壓縮包名稱 (例如:tar zxvf jdk-8u191-
企業如何運用好資料分析(一)
現階段,由於科技的進步以及社會的發展,使得網際網路越來越發達。網際網路時代衍生了很多的新興詞彙,分別是大資料、資料分析、物聯網、人工智慧等。現如今我們的社會生活到處都滲透著中大資料、資料分析和人工智慧,越來越多的企業都開始重視資料分析。利用好資料分析能夠甩開競爭對手,從而使得自己的企業
Spark快速大資料分析(一)
楔子 Spark快速大資料分析 前3章內容,僅作為學習,有斷章取義的嫌疑。如有問題參考原書 Spark快速大資料分析 以下為了打字方便,可能不是在注意大小寫 1 Spark資料分析導論 1.1 Spark是什麼 Spark是一個用來實現快速而通用的叢
EXCEL資料分析(一)
最近開始學習excel資料分析,大概記錄一些操作,以便日後忘記時再看。 目錄 1.分類彙總 2.資料透視表基本操作 3.資料透視表——統計各銷量組銷售次數的頻率分佈 4.資料透視表——實戰操練 1.分類彙總 ①首先,利用“篩選”和“排序”,將資料按
房地產資料分析(一)
1.本次房地產資料特點本次資料分析的實驗資料不是來自於網頁爬取,本次實驗資料主要來自於大連市某政府部門從2008-2017年10年間的房屋不動產登記資料,資料是結構化的,其中主要包括房屋具體資訊(包括小區、房屋樓層、戶型、房屋建築面積、房屋成交價格等)、購買者相關資訊(包括星
python/pandas/numpy資料分析(七)-MultiIndex
data=Series(np.random.randn(10),index=[list('aaabbbccdd'),list('1231231223')]) data a 1 0.198134 2 0.657700 3 -0.98
python變數與資料型別(一)
python的資料型別有幾種: 整數:如1,2,3,4這種 浮點數:12.2。只要有小數點的都認為是浮點數,如果寫成12. 也認為是浮點數。浮點數預設是沒有大小限制的,但是如果太大的 話就會變成inf,無限大的意思。 字串:用''或“”來擴起
用Apache Spark進行大資料處理之用Spark GraphX圖資料分析(6)
import org.apache.spark._ import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD import java.util.Calendar // 先匯入邊 val graph = GraphLoader.edgeL
【ML專案】基於網路爬蟲和資料探勘演算法的web招聘資料分析(一)——資料獲取與處理
前言 這個專案是在學校做的,主要是想對各大招聘網站的招聘資料進行分析,沒準能從中發現什麼,這個專案週期有些長,以至於在專案快要結束時發現網上已經有了一些相關的專案,我後續會把相關的專案材料放在我的GitHub上面,連結為:https://github.com/