
Hadoop環境搭建及實現倒排索引
目 錄
1.應用介紹 3
1.1實驗環境介紹 3
1.2應用背景介紹 3
1.3應用的意義與價值 4
2.資料及儲存 5
2.1資料來源及資料量 5
2.2資料儲存解決方案 5
3.分析處理架構 5
3.1架構設計和處理方法 5
3.2核心處理演算法程式碼 7
4.系統實現 9
5.總結 27
1.應用介紹
1.1實驗環境介紹
本實驗是在hadoop偽分散式處理架構下完成的。我用自己的筆記本在ubuntu14.04作業系統下自己搭建了hadoop2.7.1架構,並配置了偽分散式模式進行資料的處理。
1.2應用背景介紹
本次雲端計算大作業實現的是文件檢索系統中最常用的資料結構—倒排索引。我通過查閱資料瞭解了倒排索引的實現過程,借鑑已有的實現程式完成了該演算法在hadoop平臺上的執行,並處理了相關的資料,得到了相應的處理結果。在關係資料庫系統裡,索引是檢索資料最有效率的方式,。但對於搜尋引擎,它並不能滿足其特殊要求:
1)海量資料:搜尋引擎面對的是海量資料,像Google、百度這樣大型的商業搜尋引擎索引都是億級甚至百億級的網頁數量,面對如此海量資料 ,使得資料庫系統很難有效的管理。
2)資料操作簡單:搜尋引擎使用的資料操作簡單,一般而言,只需要增、刪、改、查幾個功能,而且資料都有特定的格式,可以針對這些應用設計出簡單高效的應用程式。而一般的資料庫系統則支援大而全的功能,同時損失了速度和空間。最後,搜尋引擎面臨大量的使用者檢索需求,這要求搜尋引擎在檢索程式的設計上要分秒必爭,儘可能的將大運算量的工作在索引建立時完成,使檢索運算儘量的少。一般的資料庫系統很難承受如此大量的使用者請求,而且在檢索響應時間和檢索併發度上都不及我們專門設計的索引系統。
1.3應用的意義與價值
倒排索引,也常被稱為反向索引、置入檔案或反向檔案,是一種索引方法,被用來儲存在全文搜尋下某個單詞在一個文件或者一組文件中的儲存位置的對映。它是文件檢索系統中最常用的資料結構。通過倒排索引,可以根據單詞快速獲取包含這個單詞的文件列表。
現代搜尋引擎的索引都是基於倒排索引。相比“簽名檔案”、“字尾樹”等索引結構,“倒排索引”是實現單詞到文件對映關係的最佳實現方式和最有效的索引結構。
2.資料及儲存
2.1資料來源及資料量
資料的儲存格式主要是txt文字文件格式的。資料主要來自於網上的英文原版書籍。我從網上下載了超過千萬個英文單詞的英文文件,檔案大小為百兆級別。
2.2資料儲存解決方案
因為資料主要是一些txt文字檔案,所以下載下來後直接儲存在本地即可。之後上傳到Hdfs下的目錄中。
3.分析處理架構
3.1架構設計和處理方法
實現倒排索引只要關注的資訊為:單詞、文件URL及詞頻。輸入的文件格式為“檔名.txt”格式。
1)Map過程
首先使用預設的TextInputFormat類對輸入檔案進行處理,得到文字中每行的偏移量及其內容。顯然,Map過程首先必須分析輸入的
public static class Map extends Mapper<Object, Text, Text, Text> {
private Text keyInfo = new Text(); // 儲存單詞和URL組合
private Text valueInfo = new Text(); // 儲存詞頻
private FileSplit split; // 儲存Split物件
// 實現map函式
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// 獲得<key,value>對所屬的FileSplit物件 4.系統實現
首先在ubuntu14.04系統下自己搭建了hadoop2.7.1架構,然後通過設定配置檔案將hadoop架構配置為偽分散式模型。
實現過程是首先在eclipse中建立工程,編寫程式,然後打包為jar檔案。然後開啟hadoop偽分散式服務,將需要處理的本地檔案上傳到hdfs下的目錄中,然後執行jar檔案,開始處理資料。具體的實現過程如下:
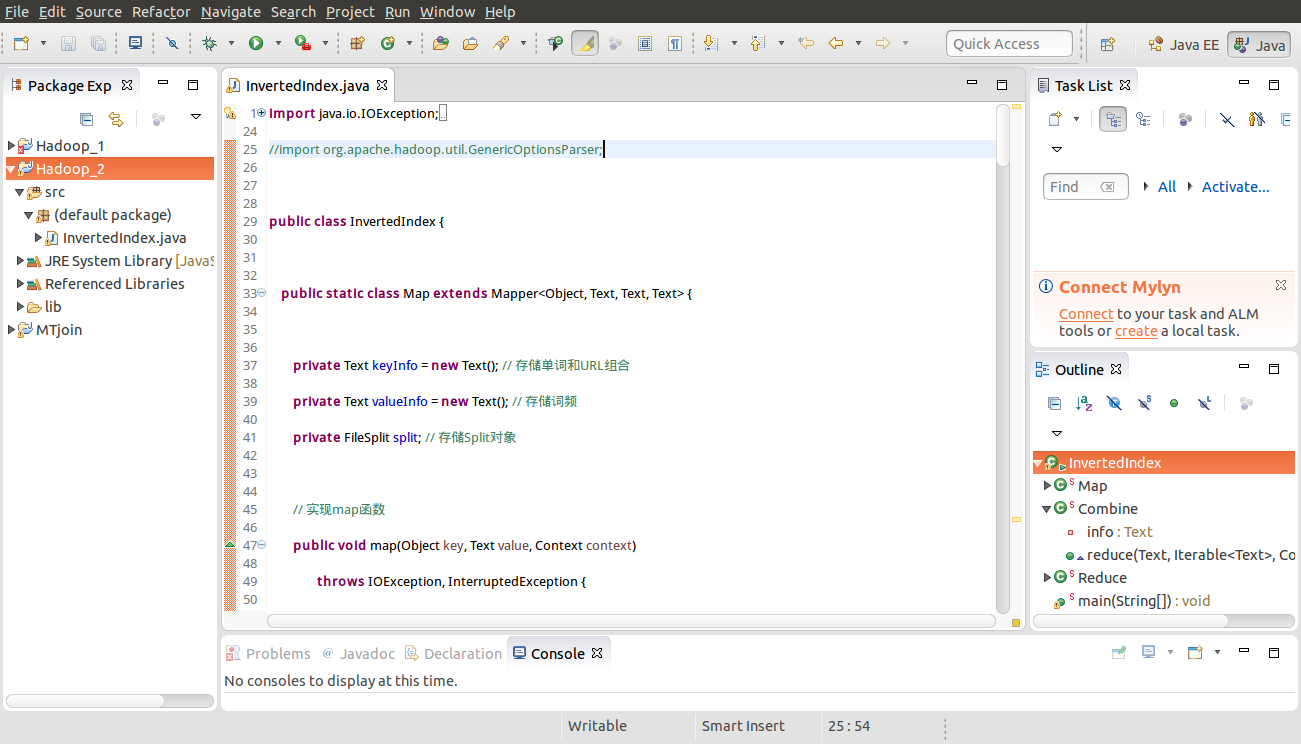
1)在eclipse中建立java工程。
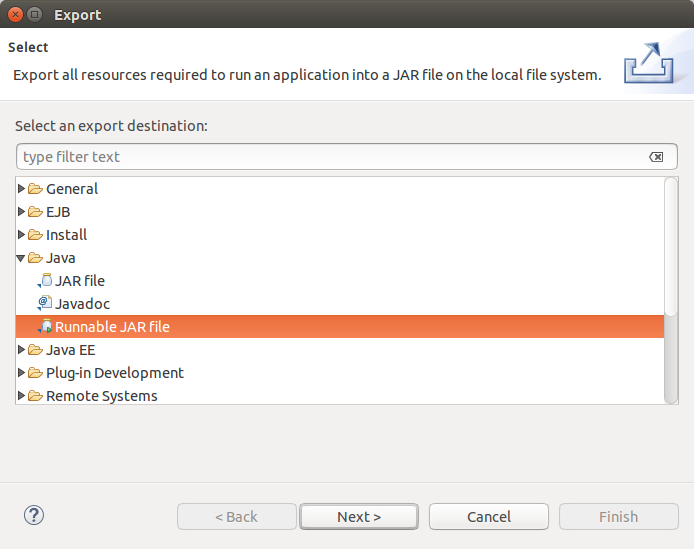
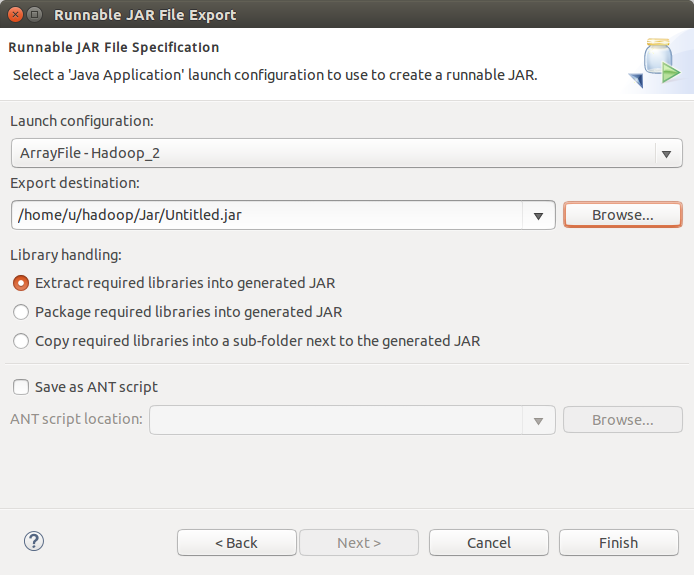
2)將完整的工程打包為jar檔案,並匯出到本地目錄下。
3)在本地目錄中檢視匯出的jar檔案為InvertedIndex.jar
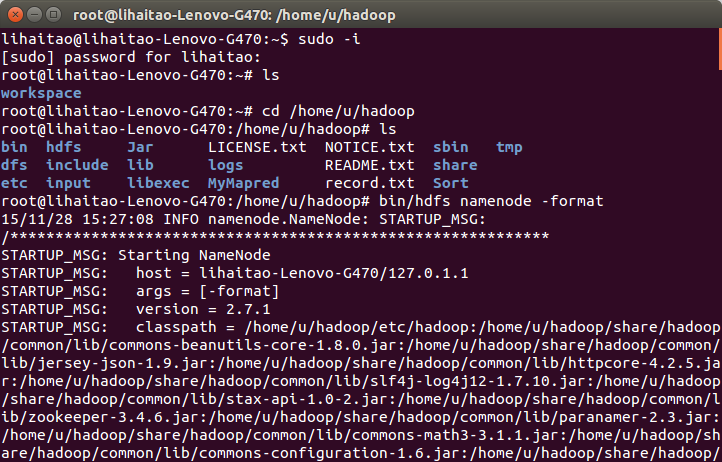
4)執行hadoop前使用命令“bin/hdfs namenode -format”初始化hdfs。
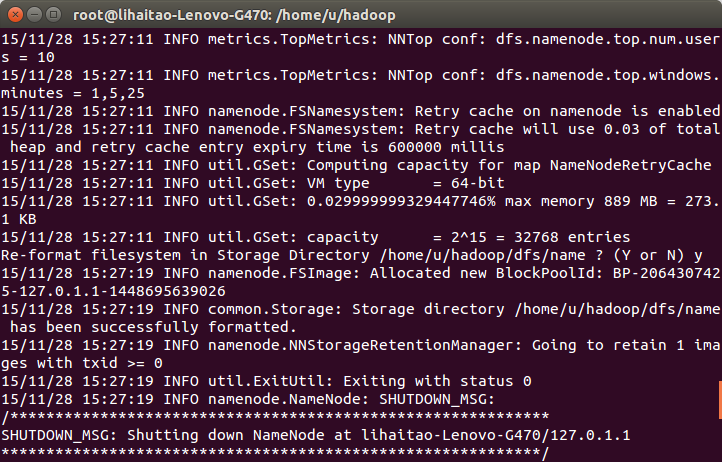
5)初始化hdfs完成
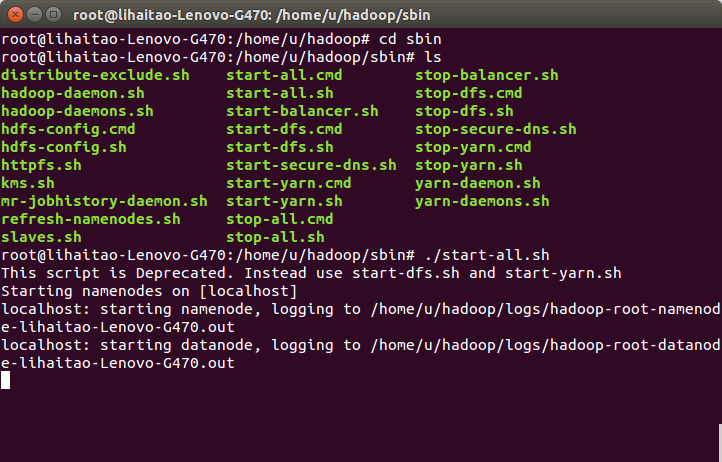
6) 開啟hadoop服務,hadoop的本地安裝目錄為/home/u/hadoop,在hadoop的安裝目錄下進入到sbin目錄下,執行start-all.sh檔案。
7)用jps命令檢視當前啟動的服務,其中有NameNode和DataNode,說明hadoop服務已開啟。
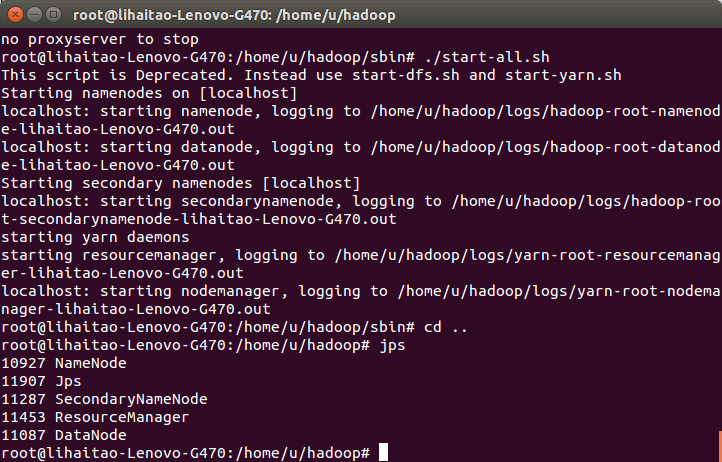
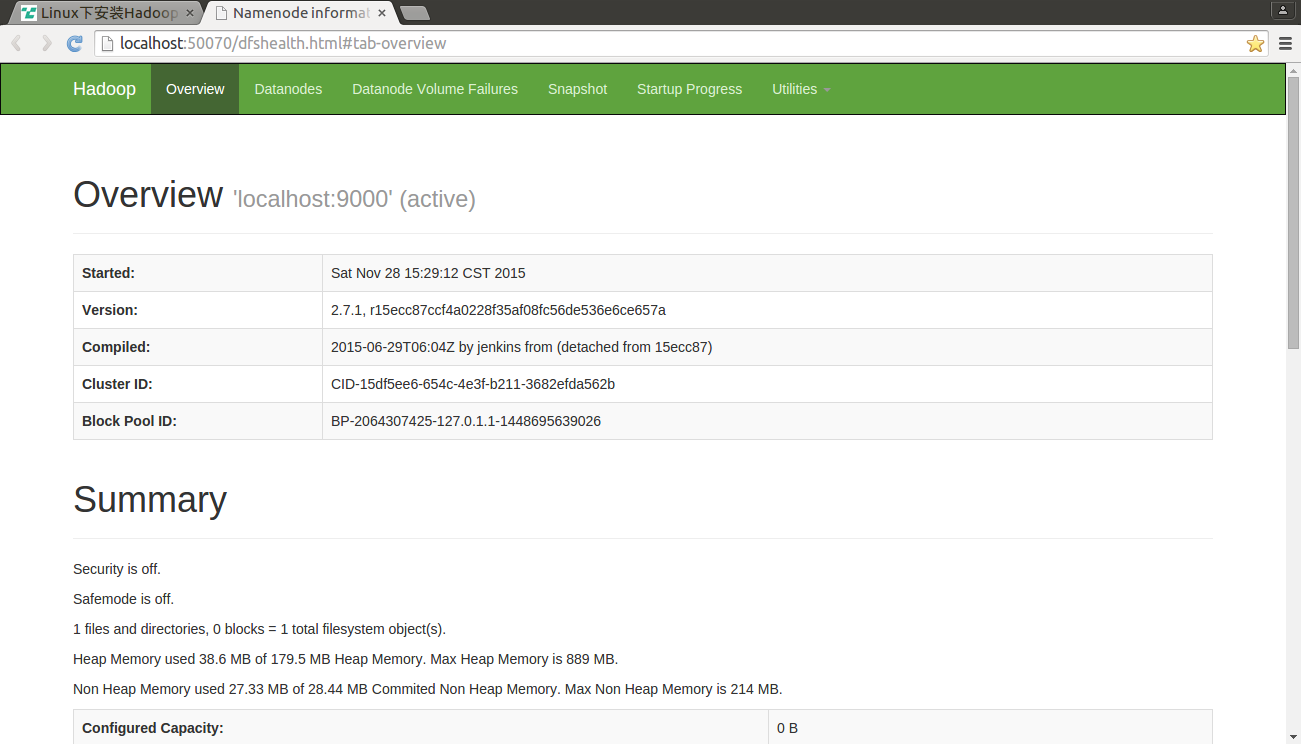
8)在瀏覽器中輸入網址:http://localhost:50070,檢視hadoop UI資訊。也說明了hadoop服務開啟成功。
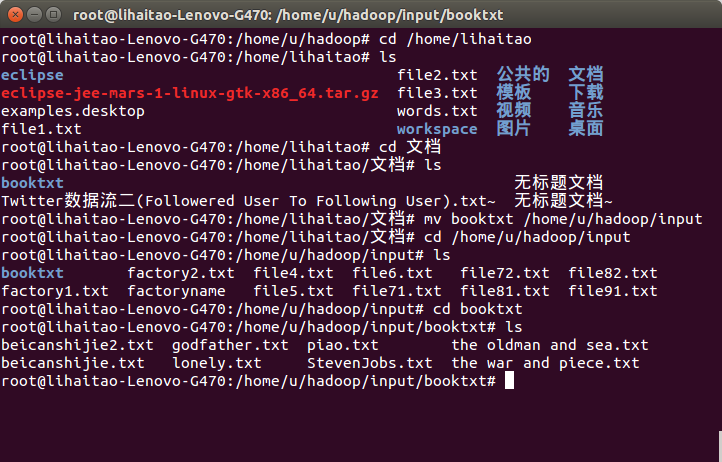
9)檢視本地需要處理的資料,為在/home/u/hadoop/input/booktxt目錄下的所有txt文字檔案。之後會將這些檔案重新命名為file*.txt檔案方面上傳了處理操作。
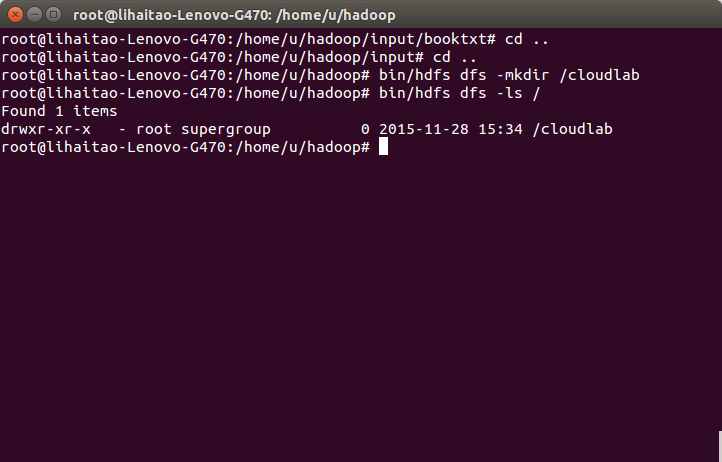
10)使用bin/hdfs dfs -mkdir /cloudlab命令在hdfs下建立目錄cloudlab儲存需要處理的檔案資料,使用bin/hdfs dfs -ls / 命令檢視hdfs當前下的目錄,顯示cloudlab目錄已建立成功。
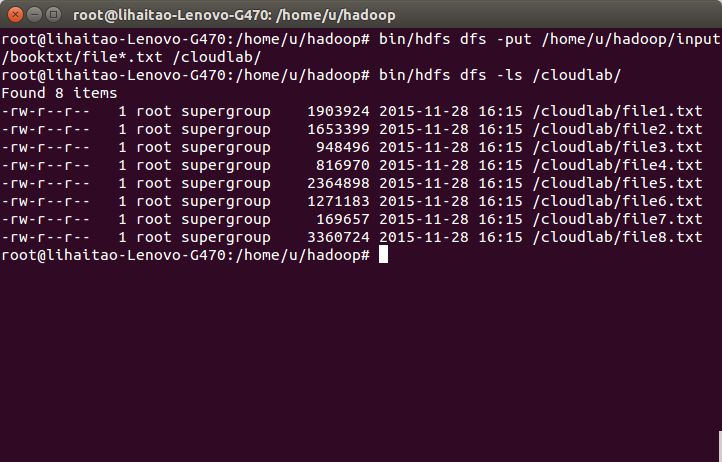
11)使用命令 “bin/hdfs dfs -put /home/u/hadoop/input/booktxt/file*.txt /cloudlab/ ”上傳本地檔案到hdfs的cloudlab目錄下。並且使用命令bin/hdfs dfs -ls /cloudlab/檢視檔案已經上傳成功。
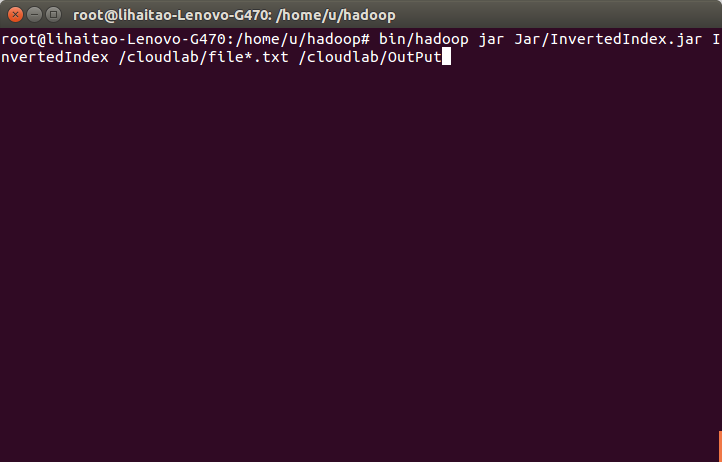
12)使用命令”bin/hadoop jar Jar/InvertedIndex.jar InvertedIndex /cloudlab/file*.txt /cloudlab/OutPut”執行InvertedIndex.jar檔案,開始對資料進行處理。其中OutPut為結果輸出目錄,執行結束後會在hdfs下自動生成該目錄。
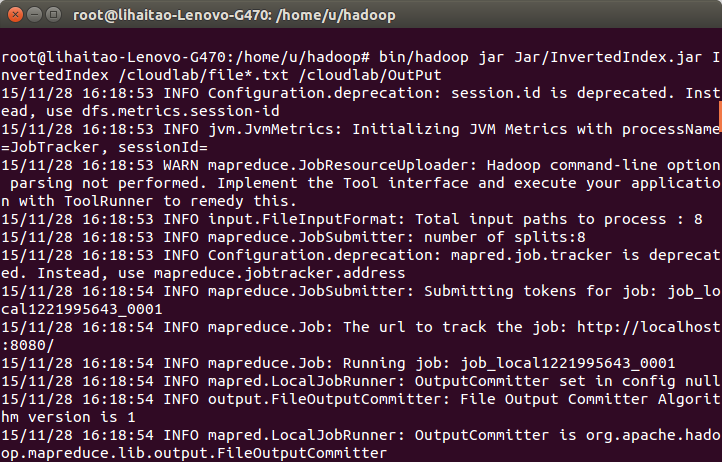
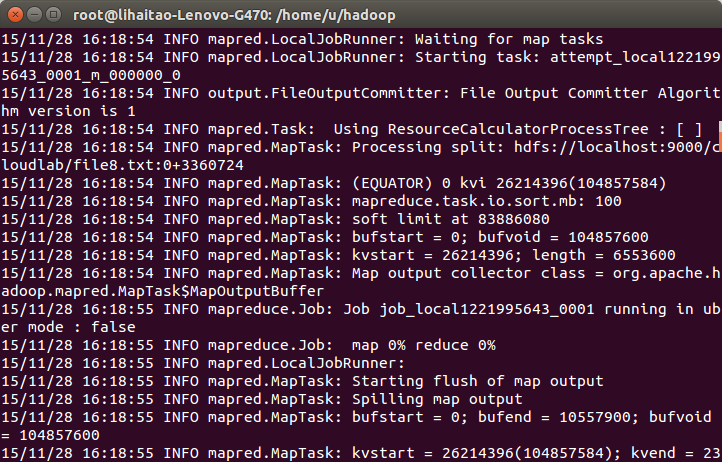
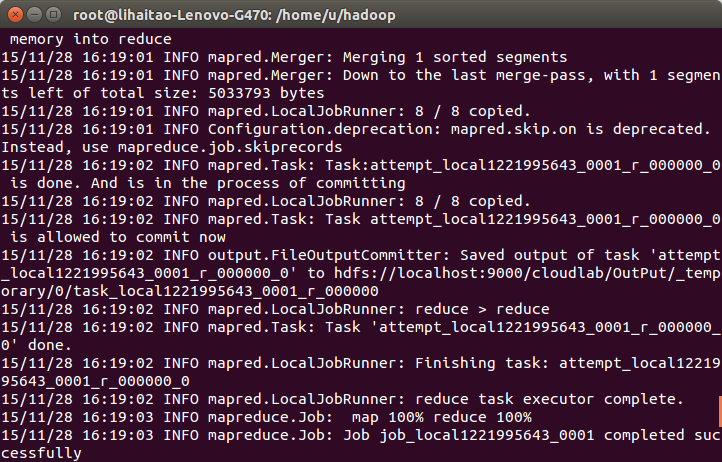
13)執行過程展示,包括程式的處理過程。
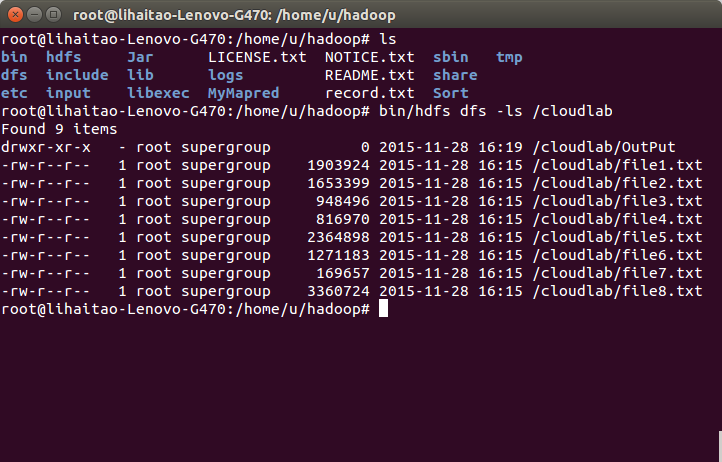
14)使用命令bin/hdfs dfs -ls /cloudlab檢視執行結果,可以看到在該目錄下生成了檔案OutPut.
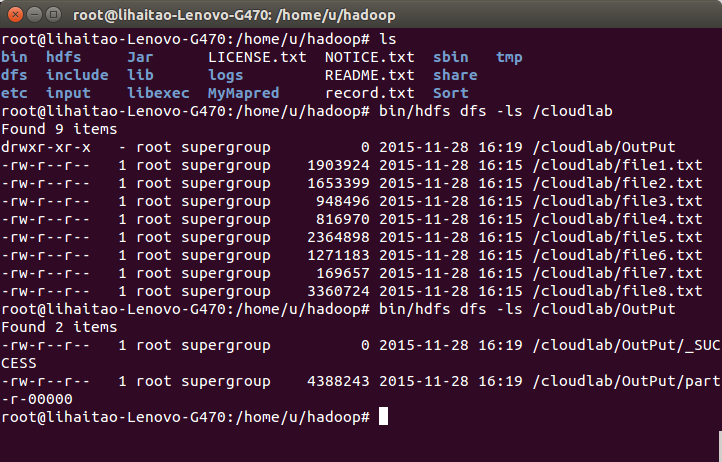
15)使用命令“bin/hdfs dfs -ls /cloudlab/OutPut”檢視OutPut目錄下輸出的檔案為:part-r-00000.
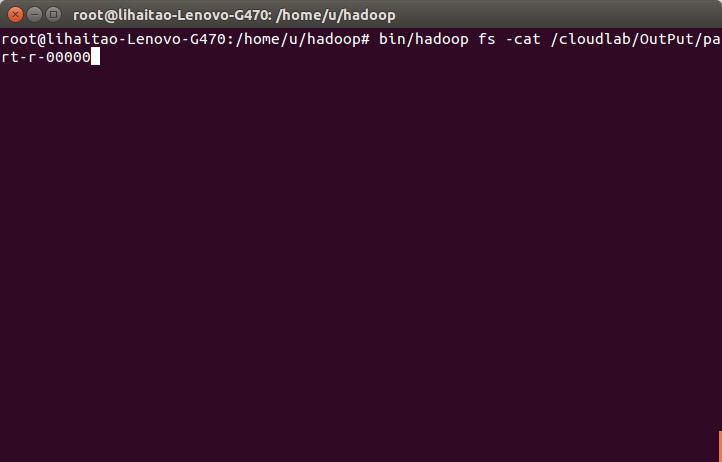
16)使用命令“bin/hadoop fs -cat /cloudlab/OutPut/part-r-00000”檢視輸出結果檔案中的內容。
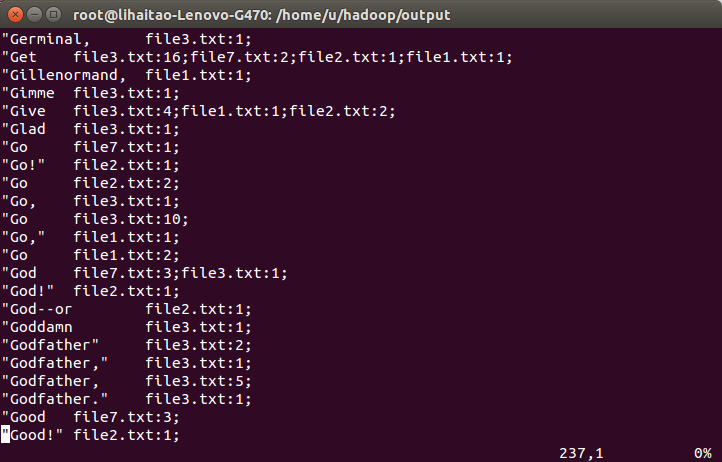
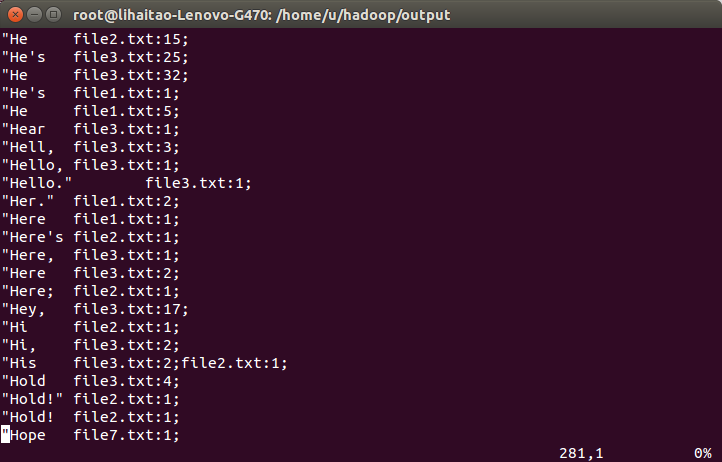
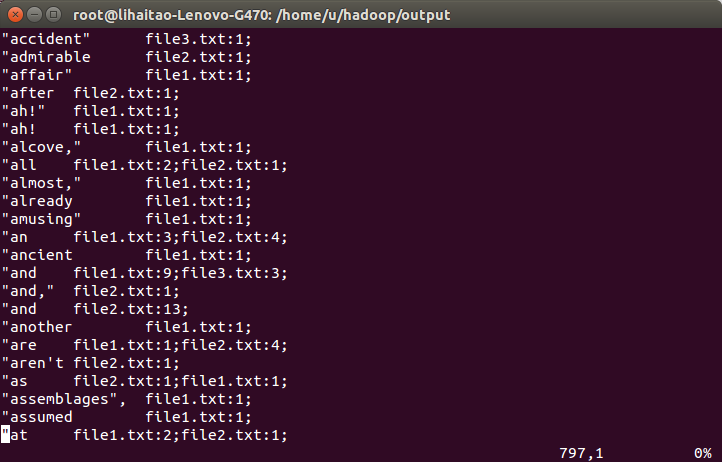
17)部分經過程式處理後的結果如下,結果顯示了一些英文單詞在每個檔案中出現的次數,符合倒排索引演算法處理的結果。
5.總結
本次實驗通過自己搭建hadoop架構來完成作業,在搭建的過程中遇到很多的問題,但通過查閱資料也一一解決了。在使用hadoop平臺執行程式處理資料的過程中也學習到了很多知識,體驗到如hadoop這樣的大資料處理框架處理大資料量的優勢。最後成功的在hadoop平臺上運行了要實現的倒排索引演算法,並對一些資料作了處理,得到了相應的結果。但也存在一些問題,比如前期資料沒有經過細緻的處理,以及結果沒有經過整理等。