
倒排索引查詢原理
Lucene 查詢過程
在lucene中查詢是基於segment。每個segment可以看做是一個獨立的subindex,在建立索引的過程中,lucene會不斷的flush記憶體中的資料持久化形成新的segment。多個segment也會不斷的被merge成一個大的segment,在老的segment還有查詢在讀取的時候,不會被刪除,沒有被讀取且被merge的segement會被刪除。這個過程類似於LSM資料庫的merge過程。下面我們主要看在一個segment內部如何實現高效的查詢。
為了方便大家理解,我們以人名字,年齡,學號為例,如何實現查某個名字(有重名)的列表。
| docid | name | age | id |
|---|---|---|---|
| 1 | Alice | 18 | 101 |
| 2 | Alice | 20 | 102 |
| 3 | Alice | 21 | 103 |
| 4 | Alan | 21 | 104 |
| 5 | Alan | 18 | 105 |
在lucene中為了查詢name=XXX的這樣一個條件,會建立基於name的倒排鏈。以上面的資料為例,倒排鏈如下:
姓名
Alice | [1,2,3]
---- | --- |
Alan | [4,5]
如果我們還希望按照年齡查詢,例如想查年齡=18的列表,我們還可以建立另一個倒排鏈:
18 | [1,5]
---| --- |
20 | [2]
21 | [3,4]
在這裡,Alice,Alan,18,這些都是term。所以倒排本質上就是基於term的反向列表,方便進行屬性查詢。到這裡我們有個很自然的問題,如果term非常多,如何快速拿到這個倒排鏈呢?在lucene裡面就引入了term dictonary的概念,也就是term的字典。term字典裡我們可以按照term進行排序,那麼用一個二分查詢就可以定為這個term所在的地址。這樣的複雜度是logN,在term很多,記憶體放不下的時候,效率還是需要進一步提升。可以用一個hashmap,當有一個term進入,hash繼續查詢倒排鏈。這裡hashmap的方式可以看做是term dictionary的一個index。 從lucene4開始,為了方便實現rangequery或者字首,字尾等複雜的查詢語句,lucene使用FST資料結構來儲存term字典,下面就詳細介紹下FST的儲存結構。
FST
我們就用Alice和Alan這兩個單詞為例,來看下FST的構造過程。首先對所有的單詞做一下排序為“Alice”,“Alan”。
-
插入“Alan”

- 插入“Alice”

這樣你就得到了一個有向無環圖,有這樣一個數據結構,就可以很快查詢某個人名是否存在。FST在單term查詢上可能相比hashmap並沒有明顯優勢,甚至會慢一些。但是在範圍,字首搜尋以及壓縮率上都有明顯的優勢。
在通過FST定位到倒排鏈後,有一件事情需要做,就是倒排鏈的合併。因為查詢條件可能不止一個,例如上面我們想找name="alan" and age="18"的列表。lucene是如何實現倒排鏈的合併呢。這裡就需要看一下倒排鏈儲存的資料結構
SkipList
為了能夠快速查詢docid,lucene採用了SkipList這一資料結構。SkipList有以下幾個特徵:
- 元素排序的,對應到我們的倒排鏈,lucene是按照docid進行排序,從小到大。
- 跳躍有一個固定的間隔,這個是需要建立SkipList的時候指定好,例如下圖以間隔是3
- SkipList的層次,這個是指整個SkipList有幾層
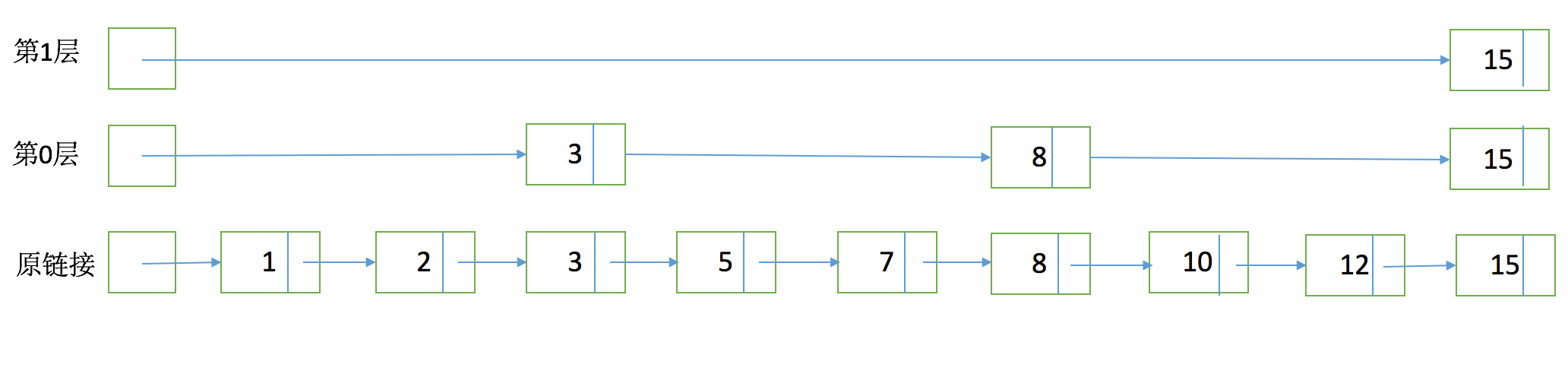
有了這個SkipList以後比如我們要查詢docid=12,原來可能需要一個個掃原始連結串列,1,2,3,5,7,8,10,12。有了SkipList以後先訪問第一層看到是然後大於12,進入第0層走到3,8,發現15大於12,然後進入原連結串列的8繼續向下經過10和12。
有了FST和SkipList的介紹以後,我們大體上可以畫一個下面的圖來說明lucene是如何實現整個倒排結構的: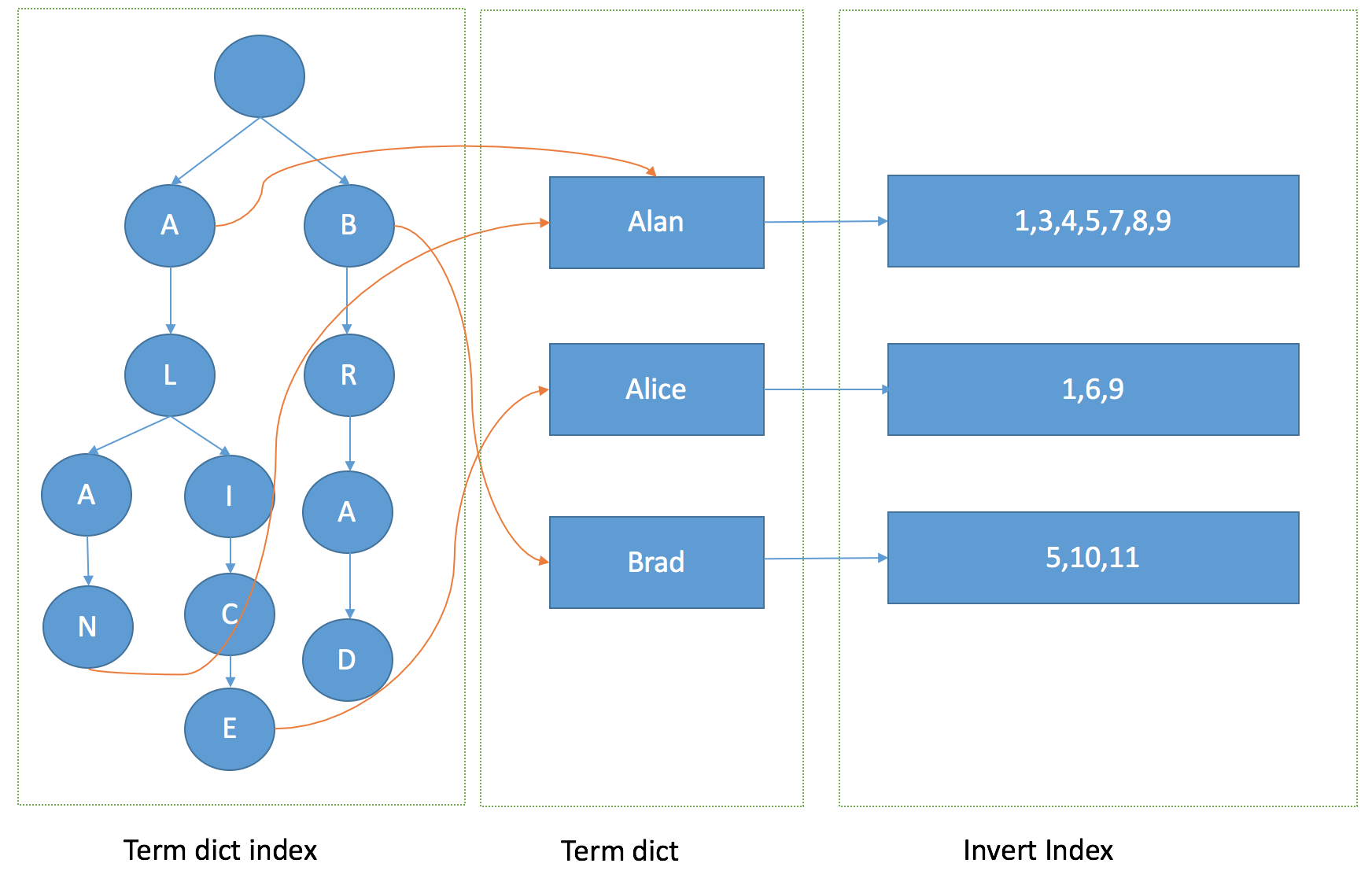
有了這張圖,我們可以理解為什麼基於lucene可以快速進行倒排鏈的查詢和docid查詢,下面就來看一下有了這些後如何進行倒排鏈合併返回最後的結果。
倒排合併
假如我們的查詢條件是name = “Alice”,那麼按照之前的介紹,首先在term字典中定位是否存在這個term,如果存在的話進入這個term的倒排鏈,並根據引數設定返回分頁返回結果即可。這類查詢,在資料庫中使用二級索引也是可以滿足,那lucene的優勢在哪呢。假如我們有多個條件,例如我們需要按名字或者年齡單獨查詢,也需要進行組合 name = "Alice" and age = "18"的查詢,那麼使用傳統二級索引方案,你可能需要建立兩張索引表,然後分別查詢結果後進行合併,這樣如果age = 18的結果過多的話,查詢合併會很耗時。那麼在lucene這兩個倒排鏈是怎麼合併呢。
假如我們有下面三個倒排鏈需要進行合併。
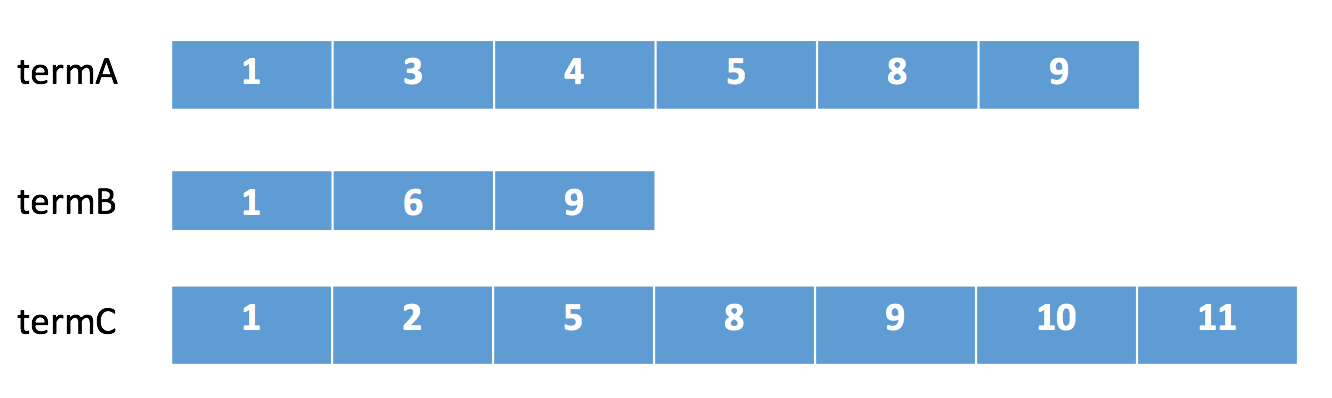
在lucene中會採用下列順序進行合併:
- 在termA開始遍歷,得到第一個元素docId=1
- Set currentDocId=1
-
在termB中 search(currentDocId) = 1 (返回大於等於currentDocId的一個doc),
- 因為currentDocId ==1,繼續
- 如果currentDocId 和返回的不相等,執行2,然後繼續
- 到termC後依然符合,返回結果
- currentDocId = termC的nextItem
- 然後繼續步驟3 依次迴圈。直到某個倒排鏈到末尾。
整個合併步驟我可以發現,如果某個鏈很短,會大幅減少比對次數,並且由於SkipList結構的存在,在某個倒排中定位某個docid的速度會比較快不需要一個個遍歷。可以很快的返回最終的結果。從倒排的定位,查詢,合併整個流程組成了lucene的查詢過程,和傳統資料庫的索引相比,lucene合併過程中的優化減少了讀取資料的IO,倒排合併的靈活性也解決了傳統索引較難支援多條件查詢的問題。
BKDTree
在lucene中如果想做範圍查詢,根據上面的FST模型可以看出來,需要遍歷FST找到包含這個range的一個點然後進入對應的倒排鏈,然後進行求並集操作。但是如果是數值型別,比如是浮點數,那麼潛在的term可能會非常多,這樣查詢起來效率會很低。所以為了支援高效的數值類或者多維度查詢,lucene引入類BKDTree。BKDTree是基於KDTree,對資料進行按照維度劃分建立一棵二叉樹確保樹兩邊節點數目平衡。在一維的場景下,KDTree就會退化成一個二叉搜尋樹,在二叉搜尋樹中如果我們想查詢一個區間,logN的複雜度就會訪問到葉子結點得到對應的倒排鏈。如下圖所示: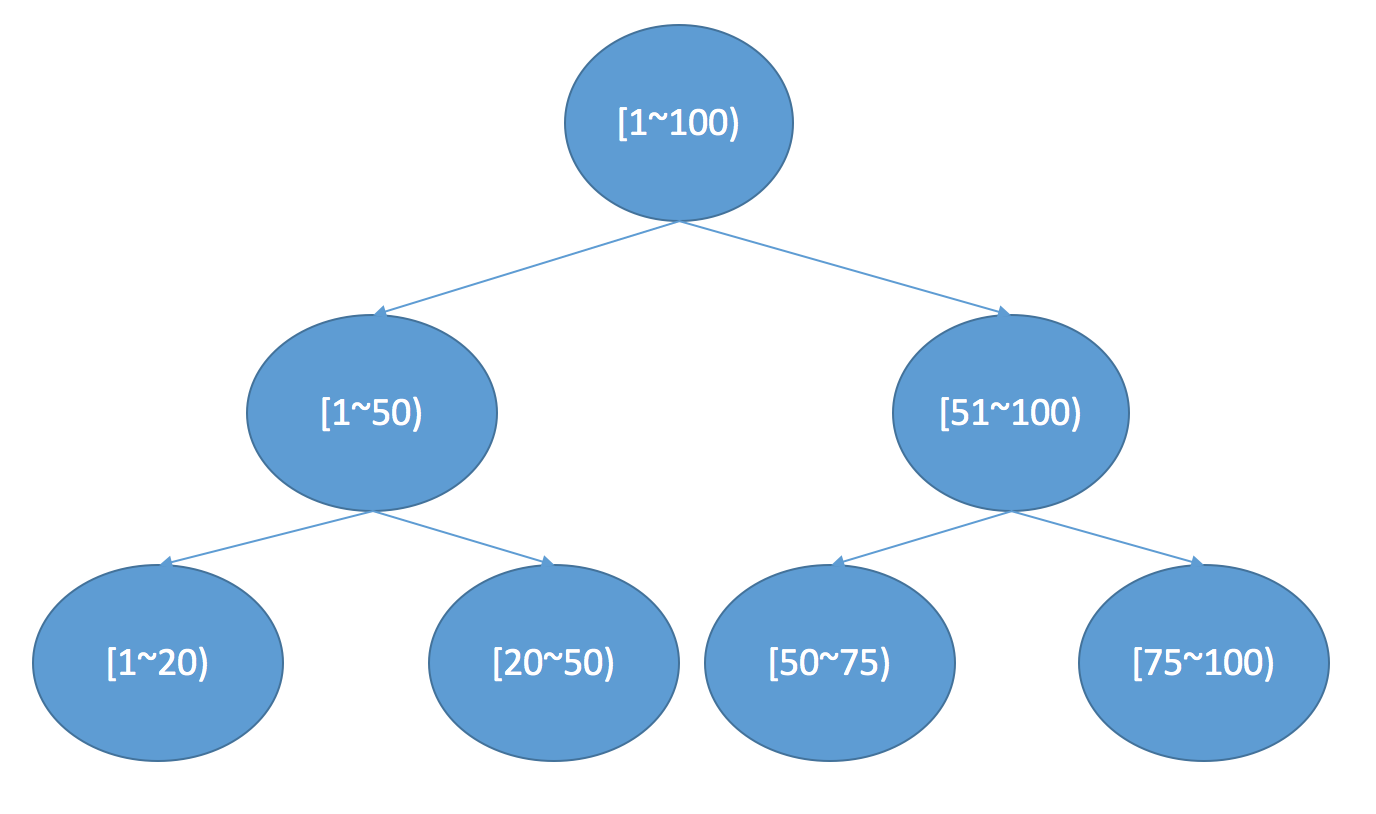
如果是多維,kdtree的建立流程會發生一些變化。
比如我們以二維為例,建立過程如下:
- 確定切分維度,這裡維度的選取順序是資料在這個維度方法最大的維度優先。一個直接的理解就是,資料分散越開的維度,我們優先切分。
- 切分點的選這個維度最中間的點。
- 遞迴進行步驟1,2,我們可以設定一個閾值,點的數目少於多少後就不再切分,直到所有的點都切分好停止。
下圖是一個建立例子: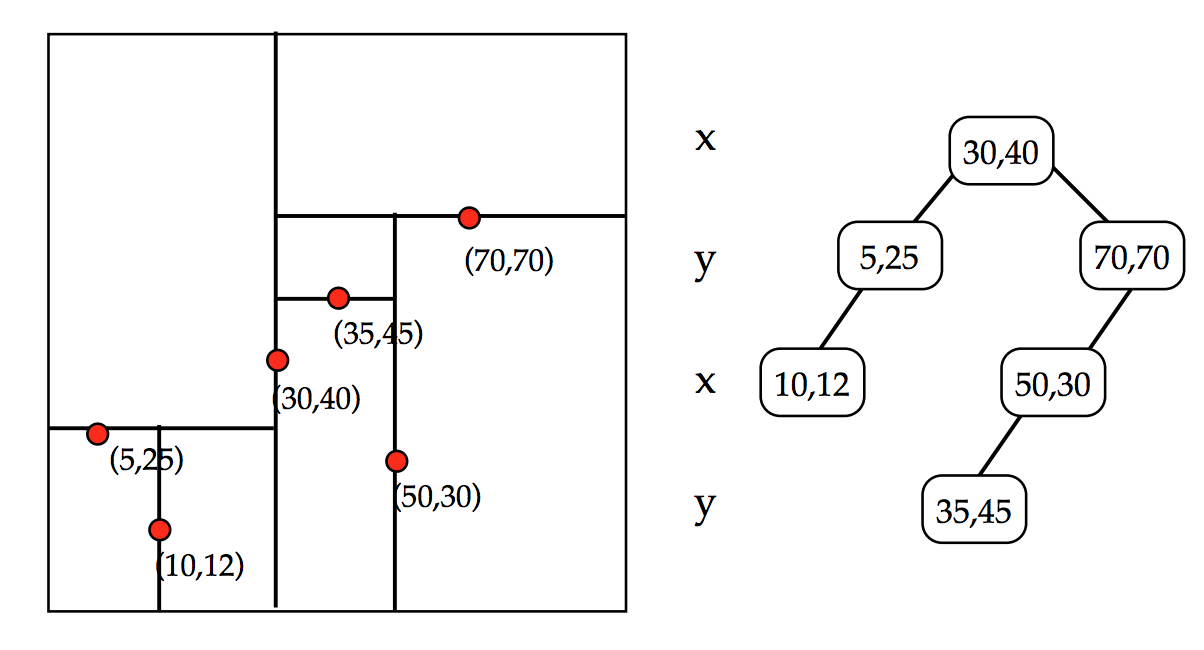
BKDTree是KDTree的變種,因為可以看出來,KDTree如果有新的節點加入,或者節點修改起來,消耗還是比較大。類似於LSM的merge思路,BKD也是多個KDTREE,然後持續merge最終合併成一個。不過我們可以看到如果你某個term型別使用了BKDTree的索引型別,那麼在和普通倒排鏈merge的時候就沒那麼高效了所以這裡要做一個平衡,一種思路是把另一類term也作為一個維度加入BKDTree索引中。
如何實現返回結果進行排序聚合
通過之前介紹可以看出lucene通過倒排的儲存模型實現term的搜尋,那對於有時候我們需要拿到另一個屬性的值進行聚合,或者希望返回結果按照另一個屬性進行排序。在lucene4之前需要把結果全部拿到再讀取原文進行排序,這樣效率較低,還比較佔用記憶體,為了加速lucene實現了fieldcache,把讀過的field放進記憶體中。這樣可以減少重複的IO,但是也會帶來新的問題,就是佔用較多記憶體。新版本的lucene中引入了DocValues,DocValues是一個基於docid的列式儲存。當我們拿到一系列的docid後,進行排序就可以使用這個列式儲存,結合一個堆排序進行。當然額外的列式儲存會佔用額外的空間,lucene在建索引的時候可以自行選擇是否需要DocValue儲存和哪些欄位需要儲存。