
Tell Me Where to Look: Guided Attention Inference Network論文翻譯
轉載:http://tongtianta.site/paper/852
Tell Me Where to Look: Guided Attention Inference Network
告訴我去哪兒看:引導注意推理網路
Abstract
摘要
Weakly supervised learning with only coarse labels can obtain visual explanations of deep neural network such as attention maps by back-propagating gradients. These attention maps are then available as priors for tasks such as object localization and semantic segmentation. In one common framework we address three shortcomings of previous approaches in modeling such attention maps: We (1) first time make attention maps an explicit and natural component of the end-to-end training, (2) provide self-guidance directly on these maps by exploring supervision form the network itself to improve them, and (3) seamlessly bridge the gap between using weak and extra supervision if available. Despite its simplicity, experiments on the semantic segmentation task demonstrate the effectiveness of our methods. We clearly surpass the state-of-the-art on Pascal VOC 2012 val. and test set. Besides, the proposed framework provides a way not only explaining the focus of the learner but also feeding back with direct guidance towards specific tasks. Under mild assumptions our method can also be understood as a plug-in to existing weakly supervised learners to improve their generalization performance.
只有粗糙標籤的弱監督學習可以通過反向傳播梯度獲得深層神經網路的視覺解釋,例如注意力圖。這些注意圖隨後可用作物件本地化和語義分割等任務的先驅。在一個共同的框架中,我們解決了以往方法在建模這樣的注意圖時存在的三個缺點:我們(1)首次使注意圖成為端到端培訓的一個明確且自然的組成部分,(2)直接在這些注意圖上提供自我指導通過探索網路本身的監督來改進它們;(3)無縫地彌合使用弱監督和額外監督(如果有的話)之間的差距。儘管簡單,但語義分割任務的實驗證明了我們方法的有效性。我們明顯超越了Pascal VOC 2012 val的最新技術水平。和測試集。此外,提出的框架不僅可以解釋學習者的焦點,還可以反饋直接指導特定任務。在溫和假設下,我們的方法也可以理解為現有弱監督學習者的外掛,以提高其泛化效能。
1. Introduction
1.介紹
Weakly supervised learning [3, 26, 33, 35] has recently gained much attention as a popular solution to address labeled data scarcity in computer vision. Using only image level labels for example, one can obtain attention maps for a given input with back-propagation on a Convolutional Neural Network (CNN). These maps relate to the network’s response given specific patterns and tasks it was trained for.The value of each pixel on an attention map reveals to what extent the same pixel on the input image contributes to the final output of the network. It has been shown that one can extract localization and segmentation information from such attention maps without extra labeling effort.
弱監督學習[3,26,33,35]近來備受關注,成為解決計算機視覺中標記資料稀缺問題的流行解決方案。例如,僅使用影象級別標籤,可以獲得給定輸入的注意圖,其中在卷積神經網路(CNN)上具有向後傳播。這些地圖涉及網路的響應,給出了特定的模式和任務。注意圖上每個畫素的值揭示了輸入影象上相同畫素對網路最終輸出的貢獻程度。已經表明,可以從這些注意圖中提取本地化和分割資訊,而無需額外的標記工作。
However, supervised by only classification loss, atten tion maps often only cover small and most discriminative regions of object of interest [11, 28, 38]. While these attention maps can still serve as reliable priors for tasks like segmentation [12], having attention maps covering the target foreground objects as complete as possible can further boost the performance. To this end, several recent works either rely on combining multiple attention maps from a network via iterative erasing steps [31] or consolidating attention maps from multiple networks [11]. Instead of passively exploiting trained network attention, we envision an end-toend framework with which task-specific supervision can be directly applied on attention maps during training stage.
然而,僅受分類損失的監督,關注地圖通常只覆蓋感興趣物件的小型和最具區分性的區域[11,28,38]。雖然這些注意圖仍然可以作為分割[12]等任務的可靠先驗,但是儘可能完整地包含覆蓋目標前景物件的注意圖可以進一步提升效能。為此,最近的一些作品要麼依靠通過迭代擦除步驟[31]或者從多個網絡合並注意力圖來合併來自網路的多個注意圖[11]。我們設想了一種端到端的框架,可以在訓練階段直接將任務特定的監督應用於注意力圖上,而不是被動地利用受過訓練的網路注意力。
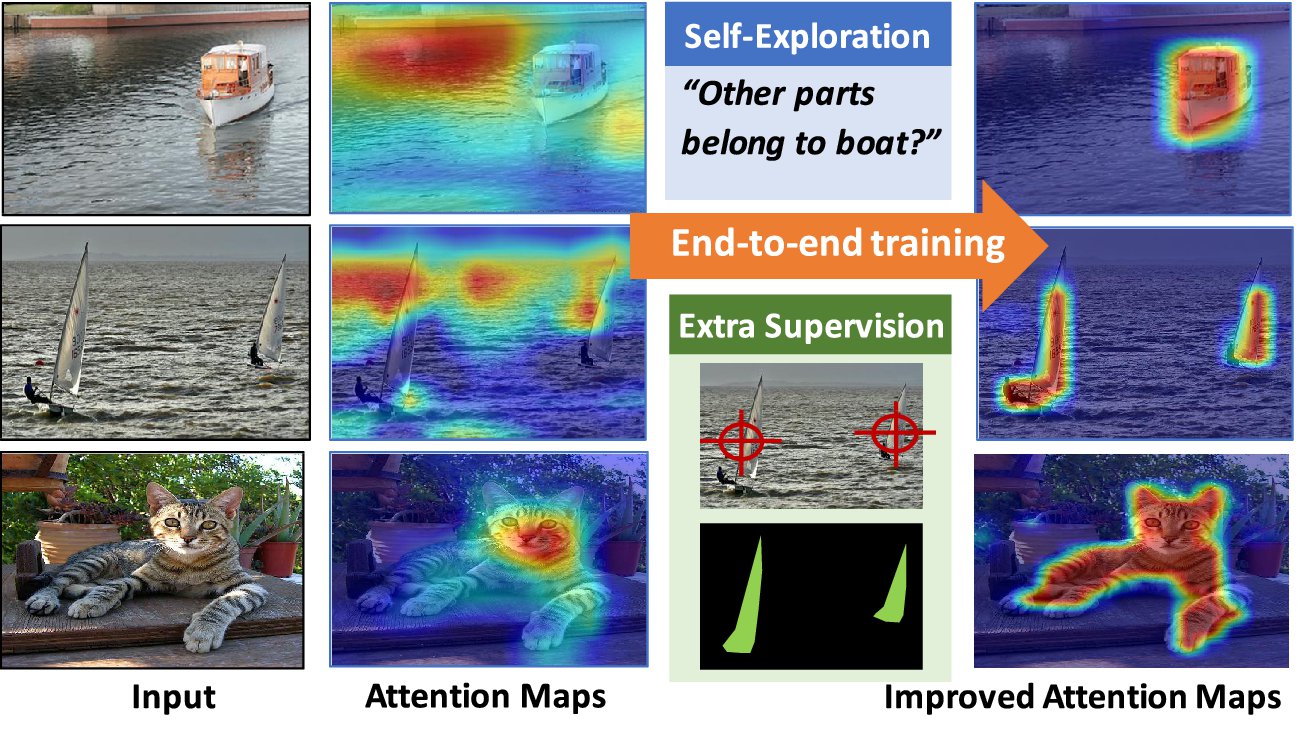
Figure 1. The proposed Guided Attention Inference Network (GAIN) makes the network’s attention on-line trainable and can plug in different kinds of supervision directly on attention maps in an end-to-end way. We explore the self-guided supervision from the network itself and propose GAINext when extra supervision are available. These guidance can optimize attention maps towards the task of interest.
圖1.提出的引導注意推理網路(GAIN)使網路的注意力可以線上培訓,並且可以直接在端點到端的方式上插入注意力圖上的各種監督。我們從網路本身探索自我監督,並在有額外監督時提出GAINext。這些指導可以優化關注地圖以完成感興趣的任務。
On the other hand, as an effective way to explain the network’s decision, attention maps can help to find restrictions of the training network. For instance in an object categorization task with only image-level object class labels, we may encounter a pathological bias in the training data when the foreground object incidentally always correlates with the same background object (also pointed out in [24]). Figure 1 shows the example class ”boat” where there may be bias towards water as a distractor with high correlation. In this case the training has no incentive to focus attention only on the foreground class and generalization performance may suffer when the testing data does not have the same correlation (”boats out of water”). While there have been attempts to remove this bias by re-balancing the training data, we instead propose to model the attention map explicitly as part of the training. As one benefit of this we are able to control the attention explicitly and can put manual effort in providing minimal supervision of attention rather than re-balancing the data set. While it may not always be clear how to manually balance data sets to avoid bias, it is usually straightforward to guide attention to the regions of interest.We also observe that our explicit selfguided attention model already improves the generalization performance even without extra supervision.
另一方面,作為解釋網路決策的有效方式,注意圖可以幫助找到訓練網路的限制。例如,在僅具有影象級物件類標籤的物件分類任務中,當前景物件偶然與相同背景物件相關時(也在[24]中指出),我們可能在訓練資料中遇到病態偏差。圖1顯示了示例類“船”,其中可能存在偏向於作為具有高度相關性的牽引器的水。在這種情況下,訓練沒有動機將注意力集中在前景課堂上,當測試資料沒有相同的相關性時(“水上游艇”),泛化效能可能會受到影響。雖然有人試圖通過重新平衡訓練資料來消除這種偏見,但我們建議將注意圖明確地建模為訓練的一部分。作為其中一個好處,我們能夠明確地控制注意力,並且可以採取人工努力對關注點進行最小限度的監督,而不是重新平衡資料集。雖然可能並不總是清楚如何手動平衡資料集以避免偏差,但引導對感興趣區域的關注通常很簡單。我們還觀察到,即使沒有額外的監督,我們的顯式自引導注意模型已經提高了泛化效能。
Our contributions are: (a) A method of using supervision directly on attention maps during training time while learning a weakly labeled task; (b) A scheme for self-guidance during training that forces the network to focus attention on the object holistically rather than only the most discriminative parts; (c) Integration of direct supervision and selfguidance to seamlessly scale from using only weak labels to using full supervision in one common framework.
我們的貢獻是:(a)在培訓期間直接在關注地圖上使用監督,同時學習弱標記任務的方法; (b)培訓期間的自我指導方案,迫使網路將注意力集中在整體而不僅僅是最具有歧視性的部分; (c)將直接監督和自我指導納入從一個共同框架中只使用薄弱標籤到全面監督的無縫擴充套件。
Experiments using semantic segmentation as task of interest show that our approach achieves mIoU 55.3% and 56.8%, respectively on the val and test of the PASCAL VOC 2012 segmentation benchmark.It also confidently surpasses the comparable state-of-the-art when limited pixellevel supervision is used in training with an mIoU of 60.5% and 62.1% respectively. To the best of our knowledge these are the new state-of-the-art results under weak supervision.
使用語義分割作為感興趣的任務的實驗表明,我們的方法分別在PASCAL VOC 2012分割基準的閾值和測試上達到mIoU 55.3%和56.8%。當有限畫素水平的監督分別用於60.5%和62.1%的mIoU訓練時,它也自信地超越了可比較的最新水平。就我們所知,這些是在弱監管下的最新的最新成果。
2. Related work
2.相關工作
Since deep neural networks have achieved great success in many areas [7, 34], various methods have been proposed to try to explain this black box [3, 26, 33, 36, 37]. Visual attention is one way that tries to explain which region of the image is responsible for network’s decision. In [26, 29, 33], error backpropagation based methods are used for visualizing relevant regions for a predicted class or the activation of a hidden neuron. In [3], a feedback CNN architecture is proposed for capturing the top-down attention mechanism that can successfully identify task relevant regions. CAM [38] shows that replacing fully-connected layers with an average pooling layer can help generate coarse class activation maps that highlight task relevant regions. Inspired by a top-down human visual attention model, [35] proposes a new backpropagation scheme, called Excitation Backprop, to pass along top-down signals downwards in the network hierarchy. Recently, Grad-CAM [24] extends the CAM to various off-the-shelf available architectures for tasks including image classification, image captioning and VQA providing faithful visual explanations for possible model decisions. Different from all these methods that are trying to explain the network, we first time build up an end-to-end model to provide supervision directly on these explanations, specifically network’s attention here. We validate these supervision can guide the network focus on the regions we expect and benefit the corresponding visual tasks.
由於深層神經網路在很多領域取得了巨大的成功[7,34],因此已經提出了各種方法來試圖解釋這個黑盒子[3,26,33,36,37]。視覺注意力是試圖解釋影象的哪個區域負責網路決策的一種方式。在[26,29,33]中,基於誤差反向傳播的方法用於視覺化預測類的相關區域或隱藏神經元的啟用。在文獻[3]中,提出了一種反饋CNN架構來捕捉自上而下的關注機制,可以成功識別任務相關區域。CAM [38]表明,用平均池層替換完全連線的層可以幫助生成突出任務相關區域的粗糙類啟用圖。受到自上而下的人類視覺注意模型的啟發,[35]提出了一種稱為激勵反向傳播的新反向傳播方案,在網路層次中向下傳遞自上而下的訊號。最近,Grad-CAM [24]將CAM擴充套件到各種現成可用架構,以完成影象分類,影象字幕和VQA等任務,為可能的模型決策提供忠實的視覺解釋。與嘗試解釋網路的所有這些方法不同,我們第一次建立端到端模型來直接對這些解釋提供監督,特別是網路的關注。我們驗證這些監督可以指導網路側重於我們所期望的區域,並從中獲益於相應的視覺任務。
Many methods heavlily rely on the location information provided by the network’s attention. Learning from only the image-level labels, attention maps of a trained classification network can be used for weakly-supervised object localization [17, 38], anomaly localization, scene segmentation [12] and etc.However, only trained with classification loss, the attention map only covers small and most discriminative regions of the object of interest, which deviates from the requirement of these tasks that needs to localize dense, interior and complete regions. To mitigate this gap,
許多方法依賴於網路關注的位置資訊。僅從影象級標籤中學習,訓練好的分類網路的注意圖可以用於弱監督物件定位[17,38],異常定位,場景分割[12]等。然而,只有經過分類損失訓練後,注意圖才會覆蓋感興趣物件的小型且最具區分性的區域,這偏離了需要對密集,內部和完整區域進行本地化的需求。為了緩解這一差距,
[28] proposes to hide patches in a training image randomly, forcing the network to seek other relevant parts when the most discriminative part is hidden. This approach can be considered as a way to augment the training data, and it has strong assumption on the size of foreground objects (i.e., the object size vs. the size of the patches). In [31], use the attention map of a trained network to erase the moset discriminative regions of the original input image. And the repeat this erase and discover action to the erased image for several steps and combine attention maps of each step to get a more complete attention map. Similarly, [11] uses a twophase learning stratge and combine attention maps of the two networks to get a more complete region for the object of interest. In the first step, a conventional fully convolutional network (FCN) [16] is trained to find the most discriminative parts of an image. Then these most salient parts are used to supresse the feature map of the secound network to force it to focus on the next most important parts. However, these methods either rely on combinations of attention maps of one trained network for different erased steps or attentions of different networks. The single network’s attention still only locates on the most discriminative region. Our proposed GAIN model is fundamentally different from the previous approaches. Since our models can provide supervision directly on network’s attention in an endto-end way, which can not be done by all the other methods [11, 24, 28, 31, 35, 38], we design different kinds of loss functions to guide the network focus on the whole object of interest. Therefore, we do not need to do several times erasing or combine attention maps. The attention of our single trained network is already more complete and improved.
[28]提出隨機地將補丁隱藏在訓練影象中,迫使網路在隱藏最具判別性的部分時尋找其他相關部分。這種方法可以被認為是增加訓練資料的一種方式,並且它對前景物件的大小(即,物件大小與片的大小)有很強的假設。在[31]中,使用訓練好的網路的注意圖擦除原始輸入影象的Moset區分割槽域。重複這個步驟擦除和發現擦除影象的幾個步驟,並結合每個步驟的注意圖來獲得更完整的注意圖。同樣,[11]使用雙相學習策略,並結合兩個網路的注意圖來獲得感興趣物件的更完整區域。在第一步中,傳統的完全卷積網路(FCN)[16]被訓練來找出影象中最具區分性的部分。然後,這些最突出的部分用於超越secound網路的特徵對映,以強制它專注於下一個最重要的部分。然而,這些方法要麼依賴於一個訓練網路的關注圖的組合,以用於不同的擦除步驟或不同網路的關注。單一網路的注意力仍然只位於最具有歧視性的地區。我們提出的GAIN模型與以前的方法有根本的不同。由於我們的模型可以通過端到端的方式直接監督網路的注意力,所有其他方法都無法做到這一點[11,24,28,31,35,38],我們設計了不同型別的損失函式來指導網路側重於整個感興趣的物件。因此,我們不需要多次擦除或合併注意力圖。我們單一的培訓網路的關注已經更加完善和改善。
Identifying bias in datasets [30] is another important usage of the network attention. [24] analyses the location of attention maps of a trained model to find out the dataset bias, which helps them to build a better unbiased dataset. However, in practical applications, it is hard remove all the bias of the dataset and time-consuming to build a new dataset. How to garantee the generalization ability of the learned network is still challenging. Different from the existing methods, our model can fundamentally solve this problem by providing supervision directly on network’s attention and guiding the network to focus on the areas critical to the task of interest, therefore is robust to dataset bias.
識別資料集中的偏見[30]是網路關注的另一個重要用途。 [24]分析了經過訓練的模型的關注圖的位置,以發現數據集偏差,這有助於他們建立一個更好的無偏差資料集。但是,在實際應用中,難以消除資料集的所有偏見,並且耗費時間來構建新的資料集。如何保證學習網路的泛化能力仍然具有挑戰性。與現有方法不同,我們的模型可以直接對網路的關注提供監督,並指導網路側重於感興趣任務的關鍵領域,從而從根本上解決這一問題,因此對資料集偏差具有強大的適用性。
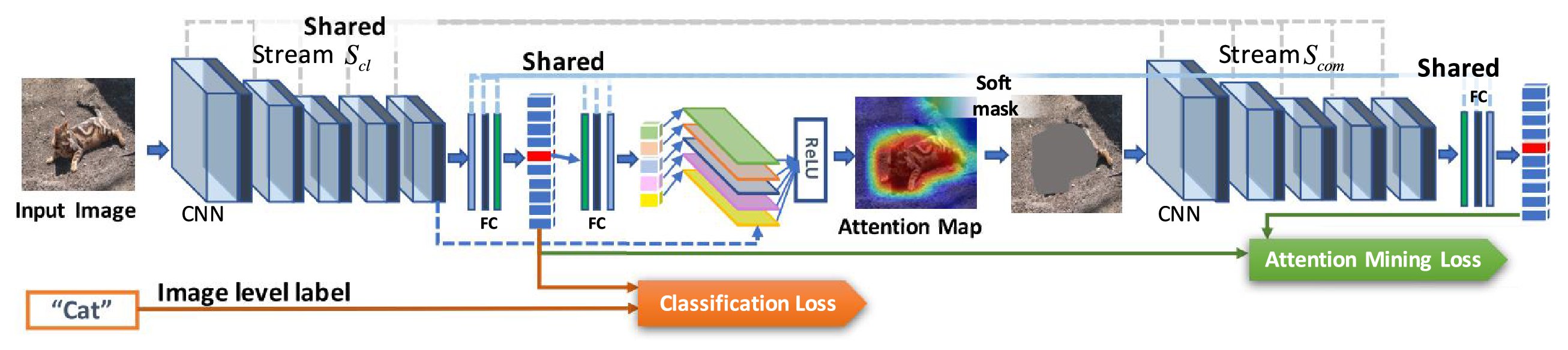
Figure 2. GAIN has two streams of networks, 

圖2. GAIN有兩個網路流,
3. Proposed method — GAIN
3.建議的方法 - GAIN
Since attention maps reflect the areas on input image which support the network’s prediction, we propose the guided attention inference networks (GAIN), which aims at supervising attention maps when we train the network for the task of interest. In this way, the network’s prediction is based on the areas which we expect the network to focus on. We achieve this by making the network’s attention trainable in an end-to-end fashion, which hasn’t been considered by any other existing works [11, 24, 28, 31, 35, 38]. In this section, we describe the design of GAIN and its extensions tailored towards tasks of interest.
由於注意對映反映了支援網路預測的輸入影象上的區域,因此我們提出了引導注意推理網路(GAIN),其目的是在我們針對感興趣的任務訓練網路時監督注意力圖。通過這種方式,網路的預測基於我們期望網路關注的領域。我們通過使網路的注意力以端到端的方式進行培訓來實現這一目標,這一點尚未被任何其他現有的作品所考慮[11,24,28,31,35,38]。在本節中,我們將描述GAIN的設計及其針對感興趣任務的擴充套件。
3.1. Self-guidance on the network attention
3.1。網路關注的自我指導
As mentioned in Section 2, attention maps of a trained classification network can be used as priors for weaklysupervised semantic segmentation methods. However, purely supervised by the classification loss, attention maps usually only cover small and most discriminative regions of object of interest.These attention maps can serve as reliable priors for segmentation but a more complete attention map can certainly help improving the overall performance.
如第2節所述,經過訓練的分類網路的注意圖可以用作弱監督語義分割方法的先驗。然而,純粹受到分類損失的監督,注意圖通常只覆蓋感興趣物件的小區域和最具區分性的區域。這些關注地圖可以作為分割的可靠先驗,但更完整的關注地圖肯定有助於改善整體表現。
To solve this issue, our GAIN builds constrains directly on the attention map in a regularized bootstrapping fashion. As shown in Figure 2, GAIN has two streams of networks, classification stream 


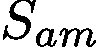
為了解決這個問題,我們的GAIN以正則化引導方式直接在注意力圖上形成約束。如圖2所示,GAIN有兩個網路流,分類流
Based on the fundemantal framework of Grad-CAM [24], we streamlined the generation of attention map. An attention map corresponding to the input sample can be obtained within each inference so it becomes trainable in training statge. In stream 


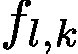

基於Grad-CAM [24]的福特框架,我們簡化了注意圖的生成。可以在每個推理中獲得與輸入樣本相對應的注意圖,從而在訓練統計中變得可訓練。在流
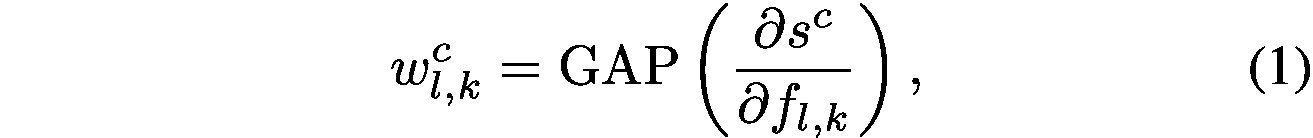
where 
Here, we do not update parameters of the network after obtaining the 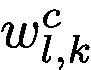
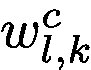
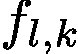
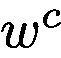
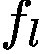
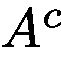
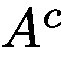
在這裡,我們不通過反向傳播獲得
where l is the representation from the last convolutional layer whose features have the best compromise between high-level semantics and detailed spatial information [26]. The attention map has the same size as the convolutional feature maps ( 
其中l是來自最後卷積層的表示,其特徵具有在高階語義和詳細空間資訊之間的最佳折衷[26]。注意圖具有與卷積特徵對映(VGG [27]情況下的
We then use the trainable attention map 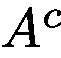
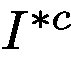
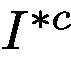
然後,我們使用可訓練注意圖
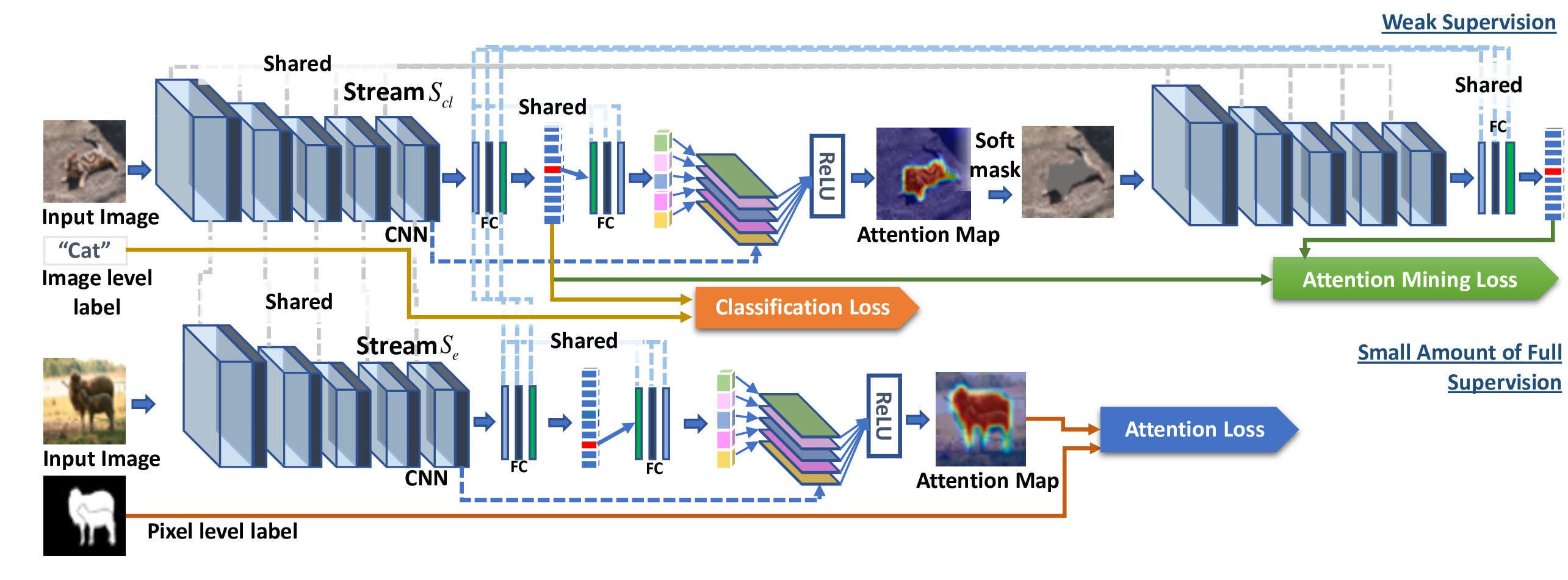
Figure 3. Framework of the GAINext. Pixel-level annotations are seamlessly integrated into the GAIN framework to provide direct supervision on attention maps optimizing towards the task of semantic segmentation.
圖3. GAINext的框架。畫素級註釋無縫整合到GAIN框架中,以提供對關注地圖優化的直接監督,以實現語義分割任務。
where ⊙ denotes element-wise multiplication. is a masking function based on a thresholding operation. In order to make it derivable, we use Sigmoid function as an approximation defined in Eq. 4.
其中⊙表示單元乘法。 是基於閾值操作的遮蔽功能。為了使其可導,我們使用Sigmoid函式作為方程中的近似值。 4。
where σ is the threshold matrix whose elements all equal to σ. ω is the scale parameter ensuring approximately equals to 1 when
is larger than σ, or to 0 otherwise.
其中σ是其元素都等於σ的閾值矩陣。 ω是尺度引數,確保當大於σ時
大約等於1,否則為0。
is then used as input of stream
to obtain the class prediction score. Since our goal is to guide the network to focus on all parts of the class of interest, we are enforcing
to contain as little feature belonging to the target class as possible, i.e. regions beyond the high-responding area on attention map area should include ideally not a single pixel that can trigger the network to recognize the object of class c. From the loss function perspective it is trying to minimize the prediction score of
for class c. To achieve this, we design the loss function called Attention Mining Loss as in Eq. 5.
然後將用作流
的輸入以獲得類別預測分數。由於我們的目標是引導網路關注所有感興趣的類別,我們正在強制
儘可能少地包含屬於目標類的特徵,即注意圖區域上的高響應區域之外的區域應該包括理想情況下不是一個可以觸發網路識別c類物件的畫素。從損失函式的角度來看,它試圖最小化
對c類的預測分數。為了達到這個目的,我們設計了稱為注意採礦損失的損失函式。 5。
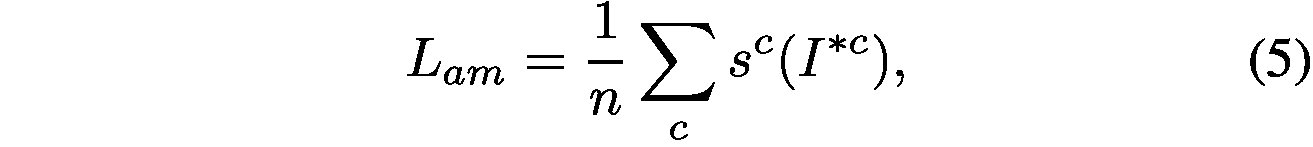
where denotes the prediction score of
for class c. n is the number of ground-truth class labels for this image I.
表示c類的
的預測分數。 n是該影象的地面實況類別標籤的數量。
As defined in Eq. 6, our final self-guidance loss is the summation of the classification loss
and
.
正如方程6,我們最終的自我指導損失是分類損失
和
的總和。
where is for multi-label and multi-class classification and we use a multi-label soft margin loss here. Alternative loss functions can be use for specific tasks. α is the weighting parameter. We use
in all of our experiments.
用於多標籤和多類分類,我們在這裡使用多標籤軟邊緣損失。替代損失函式可用於特定任務。 α是加權引數。我們在所有的實驗中都使用
。
With the guidance of , the network learn to extend the focus area on input image contributing to the recognition of target class as much as possible, such that attention maps are tailored towards the task of interest, i.e. semantic segmentation. We demonstrate the efficacy of GAIN with self guidance in Sec. 4.
在的指導下,網路學習擴大輸入影象的焦點區域,有助於儘可能識別目標類別,從而使注意圖譜適合於感興趣的任務,即語義分割。我們在第二部分展示了GAIN的自我指導的效用。 4。
3.2. GAINext: integrating extra supervision
3.2。 GAINext:整合額外的監督
In addition to letting networks explore the guidance of the attention map by itself, we can also tell networks which part in the image they should focus on by using a small amount of extra supervision to control the attention map learning process, so that to be tailored for the task of interest. Based on this idea of imposing additional supervision on attention maps, we introduce the extension of GAIN: GAINext, which can seamlessly integrate extra supervision in our weakly supervised learning framework. We demonstrate using the self-guided GAIN framework improving the weakly-supervised semantic segmentation task as shown in Sec. 4. Furthermore, we can also apply GAINext to guide the network to learn features robust to dataset bias and improve its generalizability when the testing data and training data are drawn from very different distributions.
除了讓網路自己探索關注地圖的指導之外,我們還可以通過使用少量額外的監督來控制注意地圖學習過程來告訴網路中他們應該關注的影象的哪些部分,以便定製為感興趣的任務。基於這種對關注圖進行額外監督的想法,我們引入GAIN:GAINext的擴充套件,它可以在我們的弱監督學習框架中無縫整合額外的監督。我們演示如何使用自導GAIN框架來改進弱監督語義分割任務,如第2節所示。 4。此外,我們還可以應用GAINext指導網路學習對資料集偏差具有魯棒性的特徵,並在測試資料和訓練資料來自非常不同的分佈時提高其泛化性。
Following Sec. 3.1, we still use the weakly supervised semantic segmentation task as an example application to explain the GAINext. The way to generate trainable attention maps in GAINext during training stage is the same as that in the self-guided GAIN. In addition to and
, we design another loss
based on the given external supervision. We define
as:
繼Sec。 3.1,我們仍然使用弱監督語義分割任務作為示例應用程式來解釋GAINext。GAINext在訓練階段生成可訓練關注地圖的方式與自引導GAIN相同。除了和
,我們還根據給定的外部監督設計了另一種損失
。我們將
定義為:
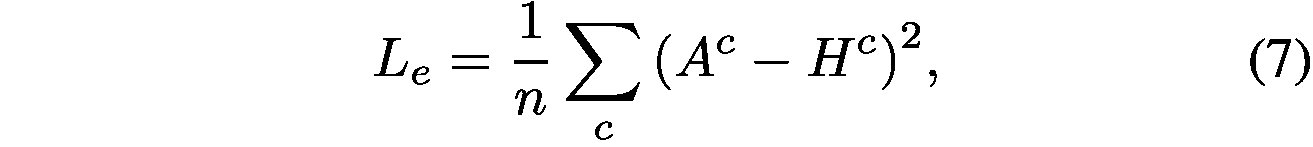
where denotes the extra supervision, e.g. pixel-level segmentation masks in our example case.
表示額外的監督,例如,我們的例子中的畫素級分割掩碼。
Since generating pixel-level segmentation maps is extremely time consuming, we are more interested in finding out the benefits of using only a very small amount of data with external supervision, which fits perfectly with the GAINext framework shown in Figure 3, where we add an external stream , and these three streams share all parameters. Input images of stream
include both image-level labels and pixel-level segmentation masks. One can use only very small amount of pixel-level labels through stream
to already gain performance improvement with GAINext (in our experiments with GAINext, only 1∼10% of the total labels used in training are pixel-level labels). The input of the stream
includes all the images in the training set with only image-level labels.
由於生成畫素級分割圖非常耗時,因此我們更感興趣的是發現只使用非常少量的外部監控資料的好處,這完全符合圖3中所示的GAINext框架,我們添加了外部流,並且這三個流共享所有引數。流
的輸入影象包括影象級標籤和畫素級分割掩碼。通過
流,只能使用非常少量的畫素級標籤,以增加GAINext的效能(在我們用GAINext進行的實驗中,訓練中使用的總標籤中只有1〜10%是畫素級標籤)。流
的輸入包括僅具有影象級標籤的訓練集中的所有影象。
The final loss function, , of GAINext is defined as follows: Lext = Lcl + αLam + ωLe, (8)
GAINext的最終損失函式定義如下:Lext = Lcl +αLam+ωLe,(8)
where and
are defined in Sec. 3.1, and ω is the weighting parameter depending on how much emphasis we want to place on the extra supervision (we use
in our experiments).
和
在第2節中定義。 3.1,而ω是權重引數,取決於我們希望在額外的監督下多加強調(我們在實驗中使用
)。
GAINext can also be easily modified to fit other tasks. Once we get activation maps corresponding to the network’s final output, we can use
to guide the network to focus on areas critical to the task of interest. In Sec. 5, we show an example of such modification to guide the network to learn features robust to dataset bias and improve its generalizability. In that case, extra supervision is in the form of bounding boxes.
GAINext也可以很容易地修改來完成其他任務。一旦我們得到與網路最終輸出相對應的啟用圖,我們就可以使用
來指導網路將重點放在對感興趣任務關鍵的區域。在第二部分5,我們展示了這種修改的例子,以指導網路學習對資料集偏倚強健的特徵並提高其泛化能力。在這種情況下,額外的監督就是邊界框的形式。
4. Semantic segmentation experiments
4.語義分割實驗
To verify the efficacy of GAIN, following Sec. 3.1 and 3.2, we use the weakly supervised semantic segmentation task as the example application. The goal of this task is to classify each pixel into different categories. In the weakly supervised setting, most of recent methods [11, 12, 31] mainly rely on localization cues generated by models trained with only image-level labels and consider other constraints such as object boundaries to train a segmentation network. Therefore, the quality of localization cues is the key of these methods’ performance.
為了驗證GAIN的有效性, 3.1和3.2,我們使用弱監督語義分割任務作為示例應用程式。此任務的目標是將每個畫素分為不同的類別。在弱監督環境下,最近的大多數方法[11,12,31]主要依賴於僅由影象級標籤訓練的模型生成的定位線索,並考慮其他約束(如物件邊界)來訓練分割網路。因此,定位線索的質量是這些方法表現的關鍵。
Compared with attention maps generated by the stateof-the-art methods [16, 24, 38] which only locate the most discriminative areas, GAIN guides the network to focus on entire areas representing the class of interest, which can improve the performance of weakly supervised segmentation. To verify this, we adopt our attention maps to SEC [12], which is one of the state-of-the-art weakly supervised semantic segmentation methods. SEC defines three key constrains: seed, expand and constrain, where seed is a module to provide localization cues C to the main segmentation network N such that the segmentation result of N is supervised to match C. Note that SEC is not a dependency of GAIN. It is used here in order to evaluate improvements brought by attention priors produced by GAIN. In principal it can be replaced by other segmentation frameworks for this application. Following SEC [12], our localization cues are obtained by applying a thresholding operation to attention maps generated by GAIN: for each per-class attention map, all pixels with a score larger than 20% of the maximum score are selected. We use [15] to get background cues and then train the SEC model to generate segmentation results using the same inference procedure, as well as parameters of CRF[13].
與最先進的方法[16,24,38]產生的注意力圖相比,GAIN只引導網路集中在代表感興趣等級的整個區域,這可以改善弱的表現監督分割。為了驗證這一點,我們將我們的注意力對映到SEC [12],這是最先進的弱監督語義分割方法之一。SEC定義了三個關鍵約束:種子,擴充套件和約束,其中種子是為主分割網路N提供定位線索C的模組,使得N的分割結果被監督以匹配C.注意,SEC不是GAIN的依賴性。它在此用於評估由GAIN生產的關注度先進帶來的改進。原則上它可以被這個應用程式的其他分割框架所取代。根據SEC [12],我們的定位線索是通過對由GAIN生成的注意圖應用閾值操作獲得的:對於每個每類注意圖,選擇具有大於最大分數的20%的分數的所有畫素。我們使用[15]獲得背景線索,然後訓練SEC模型以使用相同的推理過程生成分割結果,以及CRF引數[13]。
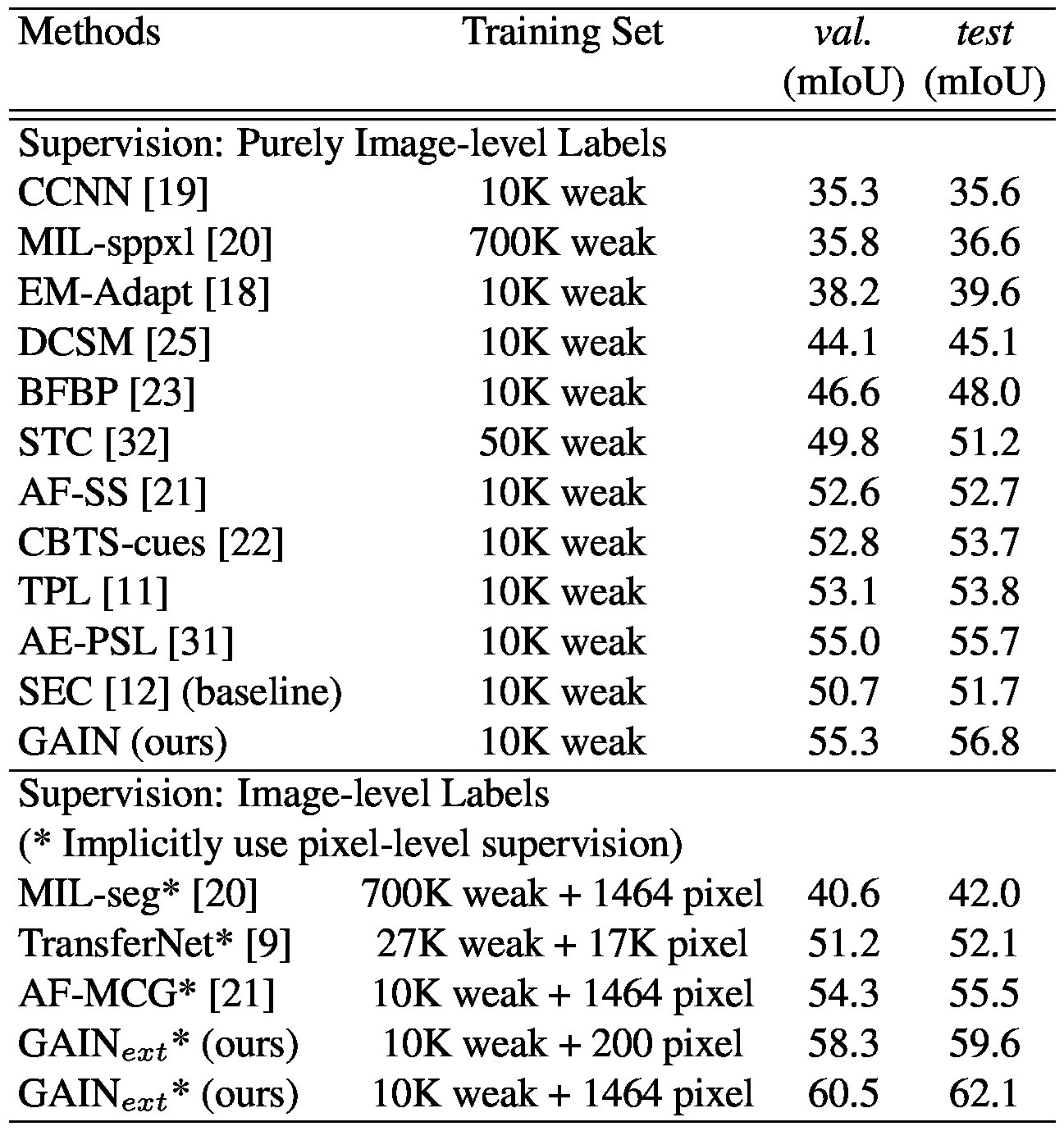
Table 1. Comparison of weakly supervised semantic segmentation methods on VOC 2012 segmentation val. set and segmentation test set. weak denotes image-level labels and pixel denotes pixellevel labels.Implicitly use pixel-level supervision is a protocol we followed as defined in [31], that pixel-level labels are only used in training priors, and only weak labels are used in the training of segmentation framework, e.g. SEC [12] in our case.
表1.比較弱監督的語義分割方法對VOC 2012分段值的影響。集和分割測試集。弱表示影象級標籤,畫素表示畫素級標籤。隱式地使用畫素級監督是我們遵循的[31]中定義的協議,畫素級標籤僅用於訓練先驗,而只有弱標籤用於分割框架的訓練。 SEC [12]在我們的案例中。
4.1. Dataset and experimental settings
4.1。資料集和實驗設定
Dataset and evaluation metrics. We evaluate our results on the PASCAL VOC 2012 image segmentation benchmark [6], which has 21 semantic classes, including the background. The images are split into three sets: training, validation, and testing (denoted as train, val, and test) with 1464, 1449, and 1456 images, respectively. Following the common setting [4, 12], we use the augmented training set provided by [8]. The resulting training set has 10582 weakly annotated images which we use to train our models.We compare our approach with other approaches on both the val and test sets. The ground truth segmentation masks for the test set are not publicly available, so we use the official PASCAL VOC evaluation server to obtain the quantitative results. For the evaluation metric, we use the standard one for the PASCAL VOC 2012 segmentation — mean intersection-over-union (mIoU).
資料集和評估指標。我們在PASCAL VOC 2012影象分割基準[6]上評估我們的結果,其中有21個語義類,包括背景。影象分為三組:訓練,驗證和測試(分別表示為train,val和test),分別為1464,1449和1456影象。遵循共同設定[4,12],我們使用[8]提供的增強訓練集。由此產生的訓練集有10582個弱註釋影象,我們用它來訓練我們的模型。我們將我們的方法與val和測試集上的其他方法進行比較。測試集的地面實況分割掩模並不公開,因此我們使用官方的PASCAL VOC評估伺服器來獲取定量結果。對於評估指標,我們使用PASCAL VOC 2012分割的標準指標 - 平均相交(mIoU)。
Implementation details. We use the VGG [27] pretrained from the ImageNet [5] as the basic network for GAIN to generate attention maps. We use Pytorch [1] to implement our models. We set the batch size to 1 and learning rate to . We use the stochastic gradient descent (SGD) to train the networks and terminate after 35 epochs. For the weakly-supervised segmentation framework, following the setting of SEC [12], we use the DeepLab-CRFLargeFOV [4], which is a slightly modified version of the VGG network [27]. Implemented using Caffe [10], DeepLab-CRFLargeFOV [4] takes the inputs of size 321×321 and produces the segmentation masks of size 41×41. Our training procedure is the same as [12] at this stage. We run the SGD for 8000 iterations with the batch size of 15. The initial learning rate is
and it decreases by a factor of 10 for every 2000 iterations.
實施細節。我們使用從ImageNet [5]預訓練的VGG [25]作為GAIN的基本網路來生成關注圖。我們使用Pytorch [1]來實現我們的模型。我們將批量大小設定為1,並將學習速率設定為。我們使用隨機梯度下降(SGD)來訓練網路,並在35個時期後終止。對於弱監督分割框架,在SEC [12]設定之後,我們使用DeepLab-CRFLargeFOV [4],這是VGG網路的稍微修改版本[27]。用Caffe [10]實現,DeepLab-CRFLargeFOV [4]採用尺寸為321×321的輸入,併產生大小為41×41的分割掩模。我們的訓練程式與現階段的[12]相同。我們以批量大小15執行8000次迭代的SGD。初始學習率是
,每2000次迭代它就會減少10倍。
4.2. Comparison with state-of-the-art
4.2。與最先進的技術進行比較
We compare our methods with other state-of-the-art weakly supervised semantic segmentation methods with image-level labels. Following [31], we separate them into two categories. For methods purely using image-level labels, we compare our GAIN-based SEC (denoted as GAIN in the table) with SEC [12], AE-PSL [31], TPL [11], STC
我們將我們的方法與其他最先進的弱監督語義分割方法與影象級標籤進行比較。在[31]之後,我們將它們分成兩類。對於純粹使用影象級標籤的方法,我們將我們的基於GAIN的SEC(在表中表示為GAIN)與SEC [12],AE-PSL [31],TPL [11],STC
[32] and etc. For another group of methods, implicitly using pixel-level supervision means that though these methods train the segmentation networks only with image-level labels, they use some extra technologies that are trained using pixel-level supervision. Our GAINext-based SEC (denoted as GAINext in the table) lies in this setting because it uses a very small amount of pixel-level labels to further improve the network’s attention maps and doesn’t rely on any pixel-level labels when training the SEC segmentation network. Other methods in this setting like AF-MCG [38], TransferNet [9] and MIL-seg [20] are included for comparison. Table 1 shows results on PASCAL VOC 2012 segmentation val. set and segmentation test. set.
[32]等。對於另一組方法,隱式使用畫素級監督意味著雖然這些方法僅使用影象級標籤訓練分割網路,但它們使用一些額外的技術,這些技術是使用畫素級監督進行訓練的。我們基於GAINext的SEC(在表格中表示為GAINext)位於此設定中,因為它使用非常少量的畫素級標籤來進一步改善網路的注意力圖,並且在訓練時不依賴任何畫素級標籤SEC分割網路。其他包括AF-MCG [38],TransferNet [9]和MIL-seg [20]在內的方法也包括在內以作比較。表1顯示了PASCAL VOC 2012分段值的結果。設定和分割測試。組。
Among the methods purely using image-level labels, our GAIN-based SEC achieves the best performance with 55.3% and 56.8% in mIoU on these two sets, outperforming the SEC [12] baseline by 4.6% and 5.1%. Furthermore, GAIN outperforms AE-PSL [31] by 0.3% and 1.1%, and outperforms TPL [11] by 2.2% and 3.0%. These two methods are also proposed to cover more areas of the class of interest in attention maps. However, they either rely on the combinations of attention maps of one trained network for different erasing steps [31] or attention maps from different networks [11].Compared with them, our GAIN makes the attention map trainable and uses loss to guide attention maps to cover entire class of interest. The design of GAIN already makes the attention map of a single network cover more areas belonging to the class of interest without the need to do iterative erasing or combining attention maps from different networks, as proposed in [11, 31].
在純粹使用影象級標籤的方法中,我們的基於GAIN的SEC在這兩組中的mIoU上達到最佳效能,其效能優於SEC [12]基準的4.6%和5.1%,達到55.3%和56.8%。此外,增益優於AE-PSL [31] 0.3%和1.1%,優於TPL [11] 2.2%和3.0%。這兩種方法也被提出來覆蓋關注地圖中感興趣類別的更多區域。然而,它們要麼依賴於一個訓練網路的注意圖組合來進行不同的擦除步驟[31]或者來自不同網路的注意圖[11]。與他們相比,我們的GAIN使得注意圖可訓練並使用損失來指導注意力圖以涵蓋整個興趣類別。如[11,31]中提出的,GAIN的設計已經使單個網路的注意圖覆蓋更多屬於感興趣類別的區域,而不需要執行迭代擦除或結合來自不同網路的注意圖。

Figure 4. Qualitive results on Pascal VOC 2012 segmentation val. set. They are generated by SEC (our baseline framework), our GAIN-based SEC and GAINext-based SEC implicitly using 200 randomly selected (2%) extra supervision.
圖4. Pascal VOC 2012分段值的質量結果組。它們由SEC(我們的基準框架),我們的基於GAIN的SEC和基於GAINext的SEC隱式地使用200個隨機選擇的(2%)額外監督而生成。
By implicitly using pixel-level supervision, our GAINext-based SEC achieves 58.3% and 59.6% in mIoU when we use 200 randomly selected images with pixel-level labels (2% data of the whole dataset) as the pixel-level supervision. It already performs 4% and 4.1% better than AF-MCG [38], which relies on the MCG generator [2] trained in a fully-supervised way on the PASCAL VOC. When the pixel-level supervision increases to 1464 images for our GAINext, the performance jumps to 60.5% and 62.1%, which is a new state-of-the-art for this challenging task on a competitive benchmark. Figure 4 shows some qualitative example results of semantic segmentation, indicating that GAIN-based methods help to discover more complete and accurate areas of classes of interest based on the improvement of attention maps. Specifically, GAIN-based methods discover either other parts of objects of interest or new instances which can not be found by the baseline.
通過隱式使用畫素級監督,當我們使用200個隨機選擇的畫素級標籤(整個資料集的2%資料)作為畫素級監督時,基於GAINext的SEC在mIoU中達到58.3%和59.6%。它已經比AF-MCG的效能提高了4%和4.1%[38],它依靠MCG發生器[2],以全監督的方式對PASCAL VOC進行培訓。當畫素級監控增加到GAINext的1464張影象時,效能跳躍到60.5%和62.1%,這對於具有競爭力的基準測試來說是一項新的挑戰性任務。圖4顯示了語義分割的一些定性例項結果,表明基於GAIN的方法有助於根據關注對映的改進發現更加完整和準確的感興趣類別區域。具體而言,基於GAIN的方法會發現感興趣物件的其他部分或基線無法找到的新例項。
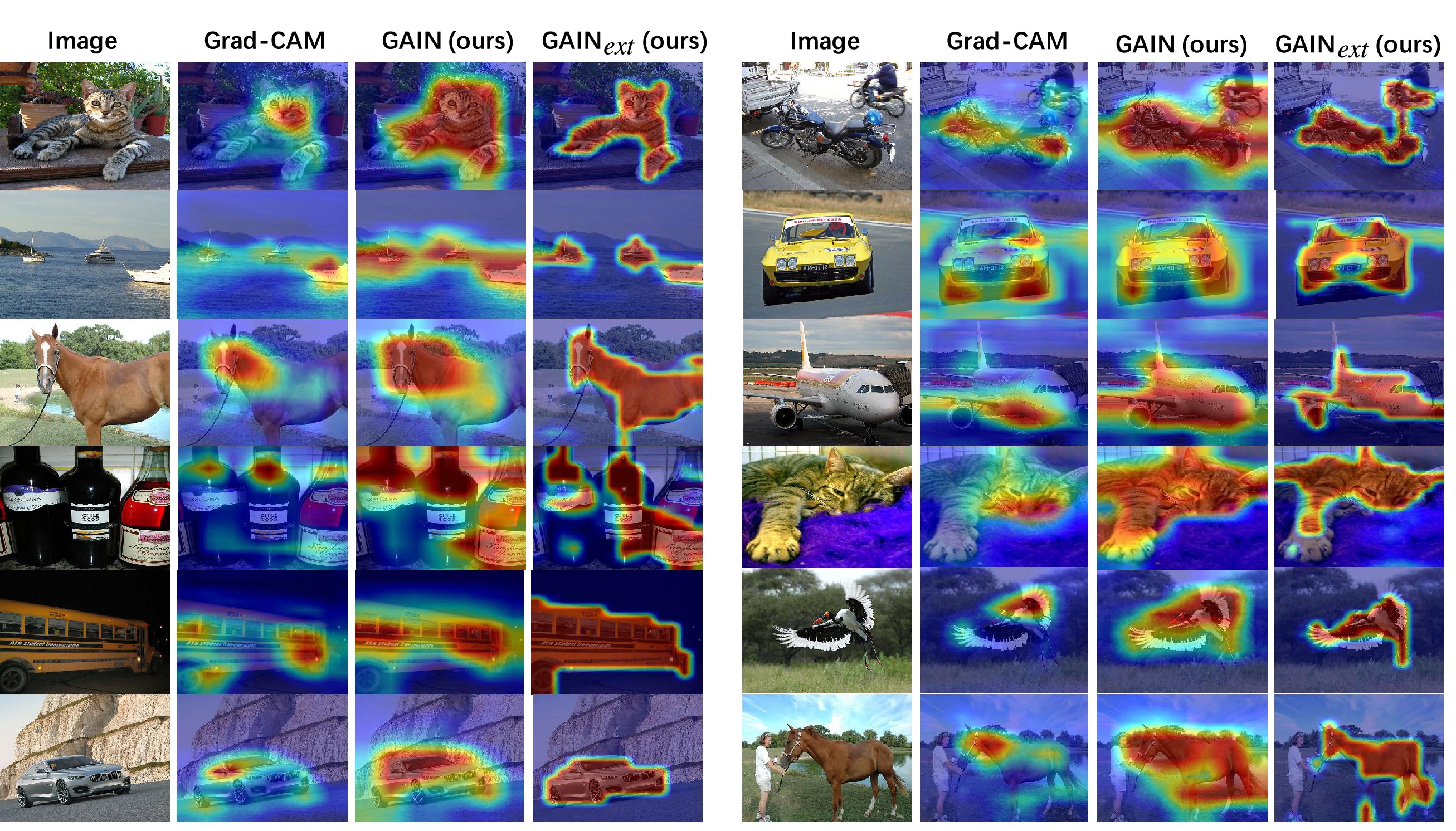
Figure 5. Qualitative results of attention maps generated by Grad-CAM [24], our GAIN and GAINext using 200 randomly selected (2%) extra supervision.
圖5. Grad-CAM生成的關注圖的定性結果[24],我們的GAIN和GAINext使用200個隨機選擇的(2%)額外監督。

We also show qualitative results of attention maps generated by GAIN-base methods in Figure 5, where GAIN covers more areas belonging to the class of interest compared with the Grad-CAM [24]. With only 2% of the p