
scrapy rule follow的理解和應用
阿新 • • 發佈:2018-12-22
follow 是一個布林(boolean)值,指定了根據該規則從response提取的連結是否需要跟進。 如果callback 為None,follow 預設設定為 True ,添加回調函式callback後為 False,不跟蹤
一句話解釋:follow可以理解為回撥自己的回撥函式
舉個例子,如百度百科,從任意一個詞條入手,抓取詞條中的超連結來跳轉,rule會對超連結發起requests請求,如follow為True,scrapy會在返回的response中驗證是否還有符合規則的條目,繼續跳轉發起請求抓取,周而復始,如下圖
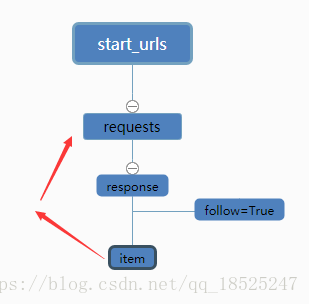
程式碼實現:
from scrapy.linkextractors import LinkExtractor from scrapy.spiders.crawl import Rule, CrawlSpider class BaiDuSpider(CrawlSpider): name = "baidu_spider" start_urls = ['https://baike.baidu.com/item/Python/407313?fr=aladdin'] '''獲取url''' rules = ( Rule(LinkExtractor(restrict_xpaths='//*[@class="para"]//a')), ) print(rules)
ps: 爬取百度百科時需要在setting中設定不遵守robots規則: ROBOTSTXT_OBEY = False