
機器學習實戰(2)—— k-近鄰演算法

老闆:來了,老弟!
我:來了來了。
老闆:今天你要去看看KNN了,然後我給你安排一個工作!
我:好嘞!就是第二章嗎?
老闆:對!去吧!
可惡的老闆又給我安排任務了!
《機器學習實戰》這本書中的第二章為我們介紹了K-近鄰演算法,這是本書中第一個機器學習演算法,它非常有效而且易於掌握,所以可以算是入門級演算法了。
那我們現在就一起去學習一下!
2.1 k-近鄰演算法概述
簡單的說,k-近鄰演算法採用測量不同特徵值之間的距離進行分類。
其工作原理是:
- 存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中的每一資料與所屬分類的對應關係。
- 輸入沒有標籤的新資料後,將新資料的每個特徵與樣本集中對應的資料對應的特徵進行比較,然後演算法提取出樣本集中特徵最相似資料(最近鄰)的分類標籤。(一般來說,我們只選擇樣本資料集中前k個最相似的資料,這就是k-近鄰演算法中k的出處,通常k是不大於20的整數。)
- 最後,我們選擇k個最相似資料中出現次數最多的分類,作為新資料的分類。
其實,光看概念,還是比較抽象的。那麼接下來,我們來看一個例子(原諒我思維沒有那麼豐富,就給大家說一下書中的例子吧,但我稍微做了一些修改,使其更形象一些)。書中的例子也不難,就是一個簡單的電影題材分類問題。
老闆:小韓啊,看完KNN的原理了吧?
我:看完了!
老闆:那我先給你一個簡單的任務。
我:≧ ﹏ ≦
老闆:你先去預測一下新上映的電影《諾手的愛情》是什麼題材的。
我:(啥,這是什麼鬼?)沒問題沒問題!
老闆給了一個已知電影題材的資料集,這也就是我們的訓練樣本集,其中只有兩種型別的電影:愛情片和動作片。好,第一步,我們先來看看資料:
| 電影名稱 | 打鬥鏡頭 | 接吻鏡頭 | 電影型別 |
|---|---|---|---|
| 蓋倫的愛情 | 3 | 104 | 愛情片 |
| 蓋倫的愛情2 | 2 | 100 | 愛情片 |
| 蓋倫的愛情3 | 1 | 81 | 愛情片 |
| 諾手VS奧特曼 | 101 | 10 | 動作片 |
| 諾手VS葫蘆娃 | 99 | 5 | 動作片 |
| 諾手VS豬豬俠 | 98 | 2 | 動作片 |
| 諾手的愛情 | 18 | 90 | ??? |
我們現在知道每部電影的兩個特徵,一個是打鬥鏡頭次數,一個是接吻鏡頭次數。那麼,根據KNN的原理,我們就需要計算《蓋倫VS諾手》,也就是未知電影與樣本集中其他電影的距離。我們先不看怎麼計算距離(後面算會提供),我們先來看結果。
| 電影名稱 | 與未知電影的距離 |
|---|---|
| 蓋倫的愛情 | 20.5 |
| 蓋倫的愛情2 | 18.7 |
| 蓋倫的愛情3 | 19.2 |
| 諾手VS奧特曼 | 115.3 |
| 諾手VS葫蘆娃 | 117.4 |
| 諾手VS豬豬俠 | 118.9 |
好了,經過一番計算,我們得到了樣本集中所有電影與未知電影的距離,按照距離遞增排序,可以找到k個距離最近的電影。
我們假設k=3,那麼距離最近的三部電影分別是:蓋倫的愛情,蓋倫的愛情2,蓋倫的愛情3。這三部電影都是愛情片,所以我們判定《諾手的愛情》是愛情片!
Bingo!!!老闆說,加雞腿!!!
好了,老闆也加雞腿了,流程也走完了,放假了!!!等等,好像少了點啥???少了程式碼怎麼行!!!
老闆佈置了新的任務,用Python程式碼實現K-近鄰演算法。沒事,不要慌,慢慢來
2.1.1 準備:使用Python匯入資料
首先,新建一個名為kNN.py的檔案,寫入以下程式碼:
from numpy import *
import operator
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels在上面的程式碼中,我們匯入了兩個模組:第一個是科學計算包NumPy;第二個是運算子模組,k-近鄰演算法執行排序操作時將使用這個模組提供的函式。
createDataSet()函式,顧名思義,我們可以看出,這個函式用來建立資料集,與此同時,也建立了對應的標籤。group就是我們的資料集,而每一條資料對應的類別標籤就是labels。
接下來,寫好程式碼後,我們先測試一下。不管你用什麼電腦,我們都先進入python互動式環境,然後輸入下列命令匯入上面編輯的程式模組:
>>> import kNN然後,我們繼續輸入以下命令,建立兩個變數,分別代表資料集和標籤。
>>> group, labels = kNN.createDataSet()在python命令提示符下,輸入變數的名字以檢驗是否正確的定義變數:
>>> group
array([[1. , 1.1],
[1. , 1. ],
[0. , 0. ],
[0. , 0.1]])>>> labels
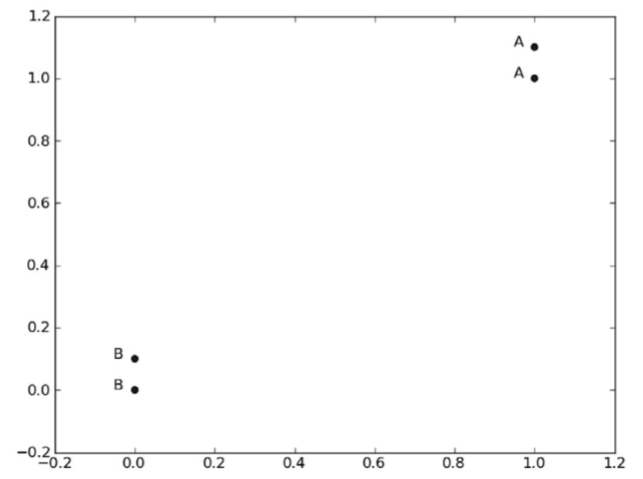
['A', 'A', 'B', 'B']這裡定義了4組資料,每組資料有兩個我們已知的屬性或者特徵值。上面的group矩陣每行包含一個不同的資料,由於人類大腦的限制, 我們通常只能視覺化處理三維以下的事務。因此為了簡單地實現資料視覺化,對於每個資料點我 們通常只使用兩個特徵。
向量labels包含了每個資料點的標籤資訊,labels包含的元素個數等於group矩陣行數。這裡我們將資料點(1, 1.1)定義為類A,資料點(0, 0.1)定義為類B。為了說明方便,例子中的數值是任意選擇的,並沒有給出軸標籤,圖2-2是帶有類標籤資訊的四個資料點。
表格形式:
| 資料點 | 特徵1 | 特徵2 | 類別 |
|---|---|---|---|
| 1 | 1.0 | 1.1 | A |
| 2 | 1.0 | 1.0 | A |
| 3 | 0 | 0 | B |
| 4 | 0 | 0.1 | B |
圖表形式(引用書中內容):
好了,我們已經知道了Python如何解析資料、載入資料以及kNN演算法的工作原理,接下來我們就用這些方法編寫KNN分類演算法。
2.1.2 實施kNN分類演算法
首先,我們先來看一下k-近鄰演算法的虛擬碼:
對未知類別屬性的資料集中的每個點依次執行以下操作:
(1) 計算已知類別資料集中的點與當前點之間的距離;
(2) 按照距離遞增次序排序;
(3) 選取與當前點距離最小的k個點;
(4) 確定前k個點所在類別的出現頻率;
(5) 返回前k個點出現頻率最高的類別作為當前點的預測分類。 然後,我們再來看一下實際的Python程式碼:
# inX: 分類的輸入向量
# dataSet: 輸入的訓練樣本集
# labels: 標籤向量
# k: 選擇最近鄰居的數目
def classify0(inX, dataSet, labels, k):
# 1.計算距離,這裡採用的是歐式距離
dataSetSize = dataSet.shape[0] # 獲取資料集大小,也就是有多少條資料
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 將待測試資料擴充套件
sqDiffMat = diffMat ** 2 # 差值矩陣中,矩陣元素分別平方
sqDistances = sqDiffMat.sum(axis = 1) # 橫向求和,得到矩陣
distances = sqDistances ** 0.5 # 矩陣中,每個元素都開方
sortedDistIndicies = distances.argsort() # 距離排序
# 2.選擇距離最小的k個點
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 3.排序
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=Ture)
return sortedClassCount[0][0]上述程式碼中有幾點需要解釋一下,也是我在學習的過程中查閱相關資料的地方。
第一,tile函式:
Numpy的 tile() 函式,就是將原矩陣橫向、縱向地複製。
定義原矩陣:
>>> originMat = array([[1, 3], [2, 4]])橫向:
>>> tile(originMat, 4) array([[1, 3, 1, 3, 1, 3, 1, 3], [2, 4, 2, 4, 2, 4, 2, 4]])縱向:
>>> tile(originMat, (3, 1)) array([[1, 3], [2, 4], [1, 3], [2, 4], [1, 3], [2, 4]])橫向 + 縱向:
>>> tile(originMat, (3, 2)) array([[1, 3, 1, 3], [2, 4, 2, 4], [1, 3, 1, 3], [2, 4, 2, 4], [1, 3, 1, 3], [2, 4, 2, 4]])
第二,歐式距離,兩個點的歐式距離公式如下:
$$
d = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}
$$
第三,分組後的排序。將classCount字典分解為元組列表,然後使用程式第二行匯入運算子模組的itemgetter方法,按照第二個元素的次序對元組進行排序 。此處的排序為逆序,即從大到小排序。
到現在為止,我們已經構造了第一個分類器,使用這個分類器可以完成很多分類任務。從這個例項出發,構造使用分類演算法將會更加容易。
搞定!!!老闆這次給我們加了一瓶可樂!!!有雞腿有可樂!!!美滋滋!!!
2.1.3 如何測試分類器
我們在老闆的安排下,已經使用k-近鄰演算法構造了第一個分類器,也可以檢驗分類器給出的答案是否符合我們的預期。
但是,分類器並不會得到百分百正確的結果,我們可以使用多種方法檢測分類器的正確率。 此外分類器的效能也會受到多種因素的影響,如分類器設定和資料集等。不同的演算法在不同資料集上的表現可能完全不同。
那麼,問題來了,我們該如何測試分類器的效果呢?其中一種方法就是錯誤率。這是一種比較常用的評估方法,主要用於評估分類器在某個資料集上的執行效果。後面我們還會遇到更加適合的方法來測試分類器,但這裡我們先只介紹錯誤率。
$$
錯誤率 = \frac {分類器給出錯誤結果的次數} {預測執行的總數}
$$
我們在已知答案的資料上進行測試,當然答案不能告訴分類器,檢驗分類器給出的結果是否符合預期結果。簡單點說,我們用KNN訓練出來了一個分類器,然後我們再把訓練集丟到分類器裡面,看看分類器的分類效果。
到現在,老闆給出的任務我們也完成了,程式碼也寫了一部分,也掌握了kNN演算法的基本使用,還是很開心的!!
但是,老闆又來了。
老闆:小韓啊,你這個分類器倒是出來了,但是隻在你自己捏造的資料集上執行,不行啊!!
我:(什麼?敢說我的演算法不行!!!)
老闆:這樣吧,明天我給你安排一個實在一點的任務,去改進一下約會網站的配對效果。
我:約會網站?聽起來不錯啊!那加雞腿不?
老闆:不加!!!
我: ̄へ ̄,老闆,我先下班了,明天見!!!
最後,歡迎大家關注我的公眾號,有什麼問題也可以給我留言哦!
