
使用scrapy爬取知乎問題和答案的相關欄位完整程式碼
阿新 • • 發佈:2019-02-06
目前程式健壯性有待提高。尤其是對question的各類異常處理還不夠。但是程式碼已經可用,附上程式碼執行後爬取到的資料。
在爬取到101條quetion時已經爬取到2671條answer欄位了。。。。這差距好大。一方面是因為answer有知乎提供的API,更方便爬取,另一個方面就是question的好多異常情況我沒有處理,碰到這些異常時就不會寫入資料庫。這是我今後需要思考,提高的方向。暫時就這樣子。
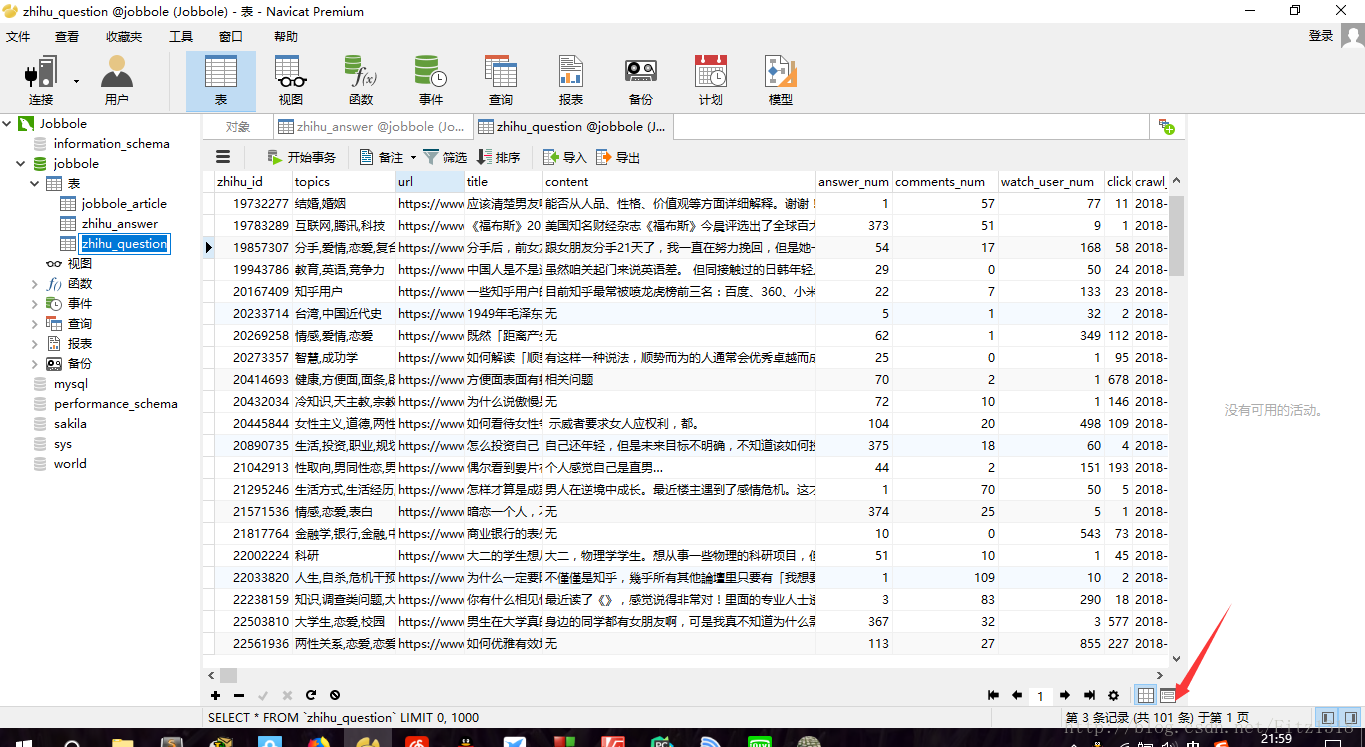
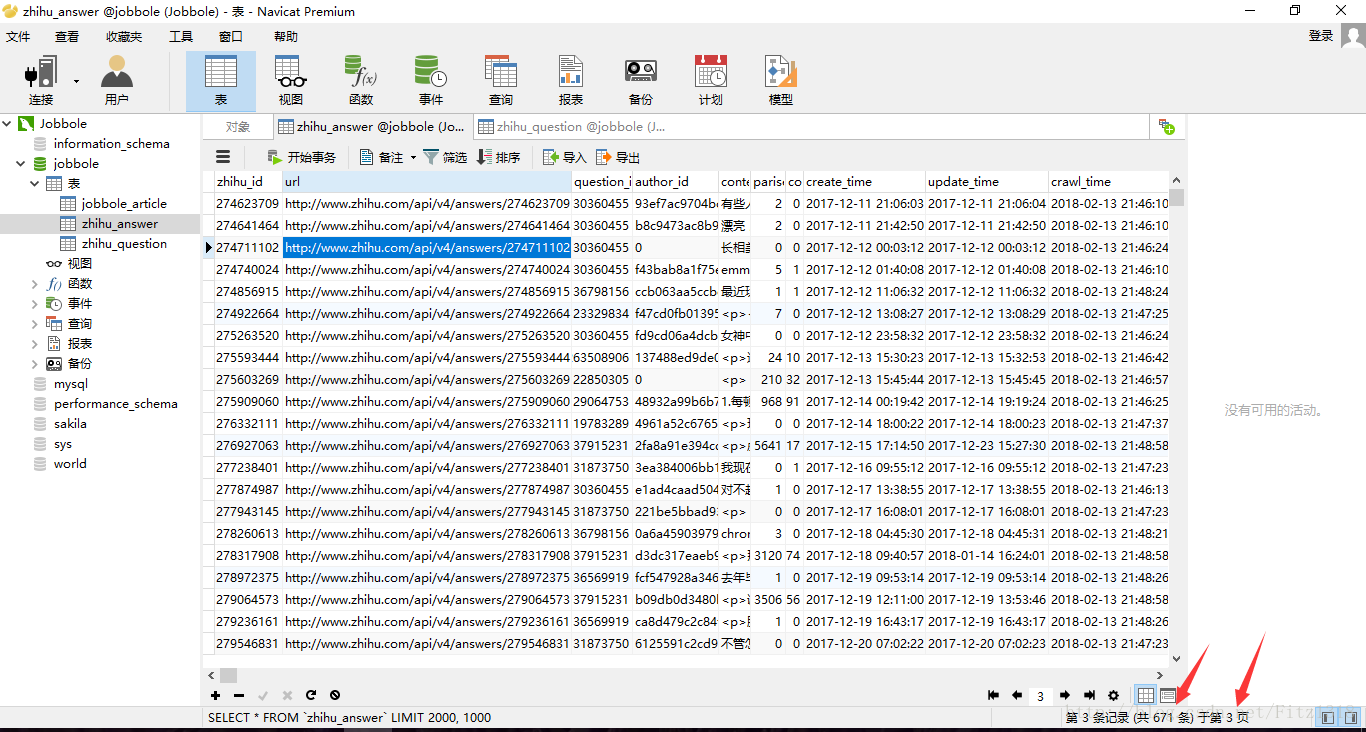
main.py
# -*- coding: utf-8 -*- from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) #execute(["scrapy", "crawl", "jobbole"]) execute(["scrapy", "crawl", "zhihu"])
zhihu.py
# -*- coding: utf-8 -*- import re import json import datetime try: import urlparse as parse except: from urllib import parse import scrapy from scrapy.loader import ItemLoader from items import ZhihuQuestionItem, ZhihuAnswerItem class ZhihuSpider(scrapy.Spider): name = "zhihu" allowed_domains = ['www.zhihu.com'] start_urls = ['https://www.zhihu.com/'] # question的第一頁answer的請求url start_answer_url = "https://www.zhihu.com/api/v4/questions/{0}/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccollapsed_counts%2Creviewing_comments_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Cmark_infos%2Ccreated_time%2Cupdated_time%2Crelationship.is_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.author.is_blocking%2Cis_blocked%2Cis_followed%2Cvoteup_count%2Cmessage_thread_token%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit={1}&offset={2}" headers = { "HOST": "www.zhihu.com", "Referer": "https://www.zhizhu.com", 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0" } custom_settings = { "COOKIES_ENABLED": True, #"DOWNLOAD_DELAY": 1.5, } def parse(self, response): """ 提取出html頁面中的所有url 並跟蹤這些url進行一步爬取 如果提取的url中格式為 /question/xxx 就下載之後直接進入解析函式 """ all_urls = response.css("a::attr(href)").extract() all_urls = [parse.urljoin(response.url, url) for url in all_urls] all_urls = filter(lambda x: True if x.startswith("https") else False, all_urls) for url in all_urls: match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", url) if match_obj: # 如果提取到question相關的頁面則下載後交由提取函式進行提取 request_url = match_obj.group(1) yield scrapy.Request(request_url, headers=self.headers, callback=self.parse_question) else: # 如果不是question頁面則直接進一步跟蹤 yield scrapy.Request(url, headers=self.headers, callback=self.parse) def parse_question(self, response): # 處理question頁面, 從頁面中提取出具體的question item if "QuestionHeader-title" in response.text: # 處理新版本 match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", response.url) if match_obj: question_id = int(match_obj.group(2)) item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response) item_loader.add_css("title", ".QuestionHeader-title::text") item_loader.add_xpath("content", "//*[@class='QuestionHeader-detail']/div/div/span/text()") item_loader.add_value("url", response.url) item_loader.add_value("zhihu_id", question_id) item_loader.add_css("answer_num", ".List-headerText span::text") item_loader.add_css("comments_num", ".QuestionHeader-Comment button::text") item_loader.add_css("watch_user_num", ".NumberBoard-itemValue::text") item_loader.add_css("topics", ".QuestionHeader-topics .Popover div::text") question_item = item_loader.load_item() else: # 處理老版本頁面的item提取 match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", response.url) if match_obj: question_id = int(match_obj.group(2)) item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response) item_loader.add_xpath("title", "//*[@id='zh-question-title']/h2/a/text()|//*[@id='zh-question-title']/h2/span/text()") item_loader.add_css("content", "#zh-question-detail") item_loader.add_value("url", response.url) item_loader.add_value("zhihu_id", question_id) item_loader.add_css("answer_num", "#zh-question-answer-num::text") item_loader.add_css("comments_num", "#zh-question-meta-wrap a[name='addcomment']::text") item_loader.add_xpath("watch_user_num", "//*[@id='zh-question-side-header-wrap']/text()|//*[@class='zh-question-followers-sidebar']/div/a/strong/text()") item_loader.add_css("topics", ".zm-tag-editor-labels a::text") question_item = item_loader.load_item() yield scrapy.Request(self.start_answer_url.format(question_id, 20, 0), headers=self.headers, callback=self.parse_answer) yield question_item def parse_answer(self, reponse): #處理questiona的answer ans_json = json.loads(reponse.text) is_end = ans_json["paging"]["is_end"] next_url = ans_json["paging"]["next"] #提取answer的具體欄位 for answer in ans_json["data"]: answer_item = ZhihuAnswerItem() answer_item["zhihu_id"] = answer["id"] answer_item["url"] = answer["url"] answer_item["question_id"] = answer["question"]["id"] answer_item["author_id"] = answer["author"]["id"] if "id" in answer["author"] else None #使用者匿名時id這個欄位就為空 answer_item["content"] = answer["content"] if "content" in answer else None #有些情況下cotent欄位也為空 answer_item["parise_num"] = answer["voteup_count"] answer_item["comments_num"] = answer["comment_count"] answer_item["create_time"] = answer["created_time"] answer_item["update_time"] = answer["updated_time"] answer_item["crawl_time"] = datetime.datetime.now() yield answer_item if not is_end: yield scrapy.Request(next_url, headers=self.headers, callback=self.parse_answer) #非同步I/O,通過callback執行下一步 def start_requests(self): from selenium import webdriver browser = webdriver.Chrome(executable_path="C:/Users/Fitz/Desktop/software/chromedriver.exe") browser.get("https://www.zhihu.com/signin") browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper Input").send_keys( "XXXXXX")#你的賬號 browser.find_element_by_css_selector(".SignFlow-password Input").send_keys( "XXXXXX")#你的密碼 browser.find_element_by_css_selector(".Button.SignFlow-submitButton").click() import time time.sleep(10) Cookies = browser.get_cookies() print(Cookies) cookie_dict = {} import pickle for cookie in Cookies: # 寫入檔案 f = open('C:/Users/Fitz/Desktop/scrapy/ArticleSpider/cookies/zhihu/' + cookie['name'] + '.zhihu', 'wb') pickle.dump(cookie, f) f.close() cookie_dict[cookie['name']] = cookie['value'] browser.close() return [scrapy.Request(url=self.start_urls[0], dont_filter=True, cookies=cookie_dict, headers=self.headers)]
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import datetime import re import scrapy from scrapy.loader import ItemLoader from scrapy.loader.processors import MapCompose, TakeFirst, Join from ArticleSpider.utils.common import extract_num#這裡的路徑要弄清楚 from ArticleSpider.settings import SQL_DATE_FORMAT, SQL_DATETIME_FORMAT#路徑 class ArticlespiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass # 排除none值 def exclude_none(value): if value: return value else: value = "無" return value def date_convert(value): try: create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() return create_date def get_nums(value): match_re = re.match(".*?(\d+).*", value) if match_re: nums = int(match_re.group(1)) else: nums = 0 return nums def return_value(value): return value def remove_comment_tags(value): #去掉tag中提取的評論 if "評論" in value: return "" else: return value class ArticleItemLoader(ItemLoader): #自定義itemloader default_output_processor = TakeFirst() class ZhihuQuestionItem(scrapy.Item): #知乎的問題 item zhihu_id = scrapy.Field() topics = scrapy.Field() url = scrapy.Field() title = scrapy.Field() content = scrapy.Field( input_processor=MapCompose(exclude_none), ) answer_num = scrapy.Field() comments_num = scrapy.Field() watch_user_num = scrapy.Field() click_num = scrapy.Field() crawl_time = scrapy.Field() def get_insert_sql(self): #插入知乎question表的sql語句 insert_sql = """ insert into zhihu_question(zhihu_id, topics, url, title, content, answer_num, comments_num, watch_user_num, click_num, crawl_time ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(content), answer_num=VALUES(answer_num), comments_num=VALUES(comments_num), watch_user_num=VALUES(watch_user_num), click_num=VALUES(click_num) """ zhihu_id = self["zhihu_id"][0] topics = ",".join(self["topics"]) url = self["url"][0] title = "".join(self["title"]) try: content = "".join(self["content"]) except BaseException: content = "無" answer_num = extract_num("".join(self["answer_num"])) comments_num = extract_num("".join(self["comments_num"])) if len(self["watch_user_num"]) == 2: watch_user_num = extract_num(self["watch_user_num"][0]) click_num = extract_num(self["watch_user_num"][1]) else: watch_user_num = extract_num(self["watch_user_num"][0]) click_num = 0 crawl_time = datetime.datetime.now().strftime(SQL_DATETIME_FORMAT) params = (zhihu_id, topics, url, title, content, answer_num, comments_num, watch_user_num, click_num, crawl_time) return insert_sql, params class ZhihuAnswerItem(scrapy.Item): #知乎的問題回答item zhihu_id = scrapy.Field() url = scrapy.Field() question_id = scrapy.Field() author_id = scrapy.Field() content = scrapy.Field() parise_num = scrapy.Field() comments_num = scrapy.Field() create_time = scrapy.Field() update_time = scrapy.Field() crawl_time = scrapy.Field() def get_insert_sql(self): #插入知乎answer表的sql語句 insert_sql = """ insert into zhihu_answer(zhihu_id, url, question_id, author_id, content, parise_num, comments_num, create_time, update_time, crawl_time ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(content), comments_num=VALUES(comments_num), parise_num=VALUES(parise_num), update_time=VALUES(update_time) """ create_time = datetime.datetime.fromtimestamp(self["create_time"]).strftime(SQL_DATETIME_FORMAT) update_time = datetime.datetime.fromtimestamp(self["update_time"]).strftime(SQL_DATETIME_FORMAT) params = ( self["zhihu_id"], self["url"], self["question_id"], self["author_id"], self["content"], self["parise_num"], self["comments_num"], create_time, update_time, self["crawl_time"].strftime(SQL_DATETIME_FORMAT), ) return insert_sql, params
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
import MySQLdb
import MySQLdb.cursors
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exporters import JsonItemExporter
from twisted.enterprise import adbapi
class ArticlespiderPipeline(object):
def process_item(self, item, spider):
return item
class JsonWithEncodingPipeline(object):
#自定義json檔案的匯出
def __init__(self):
self.file = codecs.open('article.json', 'w', encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"#確保中文顯示正常
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()
class JsonExporterPipeline(object):
#呼叫scrapy提供的json export 匯出json檔案
def __init__(self):
self.file = open('articleexport.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding = "utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"#確保中文顯示正常
self.exporter.export_item(item)
return item
def close_spider(self,spider):
self.exporter.finish_exporting()
class MysqlPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect('localhost', 'root', '1234', 'jobbole', charset = 'utf8', use_unicode = True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into jobbole_article(title, create_date, url, fav_nums)
VALUES (%s, %s, %s, %s)
"""
self.cursor.execute(insert_sql, (item["title"], item["create_date"], item["url"], item["fav_nums"]))
self.conn.commit()
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted將mysql插入變成非同步執行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #處理異常
def handle_error(self, failure, item, spider):
# 處理非同步插入的異常
print (failure)
def do_insert(self, cursor, item):
#執行具體的插入
#根據不同的item 構建不同的sql語句並插入到mysql中
insert_sql, params = item.get_insert_sql()
cursor.execute(insert_sql, params)
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self,results,item,info):
if "front_image_url" in item:
for ok,value in results:
image_file_path = value["path"]
item["front_image_path"] = image_file_path
return item
settings.py
# -*- coding: utf-8 -*-
import os
# Scrapy settings for ArticleSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'ArticleSpider'
SPIDER_MODULES = ['ArticleSpider.spiders']
NEWSPIDER_MODULE = 'ArticleSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'ArticleSpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
#ITEM_PIPELINES = {
# 'ArticleSpider.middlewares.ArticlespiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'ArticleSpider.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
#'scrapy.pipelines.images.ImagesPipeline': 1,
#'ArticleSpider.pipelines.ArticleImagePipeline': 2,
# 'ArticleSpider.pipelines.JsonExporterPipeline': 2,
'ArticleSpider.pipelines.MysqlTwistedPipeline': 1
}
IMAGES_URLS_FIELD = "front_image_url"
project_dir = os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir,'images')
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
MYSQL_HOST = "localhost"
MYSQL_DBNAME = "jobbole"
MYSQL_USER = "root"
MYSQL_PASSWORD = "1234"
SQL_DATETIME_FORMAT = "%Y-%m-%d %H:%M:%S"
SQL_DATE_FORMAT = "%Y-%m-%d"