
Python資料視覺化之資料密度分佈
阿新 • • 發佈:2019-02-11
Python資料視覺化(一)
之資料密度分佈
資料密度分佈是資料的主要特徵之一,Python中有幾種方法可以對資料密度進行視覺化。在此利用小鼠胚胎幹細胞基因表達譜作為例子:
1. 利用直方圖(histgram)
Histogram 為最常用的檢視密度分佈視覺化方法,利用matplotlib 中 hist 函式即可。
plt.hist(TData, bins=50, color='steelblue', normed=True )
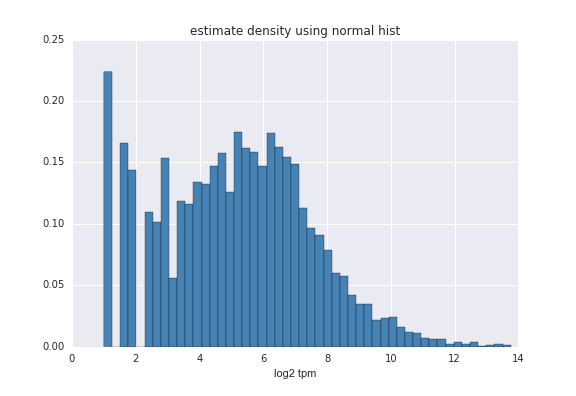
Hist 函式能夠粗略估計資料密度,通過bins調節精細程度。如果想給資料一個更精確的擬合曲線,通過計算擬合函式,用matplotlib畫出來,當然也可以,但比較麻煩。Seaborn 可以很方便的畫出直方圖,擬合曲線。
import seaborn as sns
sns.distplot(TData, rug=True
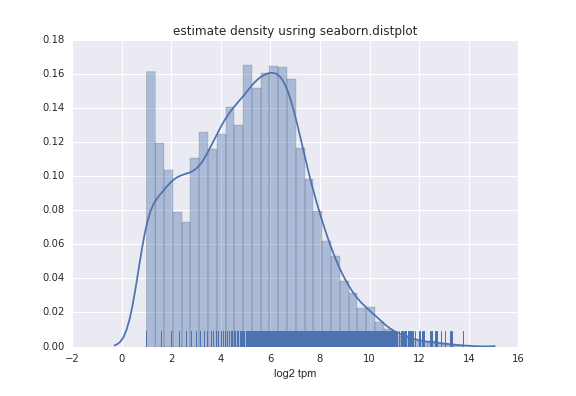
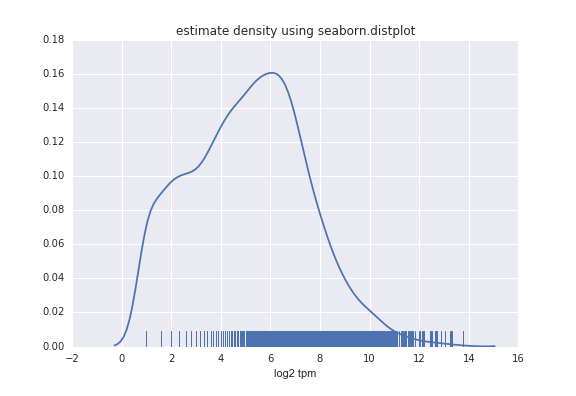
也可以不要直方圖,僅保留擬合曲線:
sns.distplot(TData, rug=True, hist=False)
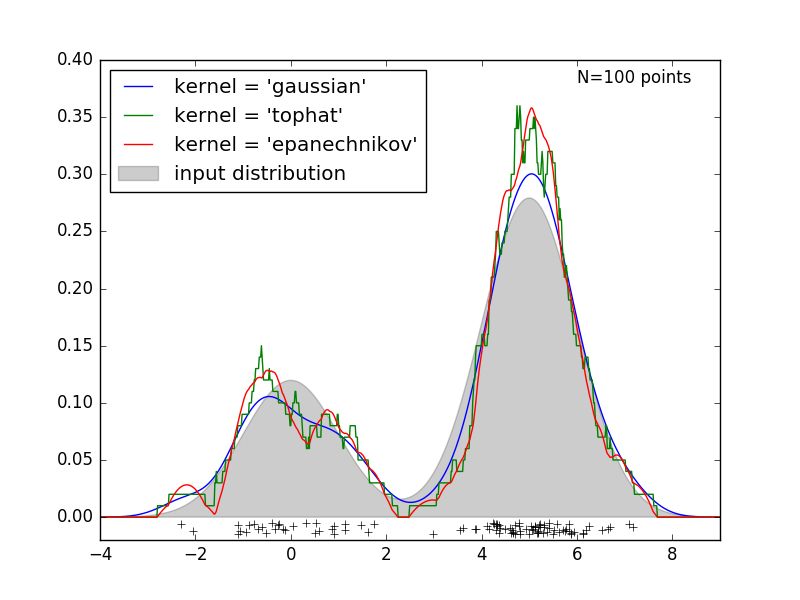
對於高維資料,可以利用Sklearn KernelDensity擬合數據密度,Kernel包括幾種不同的方法,guassin, tophat, cosine等。下圖為SKlearn給出的一個例子:
kde = KernelDensity(kernel=kernel, bandwidth=1.0).fit(X)
dens = kde.score_samples(X_plot)
結語:本文僅討論了一維資料的密度分佈,對於高維資料如何評價密度並可視化,將會是更加有趣的事情,之後進行進一步探索。