一個獲取大量文章標題標籤的辦法
阿新 • • 發佈:2018-12-22
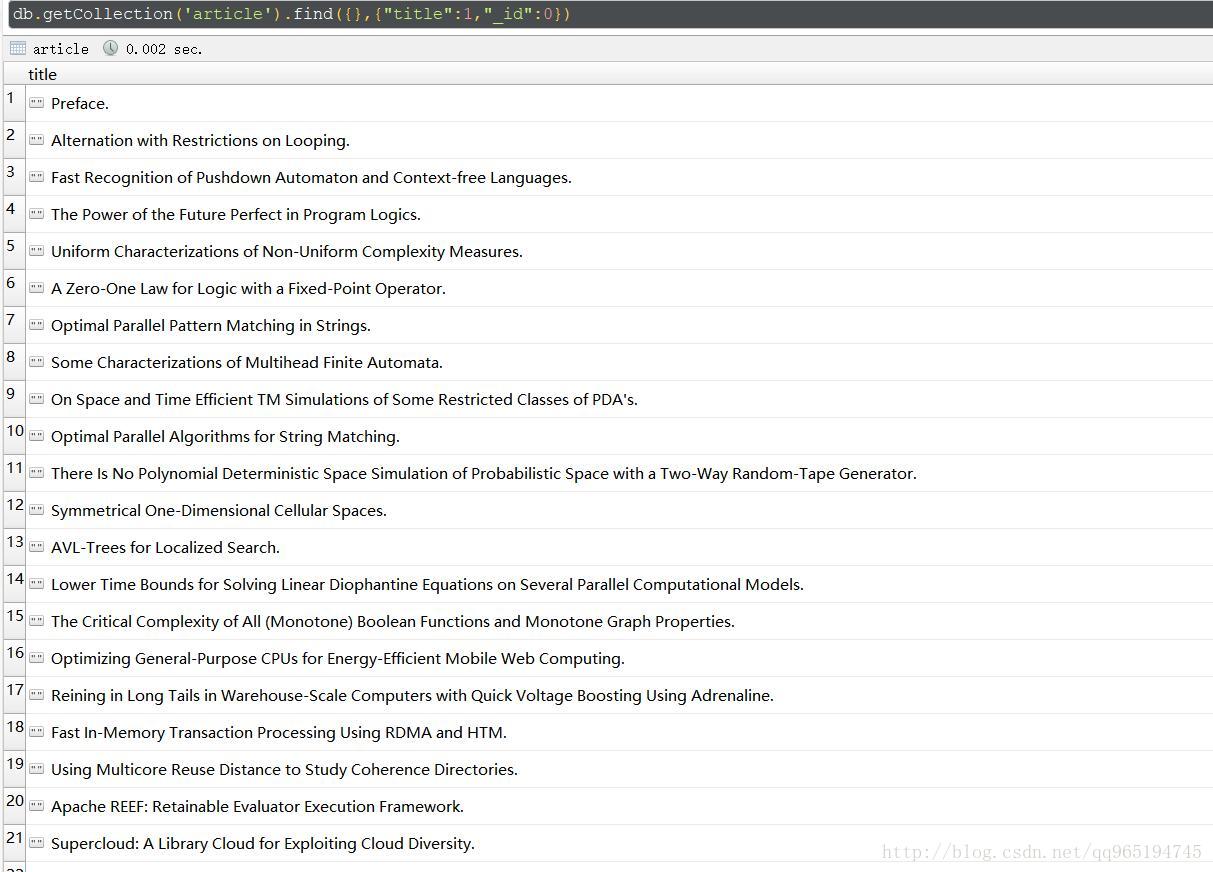
資料
這是大量的論文文章的標題
思維方法
所謂標籤指的就是有些共同的特徵,所以不能侷限於一個文章標題,要全域性考慮
文章標題中很多停用詞(stopwords)以及標點符號應該去除

ngram模型

有了上述條件就可以粗略的尋找文章的標籤了
工具
使用python以及python的nltk自然語言處理庫非常方便
這個是nltk中文文件
方法1
按照上述思路藉助nltk庫進行
import re
from pymongo import MongoClient
client = MongoClient("192.168.33.131" 這些是輸出,可以看到有15個文章是關於檔案系統的,14個文章是關於作業系統的,諸如此類。
[(('file', 'system'), 15), (('operating', 'system'), 14), (('distributed', 'systems'), 13), (('fault', 'tolerance'), 7), (('preface', 'special'), 6), (('special', 'issue'), 5), (('virtual', 'memory'), 5), (('mutual', 'exclusion'), 5), (('design', 'implementation'), 4), (('distributed', 'file'), 4), (('shared', 'memory'), 4), (('reuse', 'distance'), 3), (('storage', 'system'), 3), (('operating', 'systems'), 3), (('memory', 'management'), 3), (('run-time', 'support'), 3), (('distributed', 'system'), 3), (('shared-memory', 'multiprocessors'), 3), (('network', 'file'), 3), (('issue', 'operating'), 3), (('distributed', 'mutual'), 3), (('interprocess', 'communication'), 3), (('optimal', 'parallel'), 2), (('warehouse-scale', 'computers'), 2), (('power', 'energy'), 2), (('ix', 'operating'), 2), (('system', 'combining'), 2), (('combining', 'low'), 2), (('low', 'latency'), 2), (('latency', 'high'), 2), (('high', 'throughput'), 2), (('throughput', 'efficiency'), 2), (('efficiency', 'protected'), 2), (('protected', 'dataplane'), 2), (('cache', 'hierarchies'), 2), (('distance', 'analysis'), 2), (('value', 'prediction'), 2), (('virtual', 'machine'), 2), (('content-based', 'publish/subscribe'), 2), (('scheduling', 'improve'), 2), (('multicore', 'systems'), 2), (('memory', 'systems'), 2), (('garbage', 'collection'), 2), (('networks', 'efficient'), 2), (('wireless', 'ad'), 2), (('ad', 'hoc'), 2), (('hoc', 'networks'), 2), (('load', 'balancing'), 2), (('byzantine', 'fault'), 2), (('thread-level', 'speculation'), 2), (('membership', 'service'), 2), (('multiprocessor', 'cache'), 2), (('cache', 'miss'), 2), (('real-time', 'systems'), 2), (('case', 'study'), 2), (('performance', 'analysis'), 2), (('replicated', 'services'), 2), (('multimedia', 'applications'), 2), (('speculative', 'execution'), 2), (('system', 'using'), 2), (('commodity', 'operating'), 2), (('data', 'structures'), 2), (('branch', 'prediction'), 2), (('area', 'networks'), 2), (('storage', 'systems'), 2), (('performance', 'prediction'), 2), (('hardware', 'support'), 2), (('support', 'network'), 2), (('secure', 'distributed'), 2), (('design', 'evaluation'), 2), (('shared', 'virtual'), 2), (('network', 'interface'), 2), (('file', 'systems'), 2), (('automatically', 'parallelized'), 2), (('parallelized', 'programs'), 2), (('programs', 'using'), 2), (('performance', 'evaluation'), 2), (('system', 'based'), 2), (('traffic', 'control'), 2), (('control', 'systems'), 2), (('disk', 'scheduling'), 2), (('heterogeneous', 'distributed'), 2), (('systems', 'using'), 2), (('lightweight', 'recoverable'), 2), (('recoverable', 'virtual'), 2), (('i/o', 'performance'), 2), (('kernel', 'support'), 2), (('continuous', 'media'), 2), (('multiprocessors', 'preface'), 2), (('architectural', 'support'), 2), (('system', 'principles'), 2), (('concurrency', 'control'), 2), (('data', 'types'), 2), (('exclusion', 'algorithms'), 2), (('special', 'section'), 2), (('measurement', 'modeling'), 2), (('modeling', 'computer'), 2), (('cache', 'performance'), 2), (('systems', 'disk'), 2), (('naming', 'service'), 2)]
方法2
nltk庫封裝好的方法,全自動???

將文字分詞之後構建成nltk的Text類,就能解鎖該方法,自動化分析,去除了停用詞以及標點符號
class getArticalTag():
from pymongo import MongoClient
import util
client = client = MongoClient(util.mongodb, 27017)
db = client.ccf.article.find()#連線上mongo資料庫
text = ""
for a in db:#將標題拼接成一個文字
text += " " + a['title']
from nltk import word_tokenize
#使用nltk Python 自然語言處理庫
from nltk import Text
text = text.lower()#將文字轉換為小寫方便去重
text = word_tokenize(text)#分詞
text = Text(text)#構造成nltk文字
print(text.collocations(num=1000))#直接呼叫該方法輸出也是差不多
operating system; file system; fault tolerance; mutual exclusion;
distributed systems; special issue; reuse distance; virtual memory;
interprocess communication; automatically parallelized; content-based
publish/subscribe; garbage collection; protected dataplane; warehouse-
scale computers; load balancing; thread-level speculation; run-time
support; shared memory; case study; shared-memory multiprocessors;
continuous media; combining low; branch prediction; lightweight
recoverable; parallelized programs; special section; low latency;
byzantine fault; recoverable virtual; virtual machine; naming service;
replicated services; area networks; hoc networks; multimedia
applications; value prediction; data types; cache hierarchies;
speculative execution; commodity operating; high throughput;
concurrency control; distributed mutual; distance analysis; optimal
parallel; traffic control; data structures; membership service; cache
miss; network interface; replicated data; memory management; network
file; architectural support; kernel support; multiprocessor cache;
distributed file; shared virtual; hardware support; disk scheduling;
fault-tolerant distributed; system principles; heterogeneous
distributed; secure distributed; programs using; performance
prediction; storage system; operating systems; performance evaluation;
system based; real-time systems; i/o performance; performance
analysis; control systems; multicore systems; cache performance;
storage systems; distributed system; memory systems; file systems有了標籤之後
給資料庫的文章打上標籤
使用文字索引的精確檢索,找到對應的文章打上標籤即可