
Flink實戰:消費Wikipedia實時訊息
關於Wikipedia Edit Stream
Wikipedia Edit Stream是Flink官網提供的一個經典demo,該應用消費的訊息來自維基百科,訊息中包含了使用者名稱對wiki的編輯情況,demo的官方資料地址:https://ci.apache.org/projects/flink/flink-docs-release-1.2/quickstart/run_example_quickstart.html
訊息來源
訊息的DataSource是個名為WikipediaEditsSource的類,這裡面建立了到irc.wikimedia.org的Socker連線,再通過Internet Relay Chat (IRC) 協議接收對方的資料,收到資料後儲存在阻塞佇列中,通過一個while迴圈不停的從佇列取出資料,再呼叫SourceContext的collect方法,就在Flink中將這條資料生產出來了;
IRC是應用層協議,更多細節請看:https://en.wikipedia.org/wiki/Internet_Relay_Chat
實戰簡介
本次實戰就是消費上述訊息,然後統計每個使用者十五秒內所有的訊息,將每次操作的位元組數累加起來,就得到使用者十五秒內操作的位元組數總和,並且每次累加了多少都會記錄下來並最終和聚合結果一起展示;
和官網demo的不同之處
和官網的demo略有不同,官網用的是Tuple2來處理資料,但我這裡用了Tuple3,多儲存了一個StringBuilder物件,用來記錄每次聚合時加了哪些值,這樣在結果中通過這個欄位就能看出來這個時間視窗內每個使用者做了多少次聚合,每次是什麼值:
環境資訊
Flink:1.7;
執行模式:單機(官網稱之為Local Flink Cluster);
Flink所在機器的作業系統:CentOS Linux release 7.5.1804;
開發環境JDK:1.8.0_181;
開發環境Maven:3.5.0;
操作步驟簡介
今天的實戰分為以下步驟:
- 建立應用;
- 編碼;
- 構建;
- 部署執行;
建立應用
- 應用基本程式碼是通過mvn命令建立的,在命令列輸入以下命令:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId= - 按控制檯的提示輸入groupId、artifactId、version、package等資訊,一路回車確認後,會生成一個和你輸入的artifactId同名的資料夾(我這裡是wikipediaeditstreamdemo),裡面是個maven工程:
Define value for property 'groupId': com.bolingcavalry
Define value for property 'artifactId': wikipediaeditstreamdemo
Define value for property 'version' 1.0-SNAPSHOT: :
Define value for property 'package' com.bolingcavalry: :
Confirm properties configuration:
groupId: com.bolingcavalry
artifactId: wikipediaeditstreamdemo
version: 1.0-SNAPSHOT
package: com.bolingcavalry
Y: :
- 用IEDA匯入這個maven工程,如下圖,已經有了兩個類:BatchJob和StreamingJob,BatchJob是用於批處理的,本次實戰用不上,因此可以刪除,只保留流處理的StreamingJob:
應用建立成功,接下來可以開始編碼了;
編碼
您可以選擇直接從GitHub下載這個工程的原始碼,地址和連結資訊如下表所示:
| 名稱 | 連結 | 備註 |
|---|---|---|
| 專案主頁 | https://github.com/zq2599/blog_demos | 該專案在GitHub上的主頁 |
| git倉庫地址(https) | https://github.com/zq2599/blog_demos.git | 該專案原始碼的倉庫地址,https協議 |
| git倉庫地址(ssh) | [email protected]:zq2599/blog_demos.git | 該專案原始碼的倉庫地址,ssh協議 |
這個git專案中有多個資料夾,本章原始碼在wikipediaeditstreamdemo這個資料夾下,如下圖紅框所示:
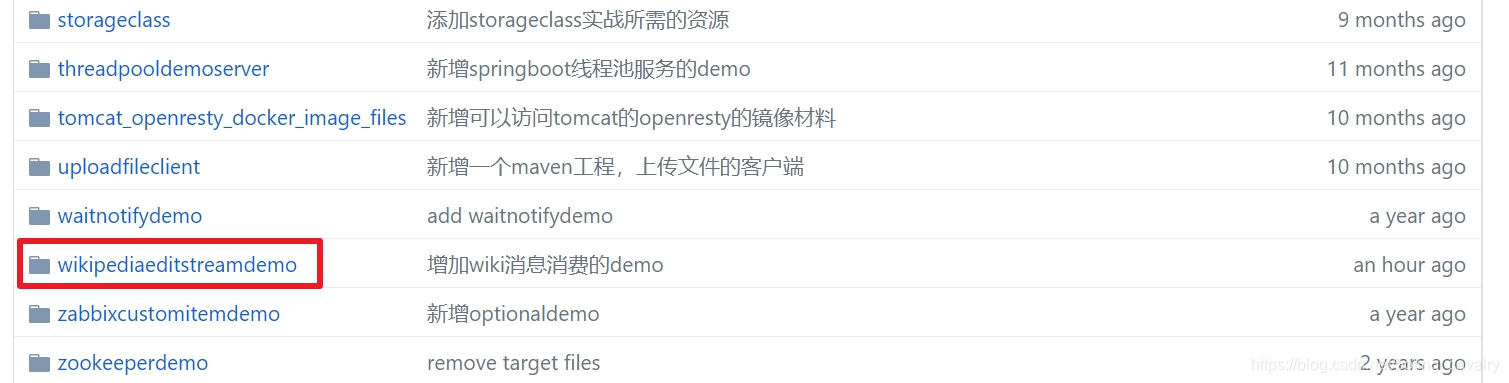
接下來開始編碼:
- 在pom.mxl檔案中增加wikipedia相關的庫依賴:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
- 在類中增加程式碼,如下所示,原始碼中已加詳細註釋:
package com.bolingcavalry;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
public class StreamingJob {
public static void main(String[] args) throws Exception {
// 環境資訊
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new WikipediaEditsSource())
//以使用者名稱為key分組
.keyBy((KeySelector<WikipediaEditEvent, String>) wikipediaEditEvent -> wikipediaEditEvent.getUser())
//時間視窗為5秒
.timeWindow(Time.seconds(15))
//在時間視窗內按照key將所有資料做聚合
.aggregate(new AggregateFunction<WikipediaEditEvent, Tuple3<String, Integer, StringBuilder>, Tuple3<String, Integer, StringBuilder>>() {
@Override
public Tuple3<String, Integer, StringBuilder> createAccumulator() {
//建立ACC
return new Tuple3<>("", 0, new StringBuilder());
}
@Override
public Tuple3<String, Integer, StringBuilder> add(WikipediaEditEvent wikipediaEditEvent, Tuple3<String, Integer, StringBuilder> tuple3) {
StringBuilder sbud = tuple3.f2;
//如果是第一條記錄,就加個"Details :"作為字首,
//如果不是第一條記錄,就用空格作為分隔符
if(StringUtils.isBlank(sbud.toString())){
sbud.append("Details : ");
}else {
sbud.append(" ");
}
//聚合邏輯是將改動的位元組數累加
return new Tuple3<>(wikipediaEditEvent.getUser(),
wikipediaEditEvent.getByteDiff() + tuple3.f1,
sbud.append(wikipediaEditEvent.getByteDiff()));
}
@Override
public Tuple3<String, Integer, StringBuilder> getResult(Tuple3<String, Integer, StringBuilder> tuple3) {
return tuple3;
}
@Override
public Tuple3<String, Integer, StringBuilder> merge(Tuple3<String, Integer, StringBuilder> tuple3, Tuple3<String, Integer, StringBuilder> acc1) {
//合併視窗的場景才會用到
return new Tuple3<>(tuple3.f0,
tuple3.f1 + acc1.f1, tuple3.f2.append(acc1.f2));
}
})
//聚合操作後,將每個key的聚合結果單獨轉為字串
.map((MapFunction<Tuple3<String, Integer, StringBuilder>, String>) tuple3 -> tuple3.toString())
//輸出方式是STDOUT
.print();
// 執行
env.execute("Flink Streaming Java API Skeleton");
}
}
至此編碼結束;
構建
- 在pom.xml檔案所在目錄下執行命令:
mvn clean package -U
- 命令執行完畢後,在target目錄下的wikipediaeditstreamdemo-1.0-SNAPSHOT.jar檔案就是構建成功的jar包;
在Flink驗證
- Flink的安裝和啟動請參考《Flink1.7從安裝到體驗》;
- 我這邊Flink所在機器的IP地址是192.168.1.103,因此用瀏覽器訪問的Flink的web地址為:http://192.168.1.103:8081;
- 選擇剛剛生成的jar檔案作為一個新的任務,如下圖:
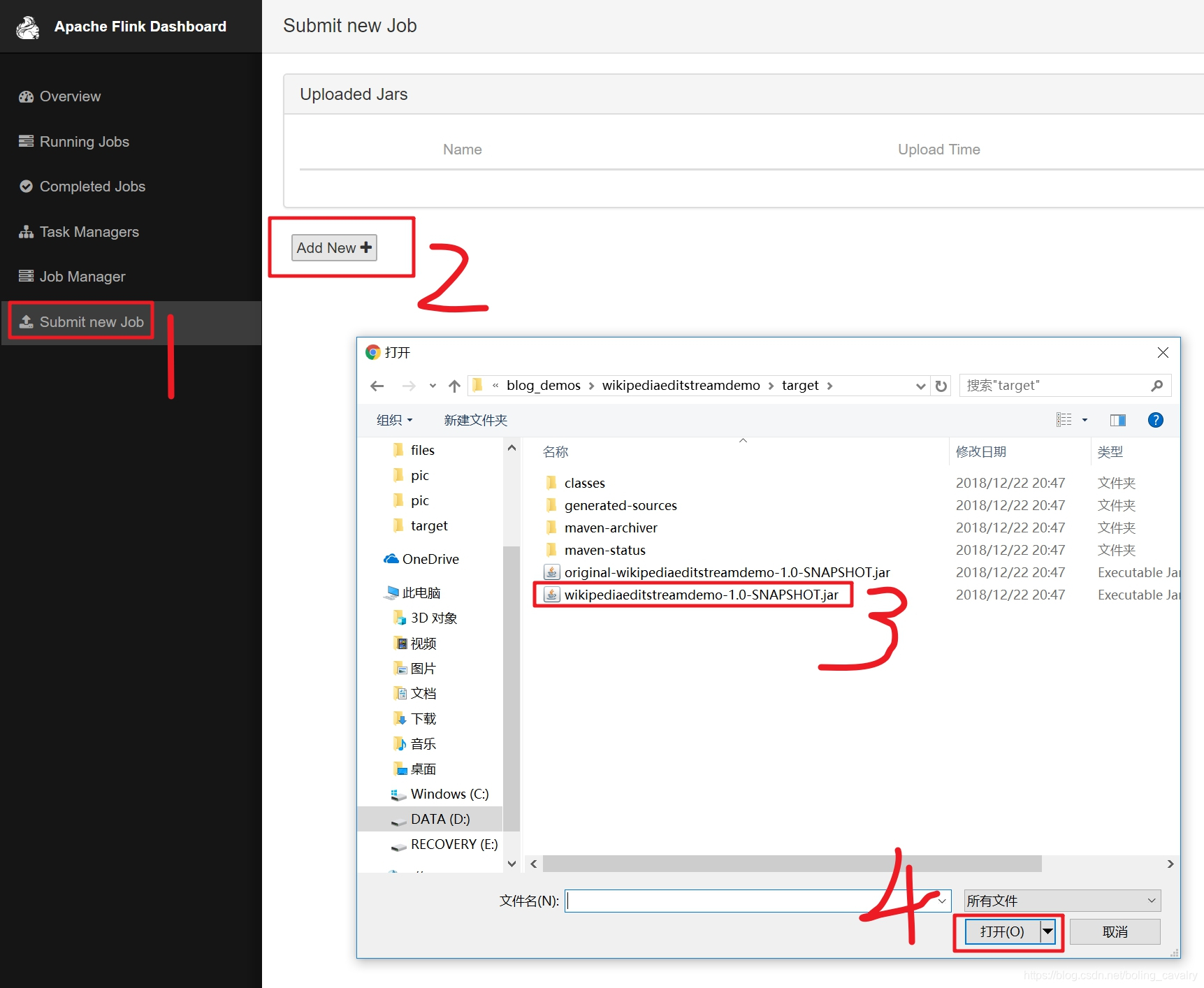
- 點選下圖紅框中的"upload",將檔案提交:
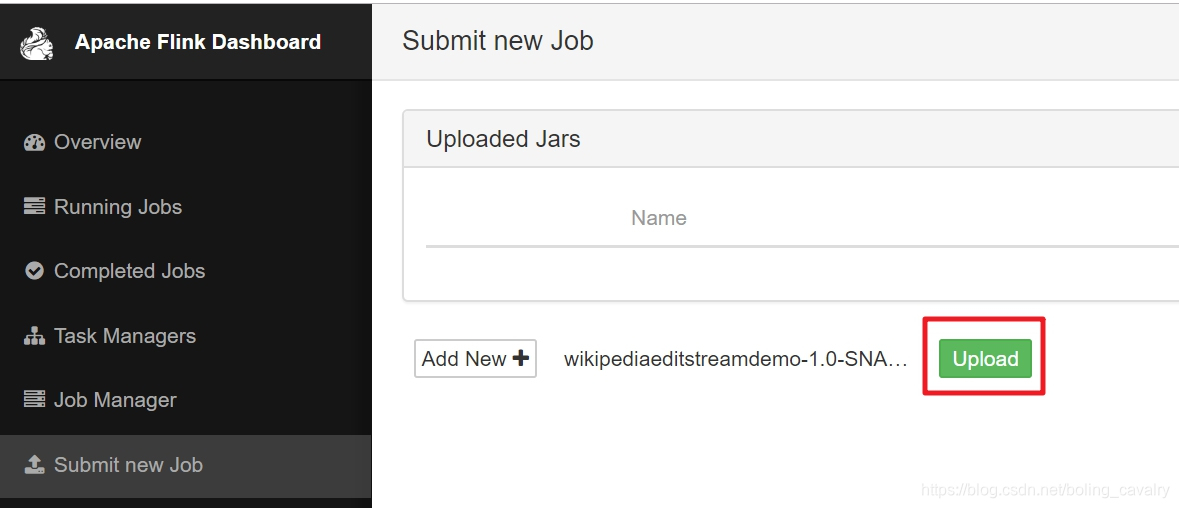
- 目前還只是將jar檔案上傳了而已,接下來就是手工設定執行類並啟動任務,操作如下圖,紅框2中填寫的前面編寫的StreamingJob類的完整名稱:
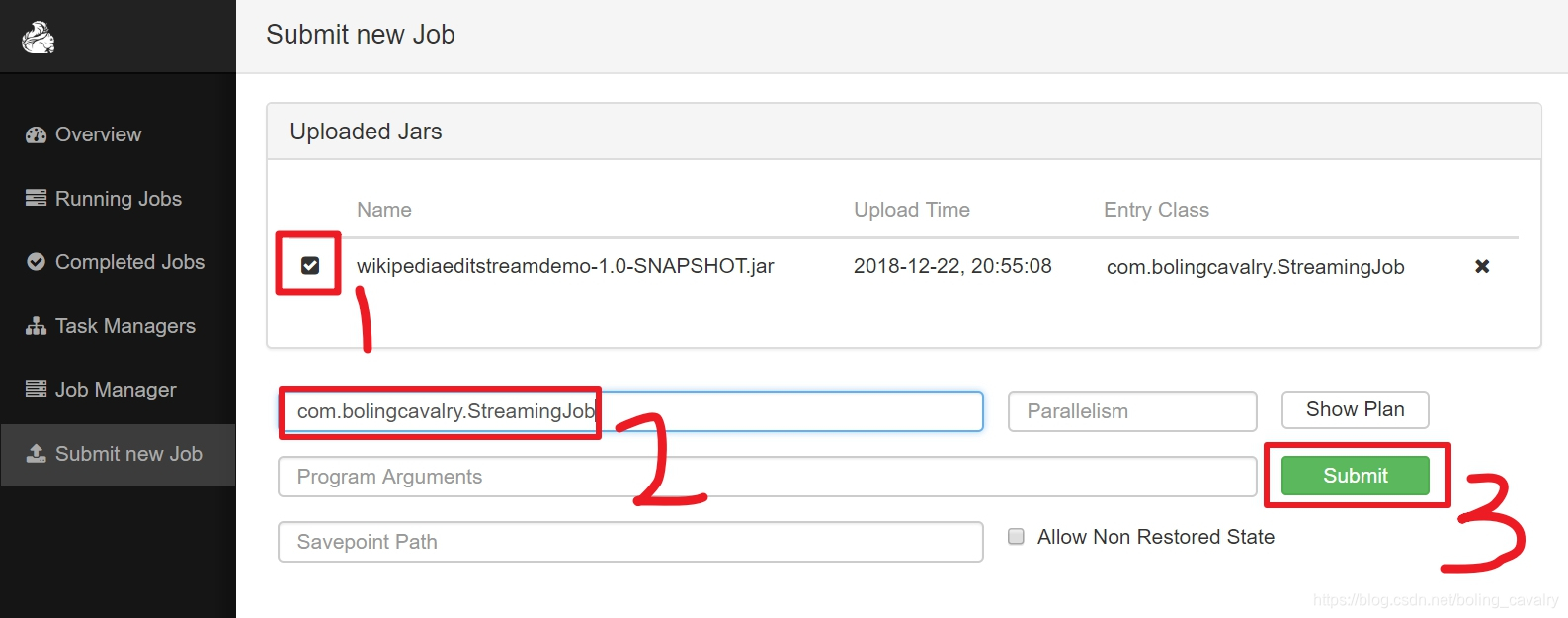
- 提交後的頁面效果如下圖所示,可見一個job已經在執行中了:
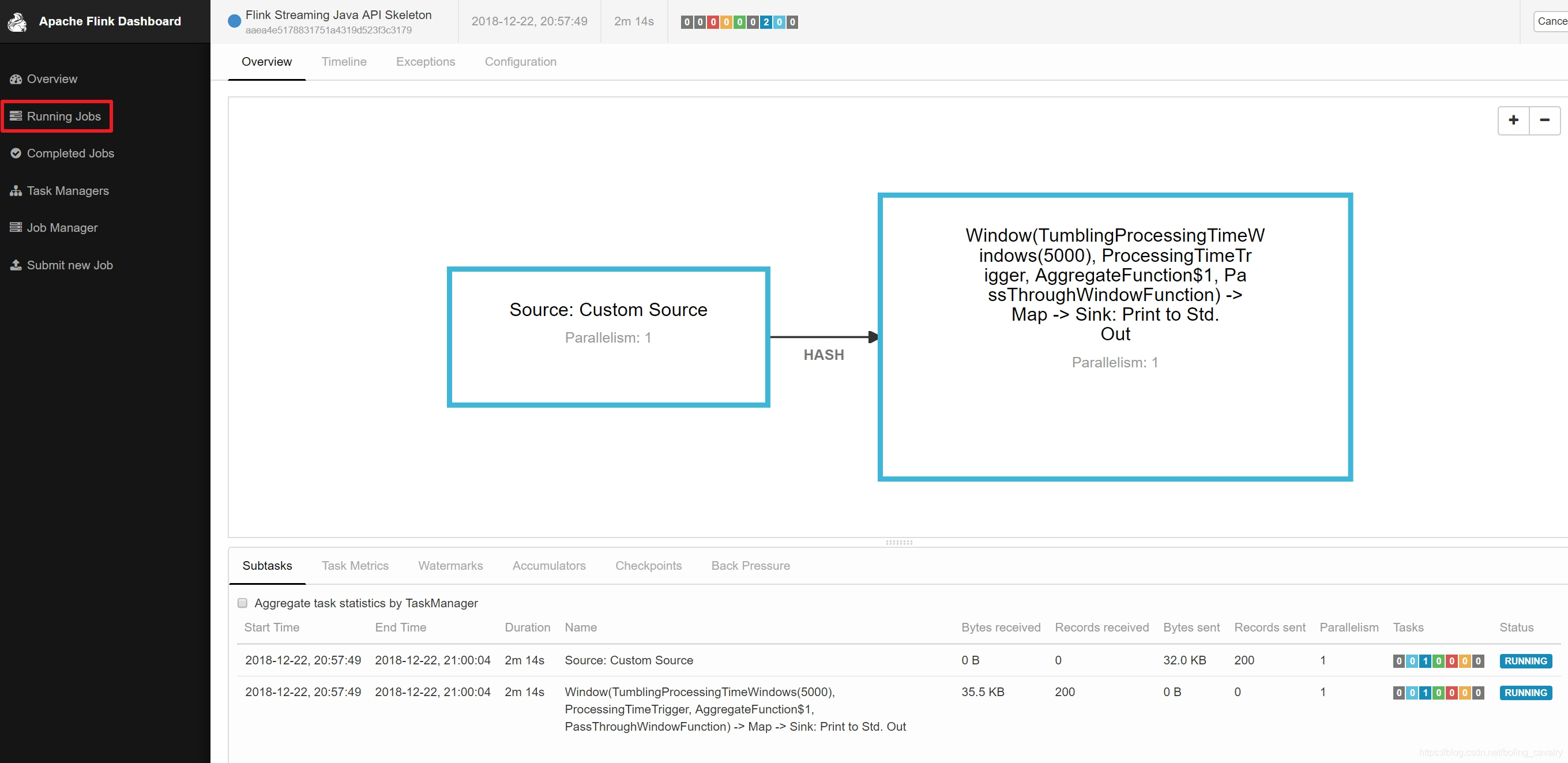
- 接下來看看我們的job的執行效果,如下圖,以使用者名稱聚合後的字數統計已經被打印出來了,並且Details後面的內容還展示了具體的聚合情況:
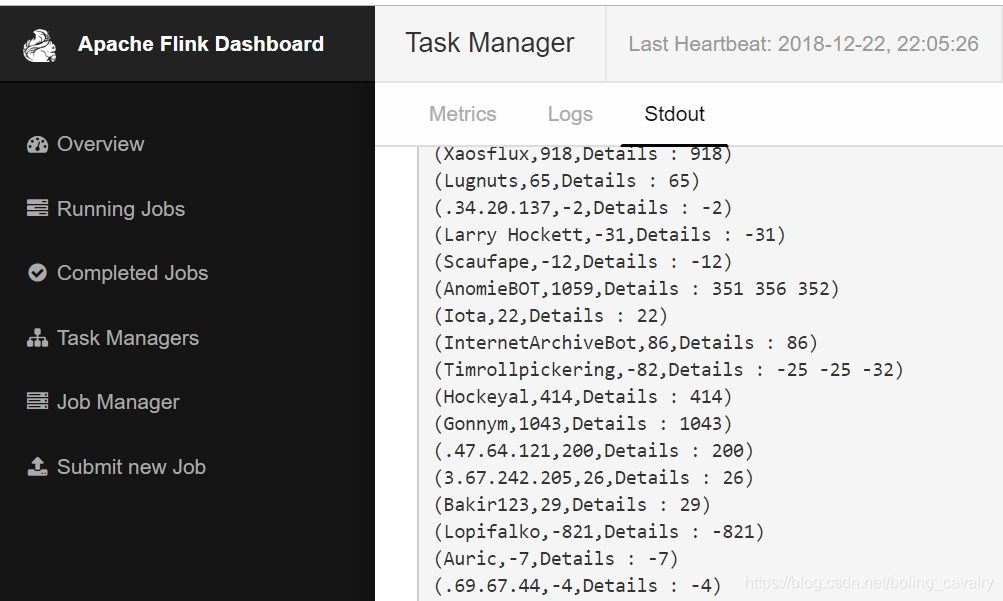
至此,一個實施處理的Flink應用就開發完成了,希望能給您的開發過程提供一些參考,後面的實戰中咱們一起繼續深入學習和探討Flink;