
Kafka實戰:如何把Kafka訊息時延秒降10倍
背景
國內某大型稅務系統,業務應用分散式上雲改造。
業務難題
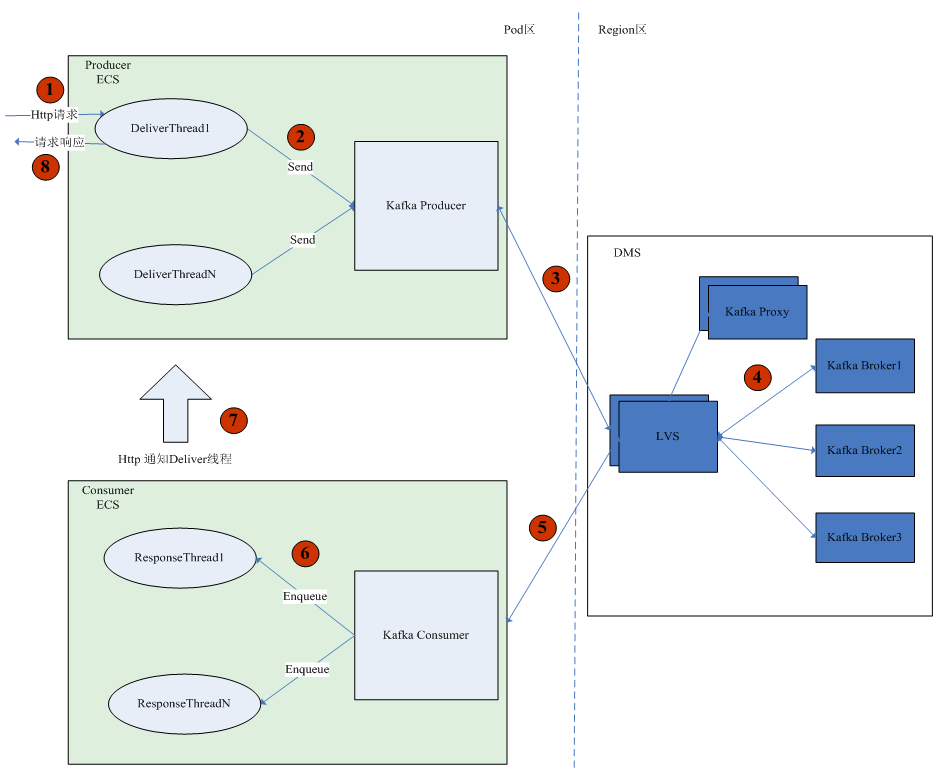
如上圖所示是模擬客戶的業務網頁構建的一個併發訪問模型。使用者在頁面點選從而產生一個HTTP請求,這個請求傳送到業務生產程序,就會啟動一個投遞執行緒(Deliver Thread)呼叫Kafka的SDK介面,併發送3條訊息到DMS(分散式訊息服務),每條訊息大小3k,需要等待3條訊息都被處理完成後才會返回請求響應⑧。當訊息達到DMS後,業務消費程序呼叫Kafka的消費介面把訊息取出來,然後將每條訊息放到一個響應執行緒(Response Thread)中進行處理,響應執行緒處理完後,通過HTTP請求通知投遞執行緒,投遞執行緒收到響應後返回回覆響應。
100併發訪問時延500ms,未達成使用者業務要求
客戶提出了明確的要求:每1個兩核的ECS要能夠支撐併發訪問量100,每條訊息端到端的時延範圍是幾十毫秒,即從生產者傳送開始到接收到消費者響應的時間。客戶實測在使用了DMS的Kafka 佇列後,併發訪問量為100時時延高達到500ms左右,甚至出現達到秒級的時延,遠未達到客戶提出的業務訴求。相比較而言,客戶在Pod區使用的是自己搭建的原生Kafka,在併發訪問量為100時測試到的時延大約只有10~20ms左右。那麼問題來了,在併發訪問量相同的條件下,DMS的Kafka佇列與Pod區自建的原生Kafka相比為什麼時延會有這麼大的差異呢?我們DMS的架構師 Mr. Peng對這個時延難題進行了一系列分析後完美解決了這個客戶難題,下面就讓我們來看看他的心路歷程。
難題剖析
根據模擬的客戶業務模型,Mr. Peng在華為雲類生產環境上也構造了一個測試程式,同樣模擬構造了100的併發訪問量,通過測試發現,類生產環境上壓測得到的時延平均時間在60ms左右。類生產上的時延數值跟客戶在真實生產環境上測到的時延差距這麼大,這是怎麼回事呢?問題變得撲朔迷離起來。
Mr. Peng當機立斷,決定就在華為雲現網上執行構造的測試程式,來看看到底是什麼原因。同時,在客戶的ECS伺服器上,也部署了相同的測試程式,模擬構建了100的併發量,得到如下的時延結果對比表:
調優前時延 | 現網時延(ms) | 類生產時延(ms) |
100併發 | 500ms ~ 4000ms | 40ms ~ 80 ms |
1併發 | 31ms | 6ms |
Ping測試 | 0.9ms ~ 1.2ms | 0.3ms ~ 0.4ms |
表1 華為雲現網與類生產環境時延對比表
從時延對比表的結果看來,Mr. Peng發現,即使在相同的併發壓力下,華為雲現網的時延比類生產差很多。Mr. Peng意識到,現在有2個問題需要分析:為什麼華為雲現網的時延會比類生產差?DMS的Kafka佇列時延比原生自建的Kafka佇列時延表現差的問題怎麼解決?Mr. Peng進行了如下分析:
時延分析
迴歸問題的本質,DMS Kafka佇列的時延到底是怎麼產生的?可控的端到端時延具體分為哪些?Mr. Peng給出瞭如下的計算公式:
總時延 = 入隊時延 + 傳送時延 + 寫入時延 + 複製時延 + 拉取時延
讓我們來依次瞭解一下,公式中的每一項都是指什麼。
入隊時延: 訊息進入Kafka sdk後,先進入到要傳送分割槽的佇列,完成訊息打包後再發送,這一過程所用的時間。
傳送時延:訊息從生產者傳送到服務端的時間。
寫入時延:訊息寫入到Kafka Leader的時間。
複製時延:消費者只可以消費到高水位以下的訊息(即被多個副本都儲存的訊息),所以訊息從寫入到Kafka Leader,到所有副本都寫入該訊息直到上漲至高水位這段時間就是訊息複製的時延。
拉取時延:消費者採用pull模式拉取資料,拉取過程所用的時間。
(1) 入隊時延
現網是哪一部分的時延最大呢?通過我們的程式可以看到,入佇列等待發送時延非常大,如下圖:

即訊息都等待在生產端的佇列中,來不及傳送!
我們再看其他時延分析,因為無法在現網測試,我們分別在類生產測試了相同壓力的,測試其他各種時延如下:
(2) 複製時延
以下是類生產環境測試的1併發下的

從日誌上看,複製時延包括在remoteTime裡面,當然這個時間也會包括生產者寫入時延比較慢導致的,但是也從一定的程度反映複製時延也是提升效能時延的一個因素。
(3) 寫入時延
因為使用者使用的是高吞吐佇列,寫入都是非同步落盤,我們從日誌看到寫入時延非常低(localTime),可以判斷不是瓶頸
傳送時延與拉取時延都是跟網路傳輸有關係,這個優化主要是通過調TCP的引數來決定的。輕輕鬆鬆把Kafka訊息時延秒降10倍,就用華為雲DMS