
How Does Spotify Know You So Well?
Recommendation Model #1: Collaborative Filtering


First, some background: When people hear the words “collaborative filtering,” they generally think of Netflix, as it was one of the first companies to use this method to power a recommendation model, taking users’ star-based movie ratings to inform its understanding of which movies to recommend to othersimilar users.
After Netflix was successful, the use of collaborative filtering spread quickly, and is now often the starting point for anyone trying to make a recommendation model.
Unlike Netflix, Spotify doesn’t have a star-based system with which users rate their music. Instead, Spotify’s data is implicit feedback
But what is collaborative filtering, truly, and how does it work? Here’s a high-level rundown, explained in a quick conversation:
What’s going on here? Each of these individuals has track preferences: the one on the left likes tracks P, Q, R, and S, while the one on the right likes tracks Q, R, S, and T.
Collaborative filtering then uses that data to say:
“Hmmm… You both like three of the same tracks — Q, R, and S — so you are probably similar users. Therefore, you’re each likely to enjoy other tracks that the other person has listened to, that you haven’t heard yet.”
Therefore, it suggests that the one on the right check out track P — the only track not mentioned, but that his “similar” counterpart enjoyed — and the one on the left check out track T, for the same reasoning. Simple, right?
But how does Spotify actually usethat concept in practice to calculate millionsof users’ suggested tracks based on millionsof other users’ preferences?
With matrix math, done with Python libraries!

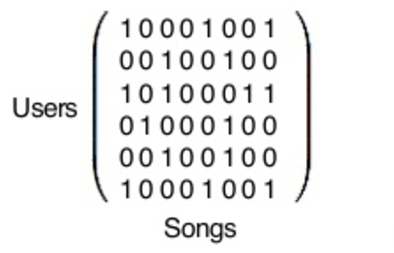
In actuality, this matrix you see here is gigantic. Each row represents one of Spotify’s 140 million users — if you use Spotify, you yourself are a row in this matrix — and each column represents one of the 30 million songs in Spotify’s database.
Then, the Python library runs this long, complicated matrix factorization formula:
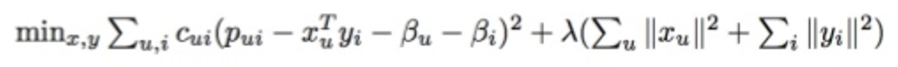
When it finishes, we end up with two types of vectors, represented here by X and Y. X is a user vector, representing one single user’s taste, and Y is a song vector, representing one single song’s profile.

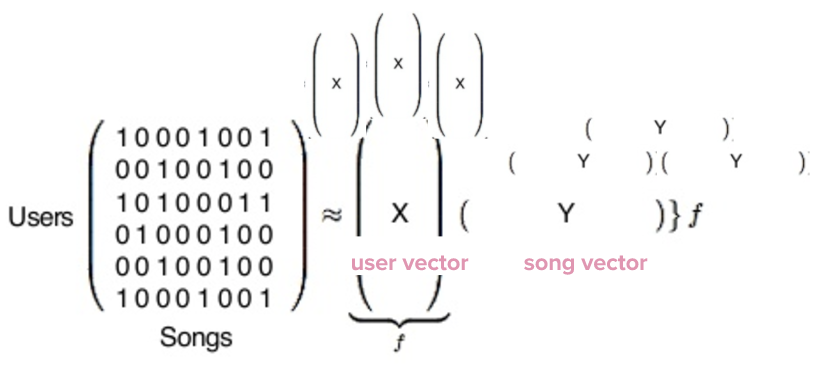
Now we have 140 million user vectors and 30 million song vectors. The actual content of these vectors is just a bunch of numbers that are essentially meaningless on their own, but are hugely useful when compared.
To find out which users’ musical tastes are most similar to mine, collaborative filtering compares my vector with all of the other users’ vectors, ultimately spitting out which users are the closest matches. The same goes for the Y vector, songs: you can compare a single song’s vector with all the others, and find out which songs are most similar to the one in question.
Collaborative filtering does a pretty good job, but Spotify knew they could do even better by adding another engine. Enter NLP.