
無鎖和無等待的定義和例子
在查閱google之後,我發現沒有一處對併發演算法或是資料結構規定的演進條件(progress condition,注:參考[1],譯者認為翻譯為演進狀態更為合適)做合理的解釋。甚至在”The Art of Multiprocessor Programming“中也只有圍繞書本的一小段定義,大部分定義是單行的句子,因而造成了我們普通人含義模糊的理解,所以在這裡我把我對這些概念的理解整理在一起,並且在每一種概念後面給出相應的例子。
我們先將演進條件分為四個主要類別,阻塞(blocking),無干擾(obstruction-free),無鎖(lock-free),和無等待(wait-free)。詳細列表如下:
Blocking
1. Blocking
2. Starvation-Free
Obstruction-Free
3. Obstruction-Free
Lock-Free
4. Lock-Free (LF)
Wait-Free
5. Wait-Free (WF)
6. Wait-Free Bounded (WFB)
7. Wait-Free Population Oblivious (WFPO)
在我們開始解釋每一個術語的意義之前,讓我們先了解一些相關細節。
根據《The Art of Multiprocessor Programming》一書3.6節中的相關描述,我們很難理解有界無等待(wait-free bounded,注:參考[1])和集居數無關無等待(wait-free population oblivious,注:參考[1])的概念是否相關。就我個人而言,我認為一個演算法如果滿足集居數無關無等待,就意味著這個演算法是有限界的,從而這個演算法也滿足有界無等待。這代表一個方法(或者是一個演算法,一個類)可以是無等待,或者有界無等待,或者集居數無關無等待,最後一個條件是所有演進條件中“最好”的。
在這篇文章中我們討論的例子都是關於某個(一個演算法中,或一個類中)的特定方法的演進條件,而不是完整的演算法。我們這樣做的原因是一個演算法中不同的方法可能會採用不同的演進保證(progress guarantees),舉個例子:(某個演算法)寫操作可能是阻塞的,然而讀操作是滿足集居數無關無等待,這樣的情況在你第一次觀察某個無鎖和無等待資料結構的時候並不是顯而易見的。
是的,你的結論是正確的:一個數據結構中可能有某些操作是阻塞的,另外一些操作是無鎖的,剩下的甚至是無等待的。另一方面,當我們稱某個特定的資料結構是無鎖,這代表這個資料結構的所有操作都是無鎖,或者更好的狀態(無等待或者更好)。
事實上在著作中沒有嚴格對那種狀態更好有嚴格的定義,但是一般而言說是這樣的:
無等待>無鎖>阻塞
上述說法的理由是:現實中並沒有太多無鎖或者是無等待的(實用)資料結構,所以通常不會出現關於演進狀態合理分類的問題。Andreia和我提出了很多不同種類的併發演算法,其中混合了各種演進狀態。因此我們需要對這些演進狀態合理地命名,並且對他們排序,從而繼續對他們的處理,並且發現哪些演算法值得研究。
我們提出的順序就是文章開頭描述的列表,表中阻塞是最差的,集居數無關無等待是可能達到的最好狀態。
另一個通常會導致困惑的說法是“無等待意味著無鎖”(但是不能反過來說)。這意味著一個方法如果滿足無等待,那麼這個方法有著和一個無鎖方法同樣的演進保證。下圖是一張venn圖,可能能夠更好的解釋我們的意思。
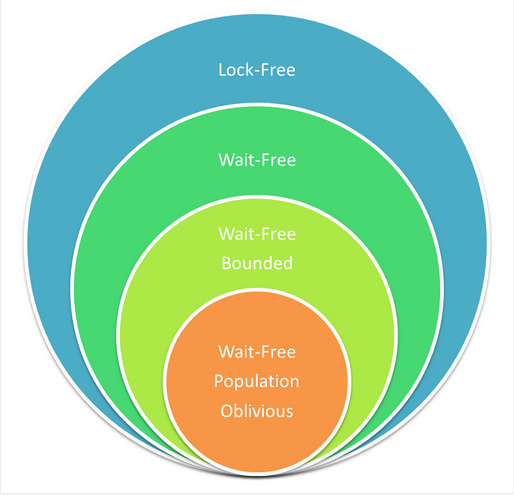
這張圖展示了演算法的集合,圖中無等待的演算法也是無鎖演算法的一部分。
1. 阻塞
阻塞是大家所熟知的。基本所有加鎖的演算法都可以說是阻塞的。某個執行緒所引起的意外延遲會阻止其他執行緒繼續執行。在最壞的情況下,某個佔有鎖的執行緒可能被睡眠,從而阻止其他等待鎖釋放的執行緒進行接下來的任何操作。
定義:
一個方法被稱為阻塞的,即這個方法在其演進過程中不能正常執行直到其他(佔有鎖的)執行緒釋放。
例子:
迴圈中對擁有兩個狀態的變數的簡單CAS操作
AtomicInteger lock = new AtomicInteger(0);
public void funcBlocking() {
while (!lock.compareAndSet(0, 1)) {
hread.yield();
}
}
2. 無飢餓
(無飢餓)有的時候也被稱為無閉鎖。這是一個獨立的性質,只有當底層平臺/系統提供了明確的保障以後討論這個性質才有意義。
定義:
只要有一個執行緒在互斥區中,那麼一些希望進入互斥區域的執行緒最終都能夠進入互斥區域(即使之前在互斥區中的執行緒意外停止了)。
例子:
一個嚴格公平的互斥鎖通常是無飢餓的。
在JDK 8中的StampedLock有這樣的性質,因為它建立了一個執行緒佇列(連結串列)等待獲取鎖。這個佇列的插入操作是無鎖的,但是在插入之後,每個執行緒都會自旋或者讓步從而被當前佔有鎖的執行緒鎖阻塞。釋放鎖的執行緒採用unsafe.park()/unpark()機制,夠喚醒下一個在佇列中等待的執行緒,從而執行了嚴格的優先順序。這個機制的意義是,如果給予其他執行緒(佔有鎖的執行緒)足夠的時間去完成他們的操作,那麼當前執行緒可以確保最終獲取鎖,然後完成自己的操作。
有關StampedLock的原始碼詳見這裡:
3. 無干擾
這是一個非阻塞性質。關於無干擾和無飢餓的更多細節可以檢視《The Art of Multiprocessor Programming》(revised edition)的第60頁。
定義:
如果一個方法滿足無干擾性質,那麼這個方法從任意一點開始它的執行都是隔離的,並且能夠在有限步內完成。
例子:
我所知道的唯一例子就是Maurice Herlihy,Mark Moir和Victor Luchangco所提出的Double-ended Queue。
4. 無鎖
無鎖的性質保證了至少有一個執行緒在正常執行。在理論上這代表了一個方法可能需要無限的操作才能完成,但是在實踐中只需要消耗很短的時間,否則這個性質就沒有什麼價值了。
定義:
如果一個方法是lock-free的,它保證執行緒無限次呼叫這個方法都能夠在有限步內完成。
例子:
一個呼叫CAS操作的迴圈增加原子整形變數。
AtomicInteger atomicVar = new AtomicInteger(0);
public void funcLockFree() {
int localVar = atomicVar.get();
while (!atomicVar.compareAndSet(localVar, localVar+1)) {
localVar = atomicVar.get();
}
}
另外一個比較著名的例子是java.util.concurrent中的ConcurrentLinkedQueue,其中add()和remove()操作是無鎖的。
5. 無等待
無等待性質保證了任何一個時間片內的執行緒可以執行,並且最後完成。這個性質保證步驟是有限的,但是在實踐中,這個數字可能是極大的,並且依賴活動的執行緒數目,因此目前沒有很多實用的無等待資料結構。
定義:
假如一個方法是無等待的,那麼它保證了每一次呼叫都可以在有限的步驟內結束。
例子:
這篇論文給出了一個無等待(有界無等待)演算法的例子。
6. 有界無等待
任何一個有界無等待的演算法,也是無等待的(但並不一定是集居數無關無等待的)。
定義:
如果一個方法是有界無等待的,那麼這個方法保證每次呼叫都能夠在有限,並且有界的步驟內完成。這個界限可能依賴於執行緒的數量。
例子:
一個掃描/寫入到長度和執行緒數目相關的陣列的方法。如果陣列中每個條目的運算元是常量,那麼顯然這個方法是有界無等待的,並且不是集居數無關無等待,因為陣列的長度和執行緒的數目有關。
AtomicIntegerArray intArray = new AtomicIntegerArray(MAX_THREADS);
public void funcWaitFreeBounded() {
for (int i = 0; i < MAX_THREADS ; i++) {
intArray.set(i, 1);
}
}
7. 集居數無關無等待
這個性質用來描述這些在一定數量步驟內完成一些指令,並且指令數目與活動執行緒數目無關的方法。任何一個集居數無關無等待的方法都是有界無等待的。
定義:
一個無等待的方法,如果其效能和活動執行緒數目無關,那麼被稱為集居數無關無等待的。
例子:
最簡單的例子是使用fetch-and-add原語(在X86 CPU上是XADD指令)增加一個原子變數。這個操作可以用C11/C++11中的fetch_add()原子方法完成。
atomic counter;
void funcWaitFreeBoundedPopulationOblivious() {
counter.fetch_add(1);
}
結論
上述的這些並不是問題的全部。我們忽略了兩個瞭解全貌需要掌握的知識點:
第一點,如果你的方法需要分配記憶體,那麼這個方法可以提供的演進保證在實際中受到記憶體分配機制的演進條件所限制。我認為,我們需要針對方法是否需要分配記憶體進行不同的分類。你可以在這篇文章中瞭解更多的細節,但是基本的思想是創造一個集居數無關無等待的,並且一直需要用阻塞機制分配記憶體的方法沒有太大的意義。
第二點,關於演進條件的完整概念是用於將演算法和方法按照時間保證分類,但是這些定義卻是基於運算元目。這基於一個操作的完成時間與活動執行緒數目無關這個假設的,這些假設在單執行緒程式碼中是正確的,但是在多執行緒程式中將會失效。
CPU快取一致性的工作機制,將會導致多執行緒/多核訪問(原子)變數的競爭,從而使得一個操作/指令在一定情況下(因為cache-miss)需要相對更長的時間才能完成。如果你不相信我的話,可以看一看這篇文章,這就是為什麼許多wait-free資料結構的實現要比lock-free的相同資料結構更慢的主要的原因(或者說主要原因之一),儘管他們對執行的操作總次數有更強的保證,每一個操作因為競爭的因素卻可能要用很長的時間去完成……還可能是他們平均執行的操作次數更多。
總的來說,對於傾向於數學的讀者,這裡有我提出的定義:
設F為一個函式方法
設L為同時呼叫F的併發執行緒數目
設N為一個與L無關的變數
設OpsF()代表一個指定執行緒完成F需要進行的運算元目。
設C(n,L)為一個依賴N和L的函式
當任何有限值L滿足以下條件時,F方法是對應的進行狀態:
Lock-free:
如果至少有一個L執行緒在有限步驟內完成操作;OpsF() < C(N,L)
Wait-free:
如果所有的L個執行緒在有限的步驟內完成操作:OpsF() < C(N,L)
Wait-free bounded:
如果所有的L個執行緒消耗C(N,L)或者更少的時間完成操作:OpsF() < C(N,L)
Wait-free population oblivious:
如果所有的L個執行緒在有限操作內完成F,並且和L無關:OpsF() < C(N)
在實踐中,“無等待”和“有界無等待”的區別很小,這篇論文中有很好的解釋:
另一個細節是,並沒有“集居數無關無等待”(的資料結構,注:準確的話說是沒有一個所有方法都是集居數無關無等待的資料結構),因為達到集居數無關的狀態意味著,F方法有一個使其執行結束所需的最壞運算元目上限。
希望這篇文章可以幫助你理解lock-free和wait-free的區別。
參考
