
《kafka中文手冊》-快速開始
Kafka™ is a distributed streaming platform. What exactly does that mean? Kafka是一個分散式資料流處理系統, 這意味著什麼呢?
We think of a streaming platform as having three key capabilities:我們回想下流資料處理系統的三個關鍵能力指標
- It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.系統具備釋出和訂閱流資料的能力, 在這方面, 它類似於訊息佇列或企業訊息匯流排
- It lets you store streams of records in a fault-tolerant way.系統具備在儲存資料時具備容錯能力
- It lets you process streams of records as they occur.系統具備在資料流觸發時進行實時處理
What is Kafka good for?那kafka適用在哪些地方?
It gets used for two broad classes of application: 它適用於這兩類應用
- Building real-time streaming data pipelines that reliably get data between systems or applications 在系統或應用間需要相互進行資料流互動處理的實時系統
- Building real-time streaming applications that transform or react to the streams of data 需要對資料流中的資料進行轉換或及時處理的實時系統
To understand how Kafka does these things, let’s dive in and explore Kafka’s capabilities from the bottom up. 為了瞭解Kafka做了哪些事情, 我們開始從下往上分析kafka的能力
First a few concepts: 首先先了解這幾個概念
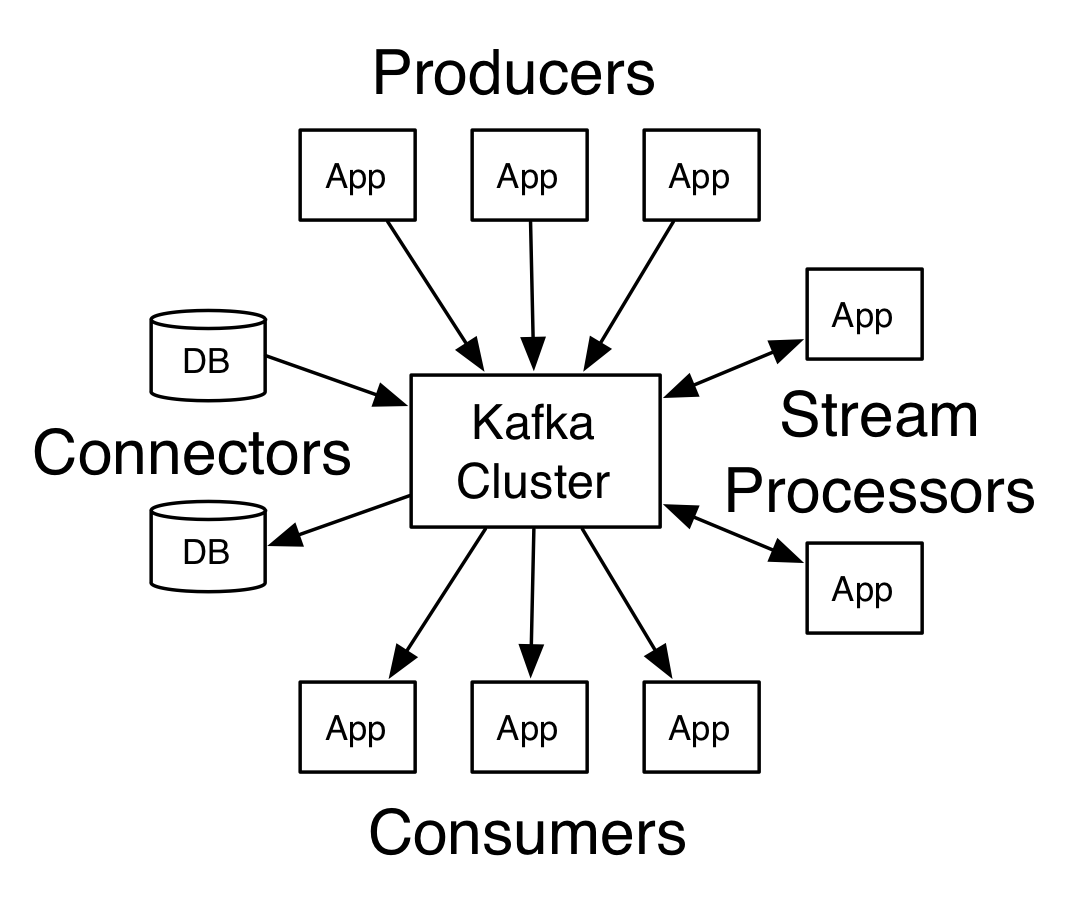
- Kafka is run as a cluster on one or more servers. kafka是一個可以跑在一臺或多臺伺服器上的叢集
- The Kafka cluster stores streams of records in categories called topics. Kafka叢集儲存不同的資料流以topic形式進行劃分
- Each record consists of a key, a value, and a timestamp. 每條資料流中的每條記錄包含key, value, timestamp三個屬性
Kafka has four core APIs: Kafka擁有4個核心的api
- The Producer API allows an application to publish a stream records to one or more Kafka topics. Producer API 用於讓應用釋出流資料到Kafka的topic中
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them. Consumer API 用於讓應用訂閱一個或多個topic後, 獲取資料流進行處理
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams. Streams API 用於讓應用傳教流處理器, 流處理器的輸入可以是一個或多個topic, 並輸出資料流結果到一個或多個topic中, 它提供一種有效的資料流處理方式
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table. Connector API 用於為現在的應用或資料系統提供可重用的生產者或消費者, 他們連線到kafka的topic進行資料互動. 例如, 建立一個到關係型資料庫聯結器, 用於捕獲對某張表的所有資料變更
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. This protocol is versioned and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many languages. Kafka 基於簡單、高效的tcp協議完成伺服器端和客戶端的通訊, 該協議是受版本控制的, 並可以相容老版本. 我們有提供java的kafka客戶端, 但也提供了很多其他語言的客戶端
Let’s first dive into the core abstraction Kafka provides for a stream of records—the topic.首先我們考察下kafka提供的核心資料流結構– topic(主題)
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it. topic是一個分類欄目,由於記錄一類資料釋出的位置. topic在kafka中通常都有多個訂閱者, 也就是說一個topic在寫入資料後, 可以零個, 一個, 或多個訂閱者進行消費
For each topic, the Kafka cluster maintains a partitioned log that looks like this: 針對每個topic佇列, kafka叢集構建一組這樣的分割槽日誌:
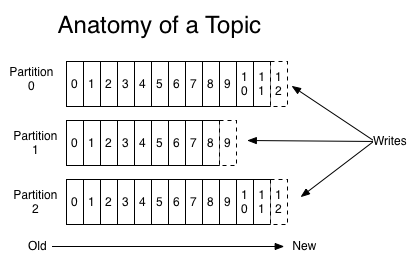 Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
每個日誌分割槽都是有序, 不可變, 持續提交的結構化日誌, 每條記錄提交到日誌分割槽時, 都分配一個有序的位移物件offset, 用以唯一區分記資料在分割槽的位置
The Kafka cluster retains all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka’s performance is effectively constant with respect to data size so storing data for a long time is not a problem.
無論釋出到Kafka的資料是否有被消費, 都會保留所有已經發布的記錄, Kafka使用可配置的資料儲存週期策略, 例如, 如果儲存策略設定為兩天, 則兩天前釋出的資料可以被訂閱者消費, 過了兩天後, 資料佔用的空間就會被刪除並回收. 在儲存資料上, kafka提供高效的O(1)效能處理演算法, 所以儲存長期時間不是一個問題
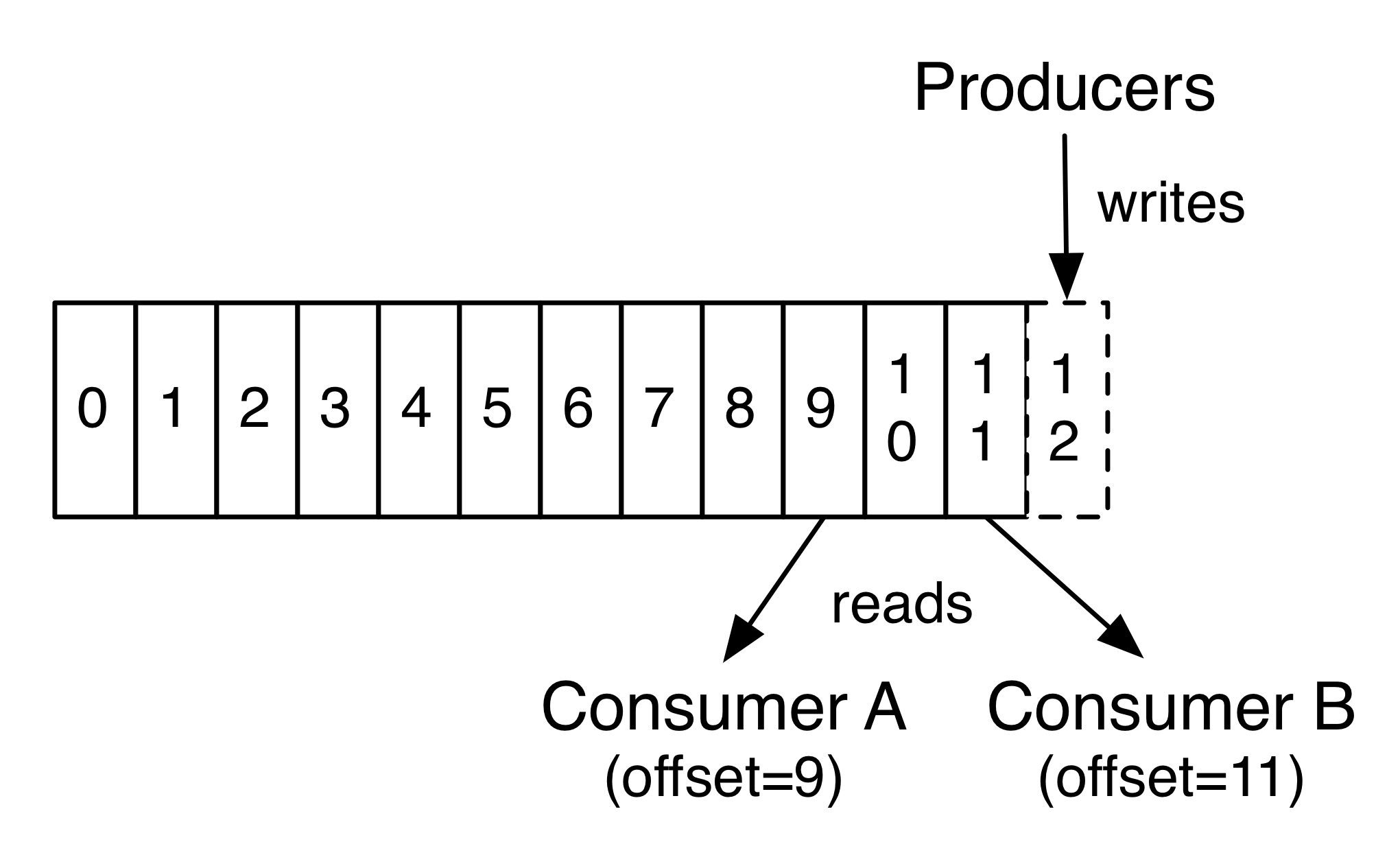 In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
實際上, 每個消費者唯一儲存的元資料資訊就是消費者當前消費日誌的位移位置. 位移位置是被消費者控制, 正常情況下, 如果消費者讀取記錄後, 位移位置往前移動. 但是事實上, 由於位移位置是消費者控制的, 所以消費者可以按照任何他喜歡的次序進行消費, 例如, 消費者可以重置位移到之前的位置以便重新處理資料, 或者跳過頭部從當前最新的位置進行消費
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to “tail” the contents of any topic without changing what is consumed by any existing consumers.
這些特性表明Kafka消費者消費的代價是十分小的, 消費者可以隨時消費或停止, 而對叢集或其他消費者沒有太多的影響, 例如你可以使用命令列工具, 像”tail”工具那樣讀取topic的內容, 而對其它消費者沒有影響
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
分割槽在日誌中有幾個目的, 首先, 它能擴大日誌在單個伺服器裡面的大小, 每個分割槽大小必須適應它從屬的伺服器的規定的大小, 但是一個topic可以有任意很多個分割槽, 這樣topic就能儲存任意大小的資料量, 另一方面, 分割槽還和併發有關係, 這個後面會講到
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
kafka的日誌分割槽機制跨越整個kafka日誌叢集, 每個伺服器使用一組公用的分割槽進行資料處理, 每個分割槽可以在叢集中配置副本數
Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
每個分割槽都有一臺伺服器是主的, 另外零臺或多臺是從伺服器, 主伺服器責所有分割槽的讀寫請求, 從伺服器被動從主分割槽同步資料. 如果主伺服器分割槽的失敗了, 那麼備伺服器的分割槽就會自動變成主的. 每臺伺服器的所有分割槽中, 只有部分會作為主分割槽, 另外部分作為從分割槽, 這樣可以在叢集中對個個伺服器做負載均攤
Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record). More on the use of partitioning in a second!
生產者釋出訊息到他們選擇的topic中, 生產者負責選擇記錄要釋出到topic的那個分割槽中, 這個可以簡單通過輪詢的方式進行負載均攤, 或者可以通過特定的分割槽選擇函式(基於記錄特定鍵值), 更多分割槽的用法後面馬上介紹
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
消費者使用消費組進行標記, 釋出到topic裡面的每條記錄, 至少會被消費組裡面一個消費者例項進行消費. 消費者例項可以是不同的程序, 分佈在不同的機器上
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
如果所有的消費者屬於同一消費組, 則記錄會有效地分攤到每一個消費者上, 也就是說每個消費者只會處理部分記錄
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
如果所有的消費者都屬於不同的消費組, 則記錄會被廣播到所有的消費者上, 也就說每個消費者會處理所有記錄
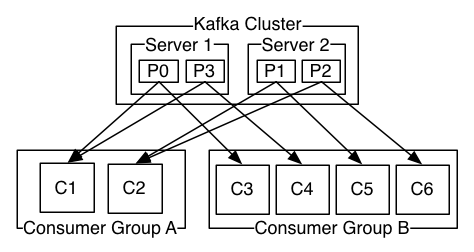 A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
圖為一個2個伺服器的kafka叢集, 擁有4個分割槽, 2個消費組, 消費組A有2個消費者, 消費組B有4個消費者
More commonly, however, we have found that topics have a small number of consumer groups, one for each “logical subscriber”. Each group is composed of many consumer instances for scalability and fault tolerance. This is nothing more than publish-subscribe semantics where the subscriber is a cluster of consumers instead of a single process.
在大多數情況下, 一般一個topic值需要少量的消費者組, 一個消費組對應於一個邏輯上的消費者. 每個消費組一般包含多個例項用於容錯和水平擴充套件. 這僅僅是釋出訂閱語義,其中訂閱者是消費者群集,而不是單個程序.
The way consumption is implemented in Kafka is by dividing up the partitions in the log over the consumer instances so that each instance is the exclusive consumer of a “fair share” of partitions at any point in time. This process of maintaining membership in the group is handled by the Kafka protocol dynamically. If new instances join the group they will take over some partitions from other members of the group; if an instance dies, its partitions will be distributed to the remaining instances.
在kafka中實現日誌消費的方式, 是把日誌分割槽後分配到不同的消費者例項上, 所以每個例項在某個時間點都是”公平共享”式獨佔每個分割槽. 在這個處理過程中, 維持組內的成員是由kafka協議動態決定的, 如果有新的例項加入組中, 則會從組中的其他成員分配一些分割槽給新成員, 如果某個例項銷燬了, 則它負責的分割槽也會分配給組內的其它成員
Kafka only provides a total order over records within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over records this can be achieved with a topic that has only one partition, though this will mean only one consumer process per consumer group.
kafka值提供在一個日誌分割槽裡面順序消費的能力, 在同一topic的不同分割槽裡面是沒有保證的. 由於記錄可以結合鍵值做分割槽, 這樣的分割槽順序一般可以滿足各個應用的需求了, 但是如果你要求topic下的所有記錄都要按照次序進行消費, 則可以考慮一個topic值建立一個分割槽, 這樣意味著你這個topic只能讓一個消費者消費
At a high-level Kafka gives the following guarantees: 在一個高可用能的kafka叢集有如下的保證:
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
- 被同一個釋出者傳送到特定的日誌分割槽後, 會按照他們傳送的順序進行新增, 例如 記錄M1 和記錄M2 都被同一個提供者傳送, M1比較早傳送, 則M1的位移值比M2小, 並記錄在比較早的日誌位置
- A consumer instance sees records in the order they are stored in the log.
- 消費者例項按照日誌記錄的順序進行讀取
- For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.
- 如果topic有N個副本, 則可以容忍N-1臺伺服器宕機時, 提交的記錄不會丟失
More details on these guarantees are given in the design section of the documentation.
更多關於kafka能提供的特性會在設計這個章節講到
How does Kafka’s notion of streams compare to a traditional enterprise messaging system?
kafka的流概念和傳統的企業訊息系統有什麼不一樣呢?
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each record goes to one of them; in publish-subscribe the record is broadcast to all consumers. Each of these two models has a strength and a weakness. The strength of queuing is that it allows you to divide up the processing of data over multiple consumer instances, which lets you scale your processing. Unfortunately, queues aren’t multi-subscriber—once one process reads the data it’s gone. Publish-subscribe allows you broadcast data to multiple processes, but has no way of scaling processing since every message goes to every subscriber.
傳統的訊息系統有兩種模型, 佇列模型和釋出訂閱模型, 在訂閱模型中, 一群消費者從伺服器讀取記錄, 每條記錄會分發到其中一個消費者中, 在釋出和訂閱模型中, 記錄分發給所有的消費者. 這兩種模型都有各自的優缺點, 佇列的優點是它允許你把資料處理提交到多個消費者例項中, 適用於資料處理的水平擴充套件, 但是佇列不是多訂閱的, 一旦其中的一個消費者讀取了記錄, 則記錄就算處理過了. 在釋出訂閱模型中允許你廣播到記錄到不同的訂閱者上, 但是這種方式沒法對不同的訂閱者進行負載均攤
The consumer group concept in Kafka generalizes these two concepts. As with a queue the consumer group allows you to divide up processing over a collection of processes (the members of the consumer group). As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
kafka的消費組產生源於對著兩種概念的融合,在佇列模型中, 它允許你把記錄分攤在同一個消費組的不同處理者身上, 在訂閱和釋出模型中, 它允許你把消費廣播到不同的消費組中
The advantage of Kafka’s model is that every topic has both these properties—it can scale processing and is also multi-subscriber—there is no need to choose one or the other.
kafka這個模型的好處是, 這樣每個topic都能同時擁有這樣的屬性, 既能消費者有水平擴充套件的處理能力, 又能允許有多個不同的訂閱者–不需要讓使用者選擇到底是要使用佇列模型還是釋出訂閱模型
Kafka has stronger ordering guarantees than a traditional messaging system, too.
Kafka也比傳統的訊息系統有更強的訊息順序保證
A traditional queue retains records in-order on the server, and if multiple consumers consume from the queue then the server hands out records in the order they are stored. However, although the server hands out records in order, the records are delivered asynchronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the records is lost in the presence of parallel consumption. Messaging systems often work around this by having a notion of “exclusive consumer” that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
傳統的佇列在伺服器端按順序儲存記錄, 如果有多個消費者同時從伺服器端讀取資料, 則伺服器按儲存的順序分發記錄. 但是儘管伺服器按順序分發記錄, 這些記錄使用非同步分發到消費者上, 所以記錄到不同的消費者時順序可能是不一致的. 這就是說記錄的順序有可能在記錄被併發消費時已經被丟失了, 在訊息系統中為了支援順序消費這種情況經常使用一個概念叫做”獨佔消費者”, 表示只允許一個消費者去訂閱佇列, 這也意味了犧牲掉記錄並行處理能力
Kafka does it better. By having a notion of parallelism—the partition—within the topics, Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. Note however that there cannot be more consumer instances in a consumer group than partitions.
kafka在這點上做得更好些, 通過對日誌提出分割槽的概念, kafka保證了記錄處理的順序和對一組消費者例項進行負載分攤的水平擴充套件能力. 通過把topic中的分割槽唯一指定消費者分組中的某個消費者, 這樣可以保證僅且只有這樣的一個消費者例項從這個分割槽讀取資料, 並按順序進行消費. 這樣topic中的多個分割槽就可以分攤到多個消費者例項上, 當然消費者的數量不能比分割槽數量多, 否則有些消費者將分配不到分割槽.
Kafka as a Storage System kafka當作儲存系統
Any message queue that allows publishing messages decoupled from consuming them is effectively acting as a storage system for the in-flight messages. What is different about Kafka is that it is a very good storage system.
作為儲存系統, 任意訊息佇列都允許釋出到訊息佇列中, 並能高效消費這些訊息記錄, kafka不同的地方是它是一個很好的儲存系統
Data written to Kafka is written to disk and replicated for fault-tolerance. Kafka allows producers to wait on acknowledgement so that a write isn’t considered complete until it is fully replicated and guaranteed to persist even if the server written to fails.
資料寫入kafka時被寫入到磁碟, 並複製到其他伺服器上進行容錯, kafka允許生產者只有在訊息已經複製完, 並存儲後才得到寫成功的通知, 否則就認為失敗.
The disk structures Kafka uses scale well—Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server.
磁碟結構kafka也很有效率利用了–無論你儲存的是50KB或50TB的資料在kafka上, kafka都會有同樣的效能
As a result of taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation.
對於那些需要認真考慮儲存效能, 並允許客戶端自主控制讀取位置的, 你可以把kafka當作是一種特殊的分散式檔案系統, 並致力於高效能, 低延遲提交日誌儲存, 複製和傳播.
Kafka for Stream Processing kafka作為資料流處理
It isn’t enough to just read, write, and store streams of data, the purpose is to enable real-time processing of streams.
僅僅讀取、寫入和儲存資料流是不夠的,最終的目的是使流實時處理.。
In Kafka a stream processor is anything that takes continual streams of data from input topics, performs some processing on this input, and produces continual streams of data to output topics.
kafka的流資料處理器是持續從輸入的topic讀取連續的資料流, 進行資料處理, 轉換, 後產生連續的資料流輸出到topic中
For example, a retail application might take in input streams of sales and shipments, and output a stream of reorders and price adjustments computed off this data.
例如,一個零售的應用可能需要在獲取銷售和出貨量的輸入流, 在計算分析了之後, 重新輸出價格調整的記錄
It is possible to do simple processing directly using the producer and consumer APIs. However for more complex transformations Kafka provides a fully integrated Streams API. This allows building applications that do non-trivial processing that compute aggregations off of streams or join streams together.
通常情況下可以直接使用提供者或消費者的api方法做些簡單的處理. 但是kafka通過stream api 也提供一些更復雜的資料轉換處理機制, stream api可以讓應用計算流的聚合或流的歸
This facility helps solve the hard problems this type of application faces: handling out-of-order data, reprocessing input as code changes, performing stateful computations, etc.
這些功能有助於解決一些應用上的難題: 處理無序的資料, 在編碼修改後從新處理輸入資料, 執行有狀態的計算等
The streams API builds on the core primitives Kafka provides: it uses the producer and consumer APIs for input, uses Kafka for stateful storage, and uses the same group mechanism for fault tolerance among the stream processor instances.
流的api基於kafka的核心基本功能上構建的: 它使用生產者和消費者提供的api作為輸入輸出, 使用kafka作為狀態儲存, 使用一樣的分組機制在不同的流處理器上進行容錯
Putting the Pieces Together 把各個塊整合起來
This combination of messaging, storage, and stream processing may seem unusual but it is essential to Kafka’s role as a streaming platform.
組合訊息, 儲存, 流處理這些看起來不太平常, 但是這些仍然是kafka的作流處理平臺的主要功能
A distributed file system like HDFS allows storing static files for batch processing. Effectively a system like this allows storing and processing historical data from the past.
像hdfs分散式檔案處理系統, 允許儲存靜態資料用於批處理, 能使得系統在處理和分析過往的歷史資料時更為有效
A traditional enterprise messaging system allows processing future messages that will arrive after you subscribe. Applications built in this way process future data as it arrives.
像傳統的訊息系統, 允許處理在你訂閱之前的資訊, 像這樣的應用可以處理之前到達的資料
Kafka combines both of these capabilities, and the combination is critical both for Kafka usage as a platform for streaming applications as well as for streaming data pipelines.
kafka整合和所有這些功能, 這些組合包括把kafka平臺當作一個流處理應用, 或者是作為流處理的管道
By combining storage and low-latency subscriptions, streaming applications can treat both past and future data the same way. That is a single application can process historical, stored data but rather than ending when it reaches the last record it can keep processing as future data arrives. This is a generalized notion of stream processing that subsumes batch processing as well as message-driven applications.
通過組合資料儲存和低訂閱開銷, 流處理應用可以平等對待之前到達記錄或即將到達的記錄, 這就是一個應用可以處理歷史儲存的資料, 也可以在讀到最後記錄後, 保持等待未來的資料進行處理. 這是流處理,包括批處理以及訊息驅動的應用的一個廣義的概念
Likewise for streaming data pipelines the combination of subscription to real-time events make it possible to use Kafka for very low-latency pipelines; but the ability to store data reliably make it possible to use it for critical data where the delivery of data must be guaranteed or for integration with offline systems that load data only periodically or may go down for extended periods of time for maintenance. The stream processing facilities make it possible to transform data as it arrives.
同樣的像流處理管道, 使用kafka在實時事件系統能實現比較低的延遲管道; 在kafka的儲存能力, 使得一些離線系統, 如定時載入資料, 或者維護宕機時資料分發能力更有保障性. 流處理功能在資料到達時進行資料轉換處理
For more information on the guarantees, apis, and capabilities Kafka provides see the rest of the documentation.
更多關於kafka提供的功能, 服務和api, 可以檢視後文
Here is a description of a few of the popular use cases for Apache Kafka™. For an overview of a number of these areas in action, see this blog post.
這裡提供者一些常用的Kafak使用場景, 更多這些領域的詳細說明可以參考這裡, this blog post.
Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
Kafka 可以很好替代傳統的訊息伺服器, 訊息伺服器的使用有多方面的原因(比如, 可以從生產者上解耦出資料處理, 緩衝未處理的資料), 相比其它訊息系統, kafka有更好的吞吐量, 分割槽機制, 複製和容錯能力, 更能適用於大規模的線上資料處理
In our experience messaging uses are often comparatively low-throughput, but may require low end-to-end latency and often depend on the strong durability guarantees Kafka provides.
從經驗來看, 訊息系統一般吞吐量都比較小, 更多的是要求更低的端到端的延遲, 這些功能都可以依賴於kafka的高可保障
In this domain Kafka is comparable to traditional messaging systems such as ActiveMQ or RabbitMQ.
在這個領域上, kafka可以類比於傳統的訊息系統, 如: ActiveMQ or RabbitMQ.
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
kafka最通常一種使用方式是通過構建使用者活動跟蹤管道作為實時釋出和訂閱反饋佇列. 頁面操作(檢視, 檢索或任何使用者操作)都可以按活動型別傳送的不同的topic上, 這些反饋資訊, 有助於構建一個實時處理, 實時監控, 或載入到hadoop叢集, 構建資料倉庫用於離線處理和分析
Activity tracking is often very high volume as many activity messages are generated for each user page view.
由於每個使用者頁面訪問都要記錄, 活動日誌跟蹤一般會有大量的訪問訊息被記錄
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Kafak還經常用於執行監控資料的儲存, 這涉及到對分散式應用的執行數的及時彙總統計
Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
很多人使用kafka作為日誌彙總的替代品. 典型的情況下, 日誌彙總從物理機上採集回來並忖道中央儲存中心(如hdfs分散式檔案系統)後等待處理, kafka將檔案的細節抽象出來,並將日誌或事件資料清理和轉換成訊息流. 這方便與地延遲的資料處理, 更容易支援多個數據源, 和分散式的資料消費. 比起典型的日誌中心繫統如Scribe或者flume 系統, kafka提供等同更好的效能, 更強大的複製保證和更低的端到端的延遲
Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing. For example, a processing pipeline for recommending news articles might crawl article content from RSS feeds and publish it to an “articles” topic; further processing might normalize or deduplicate this content and published the cleansed article content to a new topic; a final processing stage might attempt to recommend this content to users. Such processing pipelines create graphs of real-time data flows based on the individual topics. Starting in 0.10.0.0, a light-weight but powerful stream processing library called Kafka Streams is available in Apache Kafka to perform such data processing as described above. Apart from Kafka Streams, alternative open source stream processing tools include Apache Storm and Apache Samza.
更多的kafka使用者在處理資料時一般都是多流程多步驟的, 原始資料從kafka的topic裡面被讀取, 然後彙總, 分析 然後轉換到新的topic中進行後續的消費處理. 例如, 文章推薦處理管道肯能從RSS feeds裡面抓取文章內容, 然後釋出到文章這個topic中, 後面在繼續規範化處理,除去重複後釋出到另外一個新的topic中去, 一個最終的步驟可能是把文章內容推薦給使用者, 像這樣的實時系統流資料處理管道基於各個獨立的topic, 從0.10.0.0開始, kafak提供一個輕量級, 但是非常強大的流處理api叫做 Kafka Streams , 可以處理上述描述的任務情景. 除了kafka的流機制外, 可選擇開源專案有e Apache Storm 和 Apache Samza.
Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka’s support for very large stored log data makes it an excellent backend for an application built in this style.
時間記錄是應用在狀態變化時按時間順序依次記錄狀態變化日誌的一種設計風格. kafka很適合作為這種風格的後端伺服器
Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data. The log compaction feature in Kafka helps support this usage. In this usage Kafka is similar to Apache BookKeeperproject.
Kafka適用於分散式系統的外部提交日誌, 這些日誌方便於在節點間進行復制, 並在伺服器故障是提供重新同步機能. kafka的日誌壓縮特性有利於這方面的使用, 這個特性有點兒像Apache BookKeeper 這個專案
This tutorial assumes you are starting fresh and have no existing Kafka™ or ZooKeeper data. Since Kafka console scripts are different for Unix-based and Windows platforms, on Windows platforms use bin\windows\ instead of bin/, and change the script extension to .bat.
該入門指南假定你對kafka和zookeeper是個新手, kafka的控制檯腳步window和unix系統不一樣, 如果在window系統, 請使用 bin\windows\目錄下的指令碼, 而不是使用bin/, 下的指令碼
Download the 0.10.1.0 release and un-tar it. 下載 0.10.1.0 版本並解壓
> tar -xzf kafka_2.11-0.10.1.0.tgz > cd kafka_2.11-0.10.1.0
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don’t already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.
由於kafka使用ZooKeepe伺服器, 如果你沒有zookeeper伺服器需要先啟動一個, 你可以使用kafka已經打包好的快捷指令碼用於建立一個單個節點的zookeeper例項
> bin/zookeeper-server-start.sh config/zookeeper.properties [2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ...
Now start the Kafka server: 現在可以啟動kafka伺服器
> bin/kafka-server-start.sh config/server.properties [2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) ...
Let’s create a topic named “test” with a single partition and only one replica: 建立一個只有一個分割槽和一個副本的topic叫做”test”,
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
We can now see that topic if we run the list topic command: 如果使用檢視topic檢視命令, 我們就可以看到所有topic列表
> bin/kafka-topics.sh --list --zookeeper localhost:2181 test
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
還有一種可選的方式, 如果不想手動建立topic, 你可以配置伺服器在訊息發時, 自動建立topic物件
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default, each line will be sent as a separate message.
kafka自帶的命令列終端指令碼, 可以從檔案或標準輸入讀取行輸入, 併發送訊息到kafka叢集, 預設每行資料當作一條獨立的訊息進行傳送
Run the producer and then type a few messages into the console to send to the server.
執行釋出者終端腳步, 然後從終端輸入一些訊息後傳送到伺服器
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is a message This is another message
Kafka also has a command line consumer that will dump out messages to standard output.
kafka也自帶一個消費者命令列終端指令碼, 可以把訊息列印到終端上
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning This is a message This is another message
If you have each of the above commands running in a different terminal then you should now be able to type messages into the producer terminal and see them appear in the consumer terminal.
如果上面的兩個命令跑在不同的終端上, 則從提供者終端輸入訊息, 會在消費者終端展現出來
All of the command line tools have additional options; running the command with no arguments will display usage information documenting them in more detail.
上面的命令都需要而外的命令列引數, 如果只輸入命令不帶任何引數, 則會提示更多關於該命令的使用說明
So far we have been running against a single broker, but that’s no fun. For Kafka, a single broker is just a cluster of size one, so nothing much changes other than starting a few more broker instances. But just to get feel for it, let’s expand our cluster to three nodes (still all on our local machine).
到現在為止, 我們只跑了當個伺服器例項, 但是這個不好玩, 對於kafka來說, 單個伺服器例項意味著這個叢集只有一個成員, 如果要啟動多個例項也不需要做太多的變化. 現在來感受下, 把我們的叢集擴充套件到3個機器(在同一臺物理機上)
First we make a config file for each of the brokers (on Windows use the copy command instead):
所需我們給每個不同的伺服器複製一份不同的配置檔案
> cp config/server.properties config/server-1.properties > cp config/server.properties config/server-2.properties
Now edit these new files and set the following properties:現在重新配置這些新的檔案
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
The property is the unique and permanent name of each node in the cluster. We have to override the port and log directory only because we are running these all on the same machine and we want to keep the brokers from all trying to register on the same port or overwrite each other’s data.
broker.id 屬性對於叢集中的每個伺服器例項都必須是唯一的且不變的, 我們重新了埠號和日誌目錄, 是因為我們例項都是跑在同一臺物理機器上, 需要使用不同的埠和目錄來防止衝突
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
我們已經有了Zookeeper伺服器, 而且已經有啟動一個例項, 現在我們再啟動2個例項
> bin/kafka-server-start.sh config/server-1.properties & ... > bin/kafka-server-start.sh config/server-2.properties & ...
Now create a new topic with a replication factor of three: 現在可以建立一個topic包含3個副本
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Okay but now that we have a cluster how can we know which broker is doing what? To see that run the “describe topics” command:
Ok, 現在如果我們怎麼知道那個例項在負責什麼? 可以通過 “describe topics”命令檢視
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Here is an explanation of output. The first line gives a summary of all the partitions, each additional line gives information about one partition. Since we have only one partition for this topic there is only one line.
這裡解析下輸出資訊, 第一行是所有的分割槽彙總, 每行分割槽的詳細資訊, 因為我們只有一個分割槽, 所以只有一行
- “leader” is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
- “leader”表示這個例項負責響應指定分割槽的讀寫請求, 每個例項都有可能被隨機選擇為部分分割槽的leader負責人
- “replicas” is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive.
- “replicas” 表示當前分割槽分發的所有副本所在的所有例項列表, 不管這個例項是否有存活
- “isr” is the set of “in-sync” replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.
- “isr” 表示儲存當前分割槽的日誌都已經同步到leader的伺服器的例項集合
Note that in my example node 1 is the leader for the only partition of the topic. 注意我這個例子只有例項1是主伺服器, 因為topic只有一個分割槽
We can run the same command on the original topic we created to see where it is: 我們可以運行同樣的命令在原來建立的topic上
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
So there is no surprise there—the original topic has no replicas and is on server 0, the only server in our cluster when we created it.
意料之中, 原來的topic沒有副本, 而且由例項0負責, 例項0是我們叢集最初建立時的唯一例項
Let’s publish a few messages to our new topic: 我們釋出點訊息到新的主題上
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic ... my test message 1 my test message 2 ^C
Now let’s consume these messages: 現在我們開始消費這些訊息
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
Now let’s test out fault-tolerance. Broker 1 was acting as the leader so let’s kill it: 現在,讓我們測試下容錯能力, 例項1現在是主伺服器, 我們現在把它kill掉
> ps aux | grep server-1.properties 7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.8/Home/bin/java... > kill -9 7564
On Windows use:
> wmic process get processid,caption,commandline | find "java.exe" | find "server-1.properties" java.exe java -Xmx1G -Xms1G -server -XX:+UseG1GC ... build\libs\kafka_2.10-0.10.1.0.jar" kafka.Kafka config\server-1.properties 644 > taskkill /pid 644 /f
Leadership has switched to one of the slaves and node 1 is no longer in the in-sync replica set: 主伺服器切換到原來的兩個從伺服器裡面, 原來的例項1也不在同步副本里面了
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
But the messages are still available for consumption even though the leader that took the writes originally is down: 但是訊息還是可以消費, 儘管原來接受訊息的主伺服器已經宕機了
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
Writing data from the console and writing it back to the console is a convenient place to start, but you’ll probably want to use data from other sources or export data from Kafka to other systems. For many systems, instead of writing custom integration code you can use Kafka Connect to import or export data.
從控制太寫入和讀取資料方便大家開始學習, 但是你可能需要從其他系統匯入到kafka或從kafka匯出資料到其它系統. 對於很多系統, 你不需要寫寫特定的整合程式碼, 只需要使用Kafka Connect提供的功能進行匯入匯出
Kafka Connect is a tool included with Kafka that imports and exports data to Kafka. It is an extensible tool that runs connectors, which implement the custom logic for interacting with an external system. In this quickstart we’ll see how to run Kafka Connect with simple connectors that import data from a file to a Kafka topic and export data from a Kafka topic to a file.
Kafka Connect工具包含資料的匯入和匯出, 它可以是一個外部工具connectors, 和外部系統互動實現特定的業務邏輯後. 在下面的例子中我們會看到一個簡單的聯結器, 從檔案中讀取資料寫入到kafka, 和從kafka的topic中匯出資料到檔案中去
First, we’ll start by creating some seed data to test with:
首先, 我們先建立一些隨機的測試資料
> echo -e "foo\nbar" > test.txt
Next, we’ll start two connectors running in standalone mode, which means they run in a single, local, dedicated process. We provide three configuration files as parameters. The first is always the configuration for the Kafka Connect process, containing common configuration such as the Kafka brokers to connect to and the serialization format for data. The remaining configuration files each specify a connector to create. These files include a unique connector name, the connector class to instantiate, and any other configuration required by the connector.
接下來, 我們啟動兩個獨立聯結器, 這意味著它們以單一的,本地的,專用的程序進行執行. 我們以引數的形式提供三個配置檔案, 第一個引數是kafka聯結器常用的一些配置, 包含kafka連線的伺服器器地址, 資料的序列化格式等. 剩下的配置檔案各自包含一個要建立的聯結器, 這些檔案包含一個唯一的聯結器名稱, 聯結器對於的啟動類, 還任何聯結器需要的其他配置資訊
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
These sample configuration files, included with Kafka, use the default local cluster configuration you started earlier and create two connectors: the first is a source connector that reads lines from an input file and produces each to a Kafka topic and the second is a sink connector that reads messages from a Kafka topic and produces each as a line in an output file.
在這些樣例包含kafka之前啟動的預設本地的叢集, 和啟動兩個聯結器, 第一個輸入聯結器負責從一個檔案按行讀取資料, 併發布到kafka的topic上去, 第二個是一個輸入聯結器, 負責從kafka的topic中讀取資料, 並按行輸出到檔案中
During startup you’ll see a number of log messages, including some indicating that the connectors are being instantiated. Once the Kafka Connect process has started, the source connector should start reading lines from test.txt and producing them to the topic connect-test, and the sink connector should start reading messages from the topic connect-test and write them to the file test.sink.txt. We can verify the data has been delivered through the entire pipeline by examining the contents of the output file:
在啟動的時候, 你會看到一些日誌資訊, 包括聯結器初始化的啟動資訊. 一旦kafka聯結器啟動起來, 源聯結器從test.txt 檔案中讀取行記錄, 併發布到connect-test的主題中, 輸出聯結器開始從connect-test主題中讀取資料, 並寫入到 test.sink.txt 檔案中, 我們可以根據輸出檔案的內容, 檢測這個管道的資料傳送是否正常
> cat test.sink.txt foo bar
Note that the data is being stored in the Kafka topic connect-test, so we can also run a console consumer to see the data in the topic (or use custom consumer code to process it):
現在資料已經儲存到connect-test主題中, 所以, 我們可以跑一個終端消費者來檢視主題中的資料(或者編寫特定的消費進行處理)
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
The connectors continue to process data, so we can add data to the file and see it move through the pipeline:
聯結器持續在處理資料, 所以我們可以把資料寫入到檔案中, 檢視到資料是否通過這個管道處理
> echo "Another line" >> test.txt
You should see the line appear in the console consumer output and in the sink file.
你可以看到那些從消費者終端輸入的行, 都會寫入到輸出檔案中
Kafka Streams is a client library of Kafka for real-time stream processing and analyzing data stored in Kafka brokers. This quickstart example will demonstrate how to run a streaming application coded in this library. Here is the gist of the WordCountDemo example code (converted to use Java 8 lambda expressions for easy reading).
Kafka Streams 是kafka提供用於對儲存到kafka伺服器中的資料進行實時分析和資料處理的庫. 這裡展示了怎麼使用該庫進行流處理的一個樣例, 這裡是提供了WorkCountDemo樣例的部分程式碼(為了方便閱讀使用java 8 lambda表示式方式)
KTable wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Ensure the words are available as record keys for the next aggregate operation.
.map((key, value) -> new KeyValue<>(value, value))
// Count the occurrences of each word (record key) and store the results into a table named "Counts".
.countByKey("Counts")
It implements the WordCount algorithm, which computes a word occurrence histogram from the input text. However, unlike other WordCount examples you might have seen before that operate on bounded data, the WordCount demo application behaves slightly differently because it is designed to operate on an infinite, unbounded stream of data. Similar to the bounded variant, it is a stateful algorithm that tracks and updates the counts of words. However, since it must assume potentially unbounded input data, it will periodically output its current state and results while continuing to process more data because it cannot know when it has processed “all” the input data.
這裡實現從輸入文字中統計單詞出現次數的演算法. 和其他的有限輸入的單詞計數演算法不一樣, 這個樣例有點不一樣, 因為它的輸入流是無限, 沒有邊界的資料流資料, 類似有邊界的輸入, 這裡包含有狀態的演算法用於跟蹤和更新單詞技術. 當然, 由於處理的資料是沒有邊界的, 處理程式並不知道什麼時候已經處理完全部的輸入資料, 因此, 它在處理資料的同時, 並定時輸出當前的狀態和結果,
We will now prepare input data to a Kafka topic, which will subsequently be processed by a Kafka Streams application.
我們現在為流處理應用準備點資料到kafka的主題中
> echo -e "all streams lead to kafka\nhello kafka streams\njoin kafka summit" > file-input.txt
Or on Windows:
> echo all streams lead to kafka> file-input.txt > echo hello kafka streams>> file-input.txt > echo|set /p=join kafka summit>> file-input.txt
Next, we send this input data to the input topic named streams-file-input using the console producer (in practice, stream data will likely be flowing continuously into Kafka where the application will be up and running):
接下來, 我們使用終端生產者把資料輸入到streams-file-input主題中(實際生產中, 在應用啟動時, 流資料將會持續輸入到kafka中)
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-file-input
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-file-input < file-input.txt
We can now run the WordCount demo application to process the input data: 現在我們跑下WordCount 樣例來處理這些資料.
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
There won’t be any STDOUT output except log entries as the results are continuously written back into another topic named streams-wordcount-output in Kafka. The demo will run for a few seconds and then, unlike typical stream processing applications, terminate automatically.
We can now inspect the output of the WordCount demo application by reading from its output topic:
這裡不會有任何日誌輸出到標準輸出, 然後, 有持續的結果輸出到kafka另外一個主題叫做 streams-wordcount-output , 和其它的流處理系統不一樣, 樣例只會跑幾秒鐘然後自動停止了. 我們可以從輸出主題中讀取資料來檢測WordCount樣例的資料處理結果.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
with the following output data being printed to the console: 將會有如下的資料輸出到控制檯上
all 1 lead 1 to 1 hello 1 streams 2 join 1 kafka 3 summit 1
Here, the first column is the Kafka message key, and the second column is the message value, both in in java.lang.String format. Note that the output is actually a continuous stream of updates, where each data record (i.e. each line in the original output above) is an updated count of a single word, aka record key such as “kafka”. For multiple records with the same key, each later record is an update of the previous one.
這裡, 第一欄是kafka訊息的鍵值, 第二欄是訊息值, 都是使用java.lang.String的格式, 注意, 輸出實際是上持續資料流的更新, 每條記錄都是對每個單詞的持續更新計數, 比如 “kafka”這個單詞的記錄. 如果多條記錄有相同的鍵, 則每條記錄都會更新計數器.
Now you can write more input messages to the streams-file-input topic and observe additional messages added to streams-wordcount-output topic, reflecting updated word counts (e.g., using the console producer and the console consumer, as described above).
You can stop the console consumer via Ctrl-C.
現在, 你可以寫入更多的訊息到streams-file-input 主題中, 然後觀察另外輸出到streams-wordcount-output主題中的記錄中被更新的單詞計數(e.g, 使用前面提到的終端生產者和終端消費者)
There are a plethora of tools that integrate with Kafka outside the main distribution. The ecosystem page lists many of these, including stream processing systems, Hadoop integration, monitoring, and deployment tools.
在kafka發行的主版本外, 還有大量整合了kafka的工具. 這裡 有羅列大量的工具, 包括流的線上處理系統, hadoop整合, 監控 和部署工具
0.10.1.0 has wire protocol changes. By following the recommended rolling upgrade plan below, you guarantee no downtime during the upgrade. However, please notice the Potential breaking changes in 0.10.1.0 before upgrade.
Note: Because new protocols are introduced, it is important to upgrade your Kafka clusters before upgrading your clients (i.e. 0.10.1.x clients only support 0.10.1.x or later brokers while 0.10.1.x brokers also support older clients).
For a rolling upgrade:
- Update server.properties file on all brokers and add the following properties:
- inter.broker.protocol.version=CURRENT_KAFKA_VERSION (e.g. 0.8.2.0, 0.9.0.0 or 0.10.0.0).
- log.message.format.version=CURRENT_KAFKA_VERSION (See potential performance impact following the upgrade for the details on what this configuration does.)
- Upgrade the