
Hive中的去重 :distinct,group by與ROW_Number()視窗函式
阿新 • • 發佈:2018-12-23
一、distinct,group by與ROW_Number()視窗函式使用方法
1. Distinct用法:對select 後面所有欄位去重,並不能只對一列去重。
(1)當distinct應用到多個欄位的時候,distinct必須放在開頭,其應用的範圍是其後面的所有欄位,而不只是緊挨著它的一個欄位,而且distinct只能放到所有欄位的前面
(2)distinct對NULL是不進行過濾的,即返回的結果中是包含NULL值的
(3)聚合函式中的DISTINCT,如 COUNT( ) 會過濾掉為NULL 的項
2.group by用法:對group by 後面所有欄位去重,並不能只對一列去重。
3. ROW_Number() over()視窗函式
注意:ROW_Number() over (partition by id order by time DESC) 給每個id加一列按時間倒敘的rank值,取rank=1
select m.id,m.gender,m.age,m.rank
from (select id,gender,age,ROW_Number() over(partition by id order by id) rank
from temp.control_201804to201806
where id!='NA' and gender!='' or age!=''
) m
where m.rank=1
二、案例:
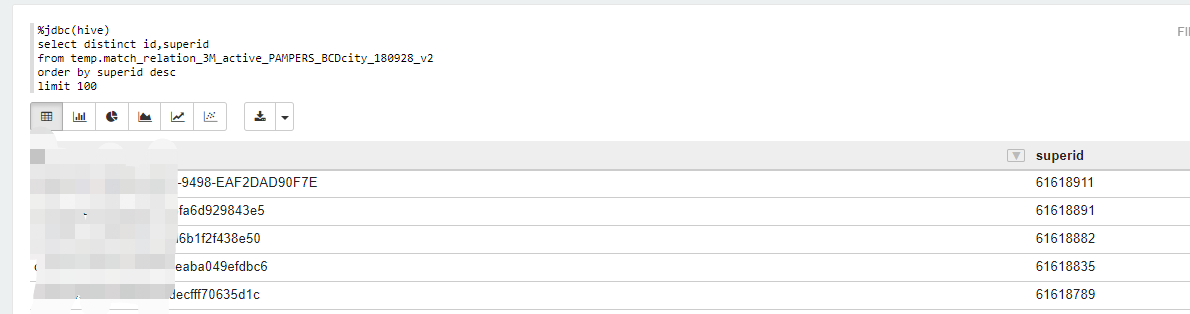
1.表中有兩列:id ,superid,按照superid倒序排序選出前100條不同的id,如下:
1.方案一:
子查詢中對id,superid同時去重,可能存在一個id對應的superid不同,id這一列有重複的id,但 是結果只需要一列不同的id,如果時不限制數量,則可以選擇這種方法
%jdbc(hive) create table temp.match_relation_3M_active_v5 as select a.id from (select distinct id,superid from temp.match_relation_3M_activ order by superid desc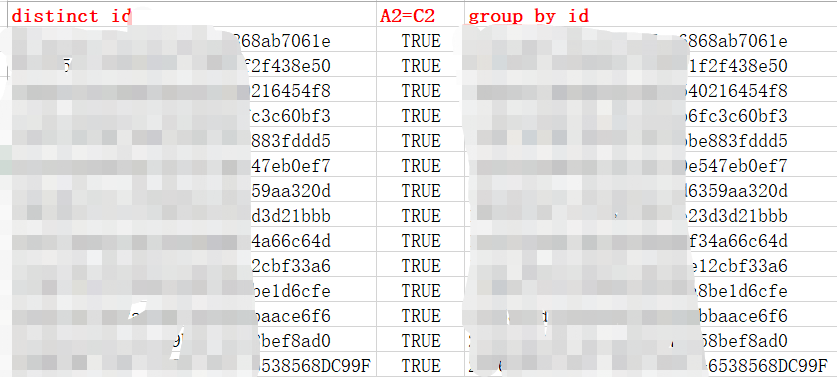
方案二:
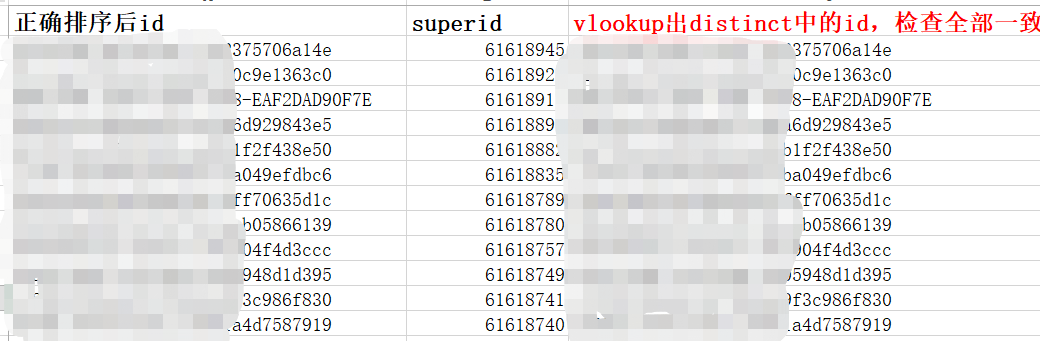
因為要求按照superid倒序排序選出,而一個id對應的superid不同,必有大有小,選出最大的那一個,即可。 同理若是按照superid正序排列,可以選出最小的一列
%jdbc(hive) create table temp.match_relation_3M_active_v7 as select a.id from (select id,max(superid) as superid from temp.match_relation_3M_active group by id order by superid desc limit 100 ) a
方案三:
首先利用視窗函式ROW_Number() over()視窗函式對id這一列去重,不能用distinct或者group by對id,superid同時去重
%jdbc(hive) create table temp.match_relation_3M_active_v11 as select n.id from (select m.id,superid from (select id,superid,ROW_Number() over(partition by id order by id) rank from temp.match_relation_3M_active ) m where m.rank=1 order by superid desc limit 100 )n 注意,以下程式碼中,視窗函式ROW_Number() over()的執行順序晚於 order by superid desc,最終的結果並非 superid的倒敘排列的結果 %jdbc(hive) create table temp.match_relation_3M_active_v9 as select m.id from (select id, superid,ROW_Number() over(partition by id order by id) rank from temp.match_relation_3M order by superid desc ) m where m.rank=1 group by m.id limit 100