
人工智慧晶片與傳統晶片的區別
作為AI和晶片兩大領域的交差點,AI晶片已經成了最熱門的投資領域,各種AI晶片如雨後春筍冒出來,但是AI晶片領域生存環境惡劣,能活下來的企業將是鳳毛麟角。
谷歌在I/O大會發布了其第三代TPU,並宣稱其效能比去年的TUP 2.0提升8倍之多,達到每秒1000萬億次浮點計算,同時谷歌展示了其一系列基於TPU的AI應用。
可以說,AI已經成為科技行業除了區塊鏈之外最熱門的話題。AI晶片作為AI時代的基礎設施,也成為目前行業最熱門的領域。
可以看到,AI晶片已經成為資本追逐的最熱門領域,資本對半導體晶片的熱情被AI技術徹底點燃。在創業公司未真正開啟市場的情況下,AI晶片初創企業已經誕生了不少的獨角獸,多筆融資已經超過億元。
AI技術的革新,其從計算構架到應用,都和傳統處理器與演算法有巨大的差異,這給創業者和資本市場無限的遐想空間,這也是為什麼資本和人才對其趨之若鶩的原因。
但是,產業發展還是要遵循一定的產業規律,筆者認為,絕大多數AI晶片公司都將成為歷史的炮灰,最後,在雲端和終端只剩下為數極少的幾個玩家。
首先我們來分析下目前對AI晶片的需求主要集中在哪些方面。
先來講講AI目前晶片大致的分類:從應用場景角度看,AI晶片主要有兩個方向,一個是在資料中心部署的雲端,一個是在消費者終端部署的終端。從功能角度看,AI晶片主要做兩個事情,一是Training(訓練),二是Inference(推理)。
目前AI晶片的大規模應用分別在雲端和終端。雲端的AI晶片同時做兩個事情:Training和Inference。Training即用大量標記過的資料來“訓練”相應的系統,使之可以適應特定的功能,比如給系統海量的“貓”的圖片,並告訴系統這個就是“貓”,之後系統就“知道”什麼是貓了;Inference即用訓練好的系統來完成任務,接上面的例子,就是你將一張圖給之前訓練過的系統,讓他得出這張圖是不是貓這樣的結論。
Training和Inference在目前大多數的AI系統中,是相對獨立的過程,其對計算能力的要求也不盡相同。
Training需要極高的計算效能,需要較高的精度,需要能處理海量的資料,需要有一定的通用性,以便完成各種各樣的學習任務。
對於晶片廠家來說,誰有資料,誰贏!
那麼哪些晶片廠家有大量的使用者資料呢?BAT。按照這個邏輯、包括科大訊飛和華為未來也未必有足夠的機會。誰有大量的資料,誰更有機會。
Inference相對來說對效能的要求並不高,對精度要求也要更低,在特定的場景下,對通用性要求也低,能完成特定任務即可,但因為Inference的結果直接提供給終端使用者,所以更關注使用者體驗的方面的優化。
谷歌TensorFlow團隊:深度學習的未來,在微控制器的身上
Pete Warden,是谷歌TensorFlow團隊成員,也是TensorFLow Mobile的負責人。
Pete 堅定地相信,未來的深度學習能夠在微型的、低功耗的晶片上自由地奔跑。
換句話說,微控制器 (MCU) ,有一天會成為深度學習最肥沃的土壤。
為什麼是微控制器
微控制器遍地都是
今年一年全球會有大約400億枚微控制器 (MCU) 售出。MCU裡面有個小CPU,RAM只有幾kb的那種,但醫療裝置、汽車裝置、工業裝置,還有消費級電子產品裡,都用得到。
這樣的計算機,需要的電量很小,價格也很便宜,大概不到50美分。
之所以得不到重視,是因為一般情況下,MCU都是用來取代 (如洗衣機裡、遙控器裡的) 那些老式的機電系統——控制機器用的邏輯沒有發生什麼變化。
CPU和感測器不太耗電,傳輸耗錢、耗電!
CPU和感測器的功耗,基本可以降到微瓦級,比如高通的Glance視覺晶片。
相比之下,顯示器和無線電,就尤其耗電了。即便是WiFi和藍芽也至少要幾十毫瓦。
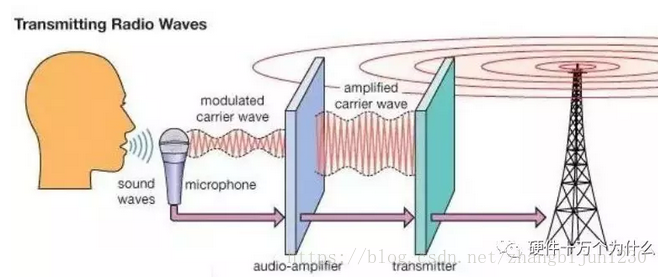
因為,資料傳輸需要的能量,似乎與傳輸距離成正比。CPU和感測器只傳幾毫米,如果每個資料都需要端管雲這樣傳輸,每個演算法都需要輸送到雲端進行處理,自然代價就要貴得多。
感測器的資料很多,傳輸起來很費勁!
感測器能獲取的資料,比人們能用到的資料,多得多。
例如:衛星的圖片資料很多,但是傳到地球很困難。
衛星或者宇宙飛船上的宇航員可以用高清相機來拍高清視訊。但問題是,衛星的資料儲存量很小,傳輸頻寬也很有限,從地球上每小時只能下載到一點點資料。
地球上的很多感測器也一樣,本地獲得很容易,但是傳輸到遠端的資料中心就需要很多的代價。
跟深度學習有什麼關係
如果感測器的資料可以在本地運算,又不需要很多的代價和電力。
我們需要的是,能夠在微控制器上運轉的,不需要很多電量的,依賴計算不依賴無線電,並且可以把那些本來要浪費掉的感測器資料利用起來的。
這也是機器學習,特別是深度學習,需要跨越的鴻溝。
相比之下,神經網路大部分的時間,都是用來把那些很大很大的矩陣乘到一起,翻來覆去用相同的數字,只是組合方式不同了。
這樣的運算,當然比從DRAM裡讀取大量的數值,要低碳得多。
需要的資料沒那麼多的話,就可以用SRAM這樣低功耗的裝置來儲存。
如此說來,深度學習最適合MCU了,尤其是在8位元計算可以代替浮點運算的時候。
深度學習很低碳
那麼AI的計算,每次運算需要多少皮焦耳?
比如,MobileNetV2的影象分類網路,的最簡單的結構,大約要用2,200萬次運算。
如果,每次運算要5皮焦,每秒鐘一幀的話,這個網路的功率就是110微瓦,用鈕釦電池也能堅持近一年。
對感測器也友好
最近幾年,人們用神經網路來處理噪音訊號,比如影象、音訊、加速度計的資料等等。
如果可以在MCU上執行神經網路,那麼更大量的感測器資料就可以得到處理,而不是浪費。
那時,不管是語音互動,還是影象識別功能,都會變得更加輕便。
Training將在很長一段時間裡集中在雲端,Inference的完成目前也主要集中在雲端,但隨著越來越多廠商的努力,很多的應用將逐漸轉移到終端。
然後我們來看看目前的市場情況。
雲端AI晶片市場已被巨頭瓜分殆盡,創業公司生存空間幾乎消失。
雲端AI晶片無論是從硬體還是軟體,已經被傳統巨頭控制,給新公司預留的空間極小。不客氣的說,大多數AI晶片公司、希望在雲端AI做文章的初創公司幾乎最後都得死。
資料越多,對應用場景越理解的公司,對演算法、硬體的需求越清楚、越理解深入。
我們可以看到,晶片巨頭Nvidia(英偉達)已經牢牢佔據AI晶片榜首,由於CUDA開發平臺的普及,英偉達的GPU是目前應用最廣的通用AI硬體計算平臺。除了有實力自研晶片的企業(全世界也沒幾家),如果需要做AI相關的工作,必定需要用到Nvidia的晶片。Nvidia的晶片應用普遍,現在所有的AI軟體庫都支援使用CUDA加速,包括谷歌的Tensorflow,Facebook的Caffe,亞馬遜的MXNet等。

除了一騎絕塵的英偉達,其他老牌的晶片巨頭都沒閒著,特別是Intel通過買、買、買奮力的將自己擠到了頭部玩家的位置。微軟在最新的Build大會上公佈了基於英特爾FPGA的AI方案,而英特爾的FPGA業務正是通過收購Altera獲得的。
除此之外,我們可以看到像Google這樣的網際網路廠商也亂入了前五。這當然要歸功於上面提到的TPU,雖然谷歌不直接售賣晶片,但是谷歌通過雲服務提供TPU的呼叫服務。谷歌很早就開源了Tensorflow軟體平臺,這使得Tensorflow成為最主流的機器學習軟體平臺,已經成了事實上行業的軟體平臺標準。而Tensorflow最佳的計算環境必定就是谷歌自己的雲服務了,通過軟體、硬體(或者說雲)環境的打通,谷歌妥妥的成為AI晶片領域的一方霸主。
現在業界爭論的焦點是AI晶片的處理器架構用哪種是最好的,有前面提及的有GPU、FPGA、DSP和ASIC,甚至還有更前沿的腦神經形態晶片。現在GPU可以認為是處於優勢地位,但其他幾種的處理器架構也各有優勢。Intel則是多方下注,不錯過任何一種處理器架構。谷歌在TPU(其實就是一種ASIC)方面的巨大投入帶來了硬體效能的極大提高,目前看來對GPU的衝擊將是最大的,原因不單單是因為專用架構帶來的效率優勢,還有商業模式方面帶來的成本優勢。在半導體行業內的普遍觀點是,一旦AI的演算法相對穩定,ASIC肯定是最主流的晶片形態。看看挖礦晶片的進化歷程,這個觀點非常有說服力。
在雲端,網際網路巨頭已經成為了事實上的生態主導者,因為雲端計算本來就是巨頭的戰場,現在所有開源AI框架也都是這些巨頭髮布的。在這樣一個生態已經固化的環境中,留給創業公司的空間實際已經消失。
本人曾經在一個希望運用FPGA實現AI演算法的公司待過一算時間。離開的原因肯定不止一個,但是這幾個的原因是根本:
1、他們想做的事情,類似華為這樣的公司,早一年已經做完,而且大公司招聘幾十個博士投入做演算法優化。
2、網際網路巨頭,手上有資料,最後演算法、晶片、硬體可能都自己幹。阿里從其他公司招聘了大量的AI人才。
3、FPGA只會是中間態,最終成本上會被ASIC打敗。
4、生態決定一切!GPU對於軟體的人來說,用起來太舒服了,FPGA用起來不順手。FPGA從業人口少。
終端市場群雄割據,機會尚存。
上面說到了Inference現在主要是在雲端完成的,這主要是因為現在終端上基本沒有合適的處理單元可以完成相應功能。所以我們發現很多AI功能都需要聯網才可以使用,這大大限制了AI的使用場景。所以將Inference放到終端來,讓一些功能可以本地完成,成了很多晶片廠商關注的領域。
華為的麒麟970便是最早將AI處理單元引入到終端產品的晶片,其中該晶片中的AI核心,是由AI晶片創業公司寒武紀提供的IP(智慧財產權)。該晶片的引入,可以幫助華為手機在終端完成一些特定的AI應用,比如高效的人臉檢測,相片的色彩美化等。此後,蘋果,三星都宣佈了在其處理器中引入相應的AI處理單元,提升手機終端的AI應用能力。
在終端上,由於目前還沒有一統天下的事實標準,晶片廠商可以說是八仙過海各顯神通。
給手機處理器開發AI協處理器是目前看來比較靠譜的方式,寒武紀Cambricon-1A整合進入麒麟970就是一個很好的例子。由於華為手機的巨大銷量,寒武紀迅速成為AI晶片獨角獸。而另外一家創業公司深鑑科技此前獲得了三星的投資,其AI晶片IP已經整合到三星最新的處理器Exynos 9810中。
然而能獲得手機大廠青睞的AI晶片廠商畢竟是少數,更多的AI晶片廠商還需要找到更多的應用場景來使自己的晶片發光發熱。
國芯釋出全新晶片GX8010——搭載NPU的物聯網人工智慧晶片,它將為各種物聯網產品賦能。國芯針對人工智慧與物聯網的特點,將演算法、軟體、硬體深度整合,採用了NPU、DSP等多項最新技術。

由於GX8010在市場和效能的卓越表現,硬十也希望與國芯能夠更多合作,也與國芯多次磋商合作事宜,希望能夠讓更多的硬體愛好者更多的深入瞭解這款終端AI晶片。
相對於語音市場,安防更是一個AI晶片扎堆的大產業,如果可以將自己的晶片置入攝像頭,是一個不錯的場景,也是很好的生意。包括雲天勵飛、海康威視、曠視科技等廠商都在大力開發安防領域的AI嵌入式晶片,而且已經完成了一定的商業化部署。
相對於雲端,終端留給AI晶片創業公司更廣闊的市場。但是於此同時,由於應用環境千差萬別,沒有相應的行業標準,各個廠商各自為戰,無法形成一個統一的規模化市場,對於投入巨大的晶片行業來說,有可能是好故事,但不一定是個好生意。