
人工智慧(AI)經歷了怎樣的發展歷程?
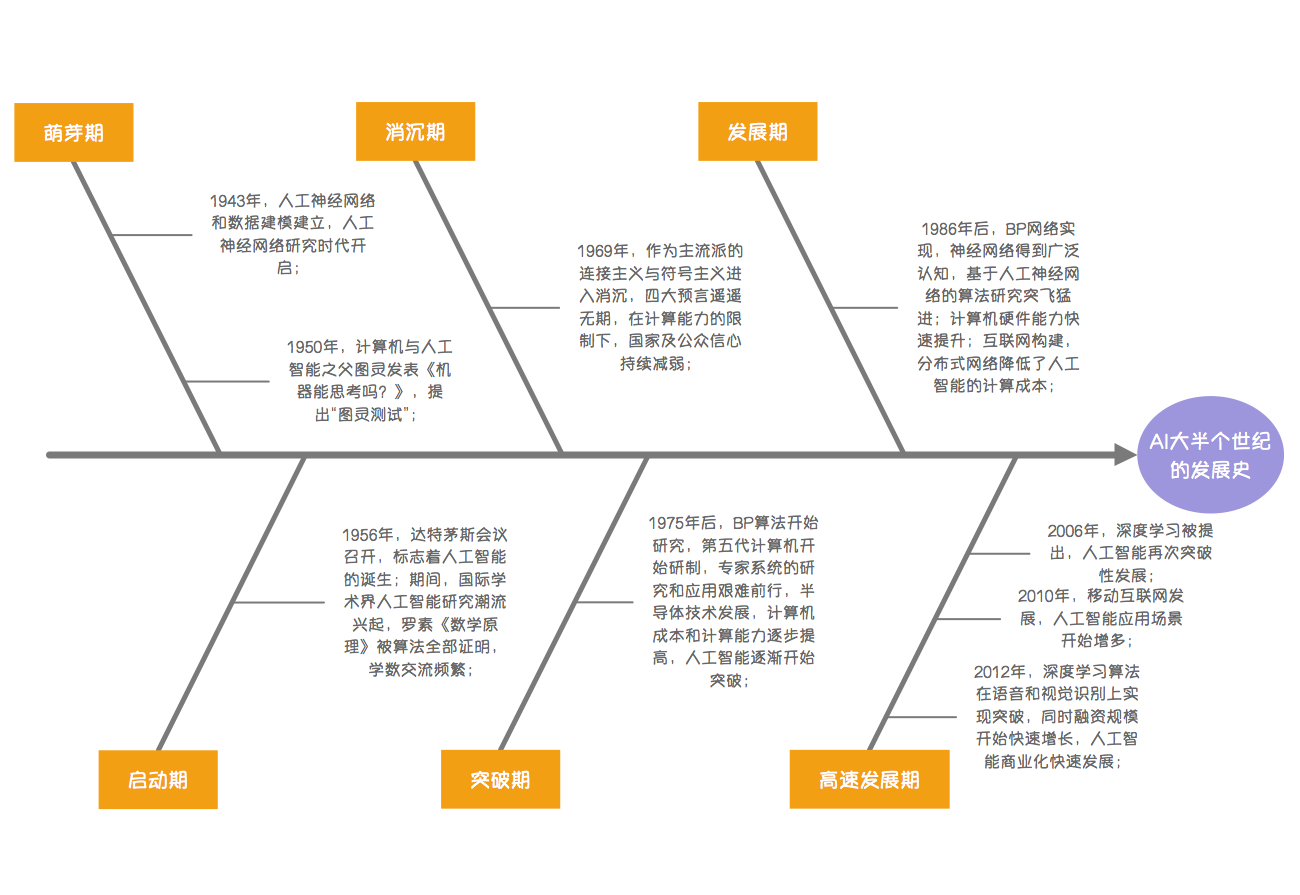
2015年3月,隨著Google Deepmind開發的AlphaGo程式打敗了韓國職業圍棋高手李世石(Lee Se-dol),媒體在通稿中開始普遍使用“AI”“機器學習”和“深度學習”這樣的字眼,“AI”也迅速成為人們茶餘飯後的熱門話題,AI技術相關的企業如雨後春筍般迅速崛起,至今依然是投資市場上十分風靡的版塊。然而,AI的歷史卻遠比AlphaGo悠久得多。通常,一項新技術的出現都會經歷“Gartner曲線”(技術成熟度曲線),經歷促動期、峰值期、泡沫期、穩步爬升期、實質生產期,然而AI的發展歷程卻頗具戲劇化,經歷了“三起兩落”。
早在1956年的達特茅斯會議(Dartmouth Conference)上,約翰·麥卡錫(John McCarthy)、馬文·閔斯基(Marvin Minsky,人工智慧與認知學專家)、克勞德·夏農(Claude Shannon,資訊理論的創始人)、艾倫·紐厄爾(Allen Newell,電腦科學家)、赫伯特·西蒙(Herbert Simon,諾貝爾經濟學獎得主)等科學家聚在一起,討論著一個完全不食人間煙火的主題:用機器來模仿人類學習以及其他方面的智慧,目的是讓逐漸成熟的計算機能夠代替人類解決一些感知、認知乃至決策的問題
人工智慧最初採用的方法是專家編制規則,教機器人認字、語音識別,但是人們沒能很好地總結提煉出人類視聽功能中的規律,因此在機器學習的轉化上效果並不好,結果事與願違,人工智慧也在殘酷的現實中走向下坡。
由於,人為指導這條路行不通,人們開始另闢蹊徑,把目光投向了基於大量資料的統計學方法。於是,人工智慧在人臉識別等一些較簡單的問題上取得了重大進展,在語音識別上也實現了基本可用。人工智慧初見成效,這是第二“起”。
然而,基於大資料的統計學方法很快遇到了瓶頸,因為單純依靠資料積累並不能無限地提高準確率。從“基本可用”到“實用”之間出現了一道難以逾越的鴻溝,十幾年都沒能跨過。人工智慧再次沒落。
直到2006年,加拿大多倫多大學的計算機系教授傑弗瑞·辛頓(Geoffrey Hinton)在《科學》上發表一篇關於深度學習的文章,人們又重新看到了人工智慧的希望。隨著GPU(圖形處理器)的廣泛使用,計算機的並行處理速度大幅加快、成本更低、功能更強大,實際儲存容量無限拓展,可以生成大規模的資料,包括圖片、文字和地圖資料資訊等,人工智慧迎來了新的生機,於是,AlphaGo的勝利順理成章。
然而,AlphaGo實際上只是人工智慧界的一個小學生,仍然屬於“弱人工智慧”(Narrow AI)。它可以像人類一樣完成某項具體任務,也有可能比人類做得更好。但它並不是真正擁有智慧,也不會有自主的意識。例如Pinterest利用人工智慧給圖片分類,Facebook利用人工智慧進行面部識別等。麥卡錫在達特茅斯會議上提出的AI,一般指的就是“弱人工智慧”。與“弱人工智慧”相對的,是“強人工智慧”(General AI),指的是機器擁有像人類一樣的感知能力,甚至還可以超越人類的感知,它可以像人類一樣思考,就像電影中的終結者。當機器智慧超越人腦智慧的那一刻,也就實現了機器智慧與人腦智慧的融合,美國未來學家雷蒙德·庫茲韋爾(Raymond Kurzweil)稱之為“奇點”(Singularity),時空中的物理規律將不再適用。不過,就目前為止,科學家普遍達成的共識是,我們僅僅實現了弱人工智慧的一小部分。
- 接下來的文章裡面會介紹些“機器學習”、“深度學習”、“有監督機器學習”和“無監督機器學習”相關的內容。