
MxNet學習:MxNet架構
1 MxNet架構
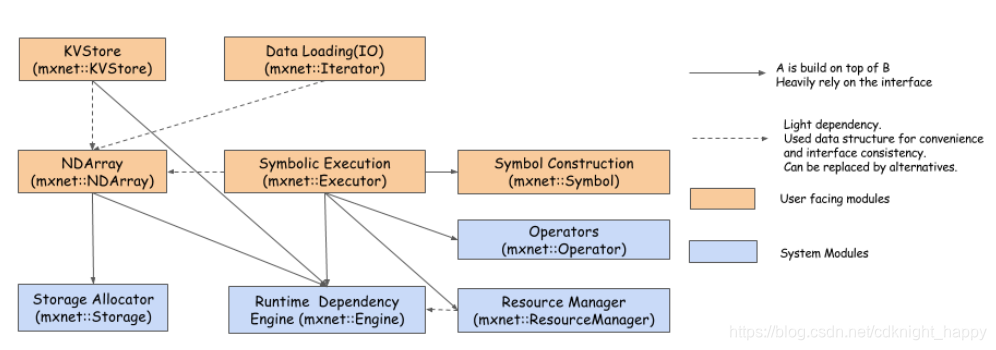
Runtime Dependency Engine:根據讀/寫依賴關係調度和執行操作
Storage Allocator:高效地分配和回收主機(CPU)和裝置(gpu)上的記憶體塊
Resource Manager:管理全域性資源,如隨機數生成器和臨時空間
NDArray:動態、非同步的n維陣列,為MXNet提供了靈活的命令式程式
Symbolic Execution:靜態符號圖形執行器,提供了高效的符號圖形執行和優化
Operator:定義靜態的正向和梯度計算(backprop)的操作符
SimpleOp:以統一方式擴充套件NDArray操作符和符號操作符的操作符
Symbol Construction:符號構造,它提供了一種構造計算圖(網路配置)的方法
KVStore:鍵值儲存介面,用於有效的引數同步
Data Loading(IO):高效的分散式資料載入和擴充
相關推薦
MxNet學習:MxNet架構
1 MxNet架構 Runtime Dependency Engine:根據讀/寫依賴關係調度和執行操作 Storage Allocator:高效地分配和回收主機(CPU)和裝置(gpu)上的記憶體塊 Resource Manager:管理全域性資源,如隨機數生成器和臨時空間 ND
MxNet學習:優化深度學習中的記憶體消耗
在過去的十年中,深度學習的一個持續的趨勢是向更深更大的網路發展。儘管硬體效能迅速提高,但先進的深度學習模型仍在不斷挑戰GPU RAM的極限。因此,即使在今天,人們仍然希望找到一種方法來訓練更大的模型,同時消耗更少的記憶體。這樣做可以讓我們更快地進行訓練,使用更大的批處理大小,從而實現更高
MxNet學習: 深度學習的依賴引擎
我們總是希望深度學習庫執行得更快,能夠擴充套件到更大的資料集。一種自然的方法是,看看我們是否可以從向這個問題投入更多硬體中獲益,就像同時使用多個gpu。 然後,庫設計人員會問:如何跨裝置平行計算?更重要的是,我們如何在引入多執行緒時同步計算?執行時依賴引擎是這些問題的通用解決方案。
MxNet學習:深度學習程式設計風格
1 前言 無論我們多麼關心程式效能,在開始擔心優化效果之前,我們首先需要能夠工作的程式碼。編寫清晰、直觀的深度學習程式碼非常具有挑戰性,任何實踐者必須處理的第一件事就是語言語法本身。在眾多的深度學習庫中,每種庫都有自己的程式設計風格。 在本文中,我們將重點討論兩個最重要的高階設計
分散式機器學習框架:MxNet
前言: caffe是很優秀的dl平臺。影響了後面很多相關框架。 cxxnet借鑑了很多caffe的思想。相比之下,cxxnet在實現上更加乾淨,例如依賴很少,通過mshadow的模板化使得gpu和cpu程式碼只用寫一份,分散式介面也很乾淨。 mxnet是cxxnet的
分散式機器學習框架:MxNet 前言
Minerva: 高效靈活的並行深度學習引擎 不同於cxxnet追求極致速度和易用性,Minerva則提供了一個高效靈活的平臺讓開發者快速實現一個高度定製化的深度神經網路。 Minerva在系統設計上使用分層的設計原則,將“算的快”這一對於系統底層的需求和“好用”這一對於
mxnet學習(五):gluon模組進行資料載入-Dataset和DataLoader
在gluon介面中,通過Dataset和DataLoader來對資料集進行迴圈遍歷,並返回batch大小的資料,其中Dataset物件用於資料的收集、載入和變換,而DataLoader物件用於返回batch大小的資料。 1. 相關模組 mxnet.gluon.
mysql學習與提高1:mysql架構總覽
一、MySQL整體邏輯架構 我們先下圖看看MySQL整體邏輯架構(MySQL’s Logical Architecture) 圖1&
【深度學習】MXNet自動求解函式梯度
文章目錄 概述 示例 with語句 求解梯度程式碼 概述 本節需要先了解MXNet中NDArray的基本用法,可以參考我的前一篇部落格:【深度學習】MXNet基本資料結構NDAr
【深度學習】MXNet基本資料結構NDArray常用操作
文章目錄 概述 示例 概述 在MXNet深度學習框架中,NDArray是儲存和變換資料的主要工具,和NumPy中的ndarray有異曲同工之妙。 在下面的示例中,主要展示了: NDarray的建立;
產品學習:基於Android的智慧汽車的架構設計和平臺技術
一.國內研究機構智慧駕駛技術現狀 20世紀90年代初期,由南京理工大學、國防科技大學、清華大學、浙江大學和北京理工大學等高校聯合研製成功了我國第一輛無人駕駛車輛ATB-1(Aut
Google leveldb學習筆記一:基本架構與安裝使用
簡介 LevelDB是一個Google編寫的快速鍵值儲存庫,它提供從字串鍵到字串值的有序對映。 基本架構 LSM樹儲存引擎 先說什麼是儲存引擎: 儲存引擎是儲存系統的發動機,直接決定了儲存系統能夠提供的效能和功能 儲存系統的基本功能包括:增刪讀改,讀取操作又
kubernetes學習:2.kubernetes叢集搭建(一)架構介紹
kubernetes叢集搭建:架構介紹 作為一個容器的編排管理工具,k8s的效能出眾而且社群力量強大,連docker官方也已經預設k8s為容器編排的首選工具。所以我們更有必要去學習和了解它。 k8s的整體架構主要分為兩個部分: master(控制節點)和
DMLC深度機器學習框架MXNet的編譯安裝
http://www.cnblogs.com/simplelovecs/p/5145305.html 這篇文章將介紹MXNet的編譯安裝。 MXNet的編譯安裝分為兩步: 首先,從C++原始碼編譯共享庫(libmxnet.so fo
MXnet實戰深度學習1--MXnet的安裝與第一個例子
Mxnet是一個輕量化分散式可移植深度學習計算平臺,他支援多機多節點、多GPU的計算,其openMP+MPI/SSH+Cuda/Cudnn的框架是的計算速度很快,且能與分散式檔案系統結合實現大資料
MXNet學習 (1) :載入預訓練模型
首先在MXNet的model zoo下載對應的模型描述檔案以及模型引數檔案: vgg16:對應vgg16.json vgg16-0000.params resnet50:對應resnet50.json resnet50-0000.params
深度學習框架MXNet(2)--autograd
這一節,我們將介紹MXNet框架中的自動求導模組autograd。在深度學習演算法中,經常需要計算的就是一個向量的梯度,但求梯度是一個手動編碼比較麻煩的事情,並且求向量的梯度並不
嵌入式深度學習之mxnet交叉編譯Arm Linux
參考文件 本文件涉及到的目標硬體為全志H8(8核Cortex-A7,Armv7架構),但是對其他Arm晶片也有一定的借鑑意義,只需要更換交叉編譯鏈即可。 開發環境介紹 主機作業系統:Ubuntu14.04 64位 目標平臺:CQA83t 全志H8
《軟體架構設計》學習筆記--8--6大步驟4:概念架構設計
我們所使用的工具深刻地影響著我們的思考習慣,從而也影響了我們的思考能力。——Edsger Dijkstra 本篇記錄6大步驟中的第四步:概念架構設計。包括如下內容: 概念架構是什麼? 概念架構怎麼樣? 概念架構設計實踐要領 1、概念架構是什
《大數據日知錄》讀書筆記-ch12機器學習:範型與架構
框架 梯度 目前 reduce 訓練 編程 base 屬於 parallel 機器學習算法特點:叠代運算 損失函數最小化訓練過程中,在巨大參數空間中叠代尋找最優解 比如:主題模型、回歸、矩陣分解、SVM、深度學習 分布式機器學習的挑戰: - 網絡通信效率 -