
MxNet學習:深度學習程式設計風格
1 前言
無論我們多麼關心程式效能,在開始擔心優化效果之前,我們首先需要能夠工作的程式碼。編寫清晰、直觀的深度學習程式碼非常具有挑戰性,任何實踐者必須處理的第一件事就是語言語法本身。在眾多的深度學習庫中,每種庫都有自己的程式設計風格。
在本文中,我們將重點討論兩個最重要的高階設計決策:
- 數學計算是採用符號正規化還是命令式正規化;
- 是構建更大(更抽象)的網路,還是構建更多原子操作的網路。
自始至終,我們將重點關注程式設計模型本身。當程式設計風格決定可能影響效能時,我們會指出這一點,但是我們不會詳細討論具體的實現細節。
2 符號式程式設計 VS. 指令式程式設計
如果您是Python或c++程式設計師,那麼您已經熟悉命令式程式。命令式程式在執行時執行計算。您用Python編寫的大多數程式碼都是必須的,下面的NumPy程式碼片段也是如此。
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
當程式執行c = b * a時,它進行了實際的數值計算。
符號程式有所不同。使用符號樣式的程式,我們首先抽象地定義一個(可能很複雜的)函式。在定義函式時,不需要進行實際的數值計算。我們根據佔位符定義抽象函式,然後我們可以編譯這個函式,並在給定的實際輸入時對其進行求值。在下面的例子中,我們將上面的命令式程式重寫為一個符號樣式的程式:
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
如您所見,在符號版本中,當C = B * A執行時,不會進行實際的計算。相反,該操作生成一個表示計算的計算圖(也稱為符號圖)。下圖是計算D的計算圖。
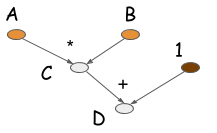
大多數符號風格的程式包含顯式或隱式的編譯步驟。編譯過程將計算圖轉換為我們稍後可以呼叫的函式。在上面的例子中,數值計算只發生在程式碼的最後一行。符號式程式設計的特徵是在構建計算圖和執行計算圖之間有明顯的分離。對於神經網路而言,我們通常將整個模型定義為單個計算圖。
在其他流行的深度學習庫中,Torch、Chainer和Minerva採用命令式風格。符號式深度學習庫的例子包括Theano、CGT和TensorFlow。我們還可以將依賴於配置檔案的庫,如CXXNet和Caffe,看作是符號風格的庫,在這些庫中,我們將配置檔案的內容視為定義計算圖。
現在您已經瞭解了這兩種程式設計模型之間的區別,接下來讓我們比較下兩種程式設計模型的優點。
2.1 命令式程式往往更靈活
當您使用來自Python的命令式庫時,您使用的是Python。幾乎所有用Python編寫的直觀的東西,都可以通過在適當的地方呼叫必要的深度學習庫來加速。另一方面,當您編寫符號程式時,您可能無法訪問所有熟悉的Python結構,比如迭代。考慮以下命令式程式,並考慮如何將其轉換為符號程式。
a = 2
b = a + 1
d = np.zeros(10)
for i in range(d):
d += np.zeros(10)
如果符號API不支援Python for迴圈,那麼這個改寫過程就不那麼容易了。當您用Python編寫符號程式時,您不是用Python編寫的。相反,您使用的是由符號API定義的領域特定語言(DSL)。在深度學習庫中發現的符號API是功能強大的DSL,可以為神經網路生成可呼叫的計算圖。
直覺上,您可能會說命令式程式比符號程式更直觀,可以更容易地使用語言本身的特性。例如,很容易在計算過程中打印出值,或者在計算流中的任何一點使用控制流和迴圈。
2.2 符號式程式往往更高效
正如我們所看到的,命令式程式往往是靈活的,非常適合於宿主語言的程式設計流程。所以你可能會想,為什麼那麼多的深度學習庫都採用符號式程式設計呢?主要原因是效率,包括記憶體佔用和處理速度。讓我們回顧一下前面的示例。
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
假設陣列中的每個單元格佔用8位元組記憶體。在Python控制檯中執行這個程式需要多少記憶體?
在指令式程式設計中,我們需要在每一行分配記憶體。這樣我們就分配了4個大小為10的陣列。所以我們需要4 * 10 * 8 = 320位元組。但是,如果我們構建一個計算圖,並且事先知道我們只需要d,我們就可以重用最初分配給中間值的記憶體。例如,通過就地執行計算,我們可以回收分配給b的空間用於儲存c,也可以回收分配給c的空間儲存d。最終,我們可以將記憶體需求減半,只需要2 * 10 * 8 = 160位元組。
符號式程式受到更多的限制。當我們在D上呼叫compile時,我們告訴系統只需要D的值。計算的中間值,也就是這裡的c,對我們來說是不可見的。
我們可以從中受益,因為符號程式可以安全地重用記憶體進行就地計算。但如果我們後來決定需要訪問c,那麼就非常不方便了。因此,命令式程式能夠更好地滿足所有可能的需求。如果我們在Python控制檯中執行程式碼的命令式版本,將來就可以檢查任何中間變數。
符號程式還可以執行另一種優化,稱為操作摺疊。如下圖所示,在上面的示例中,乘法和加法操作可以摺疊成一個操作。
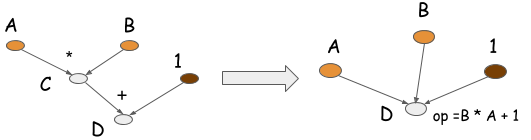 如果計算在GPU處理器上執行,操作摺疊之後將使用一個GPU核心,而不是兩個。實際上,這是我們在優化的庫(如CXXNet和Caffe)中手工操作的一種方法。操作摺疊提高了計算效率。
如果計算在GPU處理器上執行,操作摺疊之後將使用一個GPU核心,而不是兩個。實際上,這是我們在優化的庫(如CXXNet和Caffe)中手工操作的一種方法。操作摺疊提高了計算效率。
注意,您不能在命令式程式中執行操作摺疊,因為中間值可能在將來被引用。在符號式程式中,操作摺疊是可能的,因為您可以得到整個計算圖形,以及需要哪些值和不需要哪些值的明確說明。
2.3 案例分析:Backprop和AutoDiff
在這一節中,我們將比較關於自動微分或反向傳播問題的兩種程式設計模型。微分在深度學習中至關重要,因為它是我們訓練模型的機制。在任何深度學習模型中,我們都定義了一個損失函式。損失函式度量模型與期望輸出之間的距離。然後我們通常會反向傳播到訓練示例(輸入和實際輸出對)。在每個步驟中,我們更新模型的引數以最小化損失。為了確定更新引數的方向,我們需要將損失函式對引數求導。
在過去,每當有人定義一個新模型時,他們必須手工計算出導數。雖然數學計算相當簡單,但對於複雜的模型來說,這可能是一項費時而乏味的工作。所有現代的深度學習庫通過自動解決梯度計算問題,使從業者/研究人員的工作更容易。
命令式程式和符號式程式都可以執行梯度計算。我們來看看如何對每個函式進行自動微分。
讓我們從命令式程式開始。下面的示例Python程式碼使用我們的示例執行自動微分:
class array(object) :
"""Simple Array object that support autodiff."""
def __init__(self, value, name=None):
self.value = value
if name:
self.grad = lambda g : {name : g}
def __add__(self, other):
assert isinstance(other, int)
ret = array(self.value + other)
ret.grad = lambda g : self.grad(g)
return ret
def __mul__(self, other):
assert isinstance(other, array)
ret = array(self.value * other.value)
def grad(g):
x = self.grad(g * other.value)
x.update(other.grad(g * self.value))
return x
ret.grad = grad
return ret
# some examples
a = array(1, 'a')
b = array(2, 'b')
c = b * a
d = c + 1
print d.value
print d.grad(1)
# Results
# 3
# {'a': 2, 'b': 1}
在這段程式碼中,每個陣列物件都包含一個grad函式(它實際上是一個閉包)。當你執行d.grad,它遞迴呼叫其輸入的梯度函式,支援梯度值返回,並返回每個輸入的梯度值。
這看起來可能有點複雜,所以讓我們考慮符號程式的梯度計算。下面的程式對相同的任務執行符號梯度計算。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# get gradient node.
gA, gB = D.grad(wrt=[A, B])
# compiles the gradient function.
f = compile([gA, gB])
grad_a, grad_b = f(A=np.ones(10), B=np.ones(10)*2)
D的grad函式生成一個向後計算圖,返回梯度節點gA、gB,對應下圖中的紅色節點:

命令式程式實際上做了與符號式程式相同的事情。它隱式地在grad閉包中儲存一個向後計算圖。當您呼叫d.grad,你從d(D)開始,通過圖形回溯來計算梯度,並收集結果。
符號式程式設計和指令式程式設計中的梯度計算遵循相同的模式。那有什麼區別呢?回想一下,要準備好面對命令式程式中所有可能的需求。如果您正在建立一個支援自動微分的陣列庫,則必須在計算的同時保持grad閉包。這意味著沒有一個歷史變數可以被垃圾收集,因為它們是由變數d通過函式閉包引用的。
如果你只想計算d的值,而不想要梯度值呢?在符號式程式設計中,使用f=compile ([D])宣告。這也聲明瞭計算的邊界,告訴系統您只想計算前向過程。因此,系統可以釋放以前結果的記憶體,並在輸入和輸出之間共享記憶體。
想象執行一個有n層的深層神經網路。如果您只執行前向傳遞,而不執行後向(梯度)傳遞,那麼您只需要分配兩個時間空間副本來儲存中間層的值,而不是它們的n個副本。然而,由於指令式程式設計需要準備好滿足獲得梯度的所有可能需求,它們必須儲存中間值,這需要時間空間的n個副本。
正如您所看到的,優化級別取決於您所能做的限制。符號式程式設計要求您在編譯圖時清楚地指定這些限制。另一方面,指令式程式設計必須為更廣泛的需求做好準備。符號式程式設計有一個自然的優勢,因為它們更瞭解你想做什麼和不想要什麼。
我們可以通過一些方法修改命令式程式,以包含類似的限制。例如,一個解決方案是引入一個上下文變數,您可以引入一個無梯度上下文變數來關閉梯度計算。
with context.NoGradient():
a = array(1, 'a')
b = array(2, 'b')
c = b * a
d = c + 1
但是,這個示例仍然必須準備好滿足所有可能的需求,這意味著您不能執行就地計算來在前向過程中重用記憶體(這是一種通常用於減少GPU記憶體使用的技巧)。我們討論的技術生成顯式的向後傳遞。一些庫(如Caffe和CXXNet)在同一個圖上隱式地執行backprop。我們在本節中討論的方法也適用於它們。
大多數基於配置檔案的庫,如CXXNet和Caffe,都是為滿足一兩個通用需求而設計的:獲得每一層的啟用,或者獲得所有權重的梯度。這些庫有相同的問題:庫必須支援的泛型操作越多,基於相同資料結構的優化(記憶體共享)就越少。
正如您所看到的,在大多數情況下,限制和靈活性之間的權衡是相同的。
2.4 模型檢查點
能夠儲存模型並在稍後將其載入回來是非常重要的。有不同的方法來儲存您的工作。通常,要儲存一個神經網路,您需要儲存兩件事:神經網路結構的網路配置和神經網路的權重。
對於符號式程式,檢查配置的能力是一個優點。由於符號構造階段不執行計算,因此可以直接序列化計算圖,並在稍後將其載入回去。這解決了在不引入額外層的情況下儲存配置的問題。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
D.save('mygraph')
...
D2 = load('mygraph')
f = compile([D2])
# more operations
...
因為命令式程式在描述計算時執行,所以必須將程式碼本身儲存為配置,或者在命令式語言之上構建另一個配置層。
2.5 引數更新
大多數符號式程式是資料流(計算)圖。資料流圖描述計算。但是如何使用圖來描述引數更新並不明顯。這是因為引數更新引入了修改,這不是一個數據流概念。大多數符號式程式都引入一個特殊的update語句來更新程式中的持久狀態。
使用命令式風格編寫引數更新通常更容易,尤其是在需要多個相互關聯的更新時。對於符號式程式,update語句也在呼叫它時執行。因此,在這個意義上,大多數符號式深度學習庫依賴於命令式的方法來執行更新,而使用符號方法來執行梯度計算。
2.6 沒有嚴格的限制邊界
在比較這兩種程式設計風格時,我們的一些論點可能並不完全正確,例如,可以使命令式程式更像傳統的符號程式,也可以使符號程式更像傳統的命令式程式。然而,這兩個原型是有用的抽象,尤其是在理解深度學習庫之間的差異時。我們可以合理地得出結論,程式設計風格之間沒有明確的界限。例如,您可以在Python中建立just-in-time (JIT)編譯器來編譯命令式Python程式,這提供了符號程式中儲存的全域性資訊的一些優點。
3 小操作 VS. 大操作
在設計深度學習庫時,另一個重要的程式設計模型決策就是支援什麼操作。一般來說,大多數深度學習庫支援兩類操作:
- 大型操作——通常用於計算神經網路層(例如全連線和批歸一化)
- 小操作——數學函式,如矩陣乘法和逐元素相加
像CXXNet和Caffe這樣的庫支援層粒度的操作。像Theano和Minerva這樣的庫支援細粒度操作。
3.1 較小的操作可以更加靈活
使用較小的操作來組成較大的操作是很自然的。例如,sigmoid函式可以簡單地由除法、加法和指數法組成:
sigmoid(x) = 1.0 / (1.0 + exp(-x))
使用較小的操作作為構建塊,您幾乎可以表達您想要的任何內容。如果您更熟悉CXXNet或caffe樣式的層,請注意這些操作與層沒有區別,只是它們更小。
SigmoidLayer(x) = EWiseDivisionLayer(1.0, AddScalarLayer(ExpLayer(-x), 1.0))
這個表示式由三個層組成,每個層定義它的向前和向後(梯度)函式。使用較小的操作可以快速構建新層,因為您只需要組合元件。
3.2 大操作更加高效
直接組合sigmoid層需要三層操作,而不是一層。
SigmoidLayer(x) = EWiseDivisionLayer(1.0, AddScalarLayer(ExpLayer(-x), 1.0))
這段程式碼佔用了過多的計算和記憶體開銷(可以進行優化)。
像CXXNet和Caffe這樣的庫採取了不同的方法。為了支援粗粒度的操作,例如批歸一化和Sigmoid層,在每一層中,計算核心都是手工製作的,只需要啟動一個或幾個CUDA核心。這使得這些實現更加有效。
3.3 編譯和優化
小型操作可以優化嗎?當然可以。讓我們看看編譯引擎的系統優化部分。在計算圖上可以進行兩種優化:
- 記憶體分配優化,以重用記憶體的中間計算;
- 運算元融合,檢測子圖模式,如sigmoid,並將它們融合成一個更大的操作核心。
記憶體分配優化並不侷限於小操作圖。你也可以在更大的運算圖中使用它。但是,對於像CXXNet和Caffe這樣的大型操作庫,優化可能不是必需的,因為您無法在它們中找到編譯步驟。然而,這些庫中有一個(愚蠢的)編譯步驟,通過逐個執行每個操作,基本上將這些層轉換成一個固定的向前、向後執行計劃。
對於操作較小的計算圖,這些優化對效能至關重要。因為操作很小,所以可以匹配許多子圖模式。此外,由於最終生成的操作可能不可列舉,因此需要顯式地重新編譯核心,而不是在大型操作庫中使用固定數量的預編譯核心。這為支援小操作的符號庫建立了編譯開銷。需要編譯優化還會為只支援較小操作的庫帶來工程開銷。
與符號式與命令式的情況一樣,較大的操作庫通過要求您(對公共層)提供限制來“欺騙”,以便實際執行子圖匹配。這將編譯開銷轉移到真正的大腦,這通常不是很糟糕。
3.4 表示式模板和靜態型別語言
您總是需要編寫小操作並組合它們。像Caffe這樣的庫使用手工製作的核心來構建這些更大的塊。否則,您將不得不使用Python組合較小的操作。
還有第三種選擇,效果很好。這稱為表示式模板。基本上,您可以使用模板程式設計在編譯時從表示式樹生成通用核心。可以參考表示式模板。CXXNet廣泛使用了表示式模板,它支援建立更短、更可讀的程式碼,以匹配手工製作的核心的效能。
使用表示式模板和Python核心生成之間的區別在於,表示式計算是在編譯時對已有型別的c++進行的,因此不存在額外的執行時開銷。原則上,這對於其他支援模板的靜態型別語言也是可能的,但是我們已經看到這個技巧只在c++中使用。
表示式模板庫在Python操作和手工製作的大核心之間建立了一箇中間平臺,它允許c++使用者通過組合較小的操作來建立高效的大操作。這是一個值得考慮的選擇。
4 多種方法結合
現在我們已經比較了程式設計模型,您應該選擇哪一個?在深入研究之前,我們應該強調,根據您試圖解決的問題,我們的比較不一定會產生很大影響。
請記住Amdahl定律:如果您正在優化問題的非效能關鍵部分,那麼您將不會獲得很大的效能收益。
正如您所看到的,通常需要在效率、靈活性和工程複雜性之間進行權衡。更適合的程式設計風格取決於您要解決的問題。例如,命令式程式更適合於引數更新,符號程式更適合於梯度計算。
我們主張把這兩種方法結合起來。有時我們想要靈活的部分對效能並不重要。在這些情況下,可以保留一些效率來支援更靈活的介面。在機器學習中,組合方法通常比只使用一種方法效果更好。
如果您能夠正確地組合這些程式設計模型,那麼您可以獲得比使用單個程式設計模型更好的結果。在本節中,我們將討論如何做到這一點。
4.1 符號式程式設計和指令式程式設計
有兩種方法可以混合使用符號程式和命令程式:
- 在符號程式中使用命令式程式作為回撥
- 使用符號程式作為命令式程式的一部分
我們已經注意到,命令式地編寫引數更新和在符號程式中執行梯度計算通常是有幫助的。
符號庫已經混合了各種程式,因為Python本身是命令式的。例如,下面的程式將符號方法與命令式的NumPy混合。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
d = d + 1.0
符號圖被編譯成一個可以強制執行的函式。內部構件對於使用者來說是一個黑盒子。這就像編寫c++程式並將它們暴露給Python一樣,這是我們經常做的。
因為引數記憶體駐留在GPU上,所以您可能不希望使用NumPy作為命令式元件。支援與gpu相容的命令式庫可能是更好的選擇,該命令式庫與符號編譯函式互動,或者在符號程式執行的update語句中提供有限數量的更新語法。
4.2 小操作和大操作
小操作和大操作合併可能是有原因的。考慮執行諸如更改損失函式或向現有結構新增幾個定製層等任務的應用程式。通常,您可以使用大型操作來組合現有元件,並使用小型操作來構建新部件。
記得Amdahl法則。通常,新元件不是計算瓶頸的原因。因為效能關鍵部分已經由較大的操作優化過了,所以可以放棄對其他小操作的優化,或者進行有限的記憶體優化,而不是操作融合並直接執行它們。
4.3 選擇自己的實現方法
在本文中,我們比較了開發用於深度學習的程式設計環境的多種方法。我們比較了每種方法的可用性和效率含義,發現其中許多權衡(例如命令式與符號式之間的權衡不一定是非黑即白)。您可以選擇您的方法,或者將這些方法組合起來建立更有趣和更智慧的深度學習庫。
參考
文章翻譯自:https://mxnet.incubator.apache.org/architecture/program_model.html#compilation-and-optimization