
《基於深度學習的推薦系統研究綜述》_黃立威——閱讀筆記
一、常用的深度學習模型和方法介紹
1.自編碼器
自編碼器通過一個編碼和一個解碼過程來重構輸入資料,學習資料的隱表示。基本的自編碼器可視為一個三層的神經網路結構.下圖是自編碼器結構示意圖:
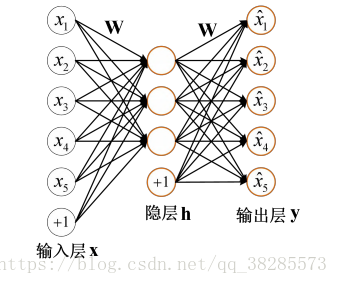
自編碼器的目的是使得輸入 x 與輸出 y 儘可能接近,這種接近程度通過重構誤差表示,根據資料的不同形式,通常重構誤差有均方誤差和交叉熵兩種定義方式。
如果僅僅通過最小化輸入輸出之間的誤差來實現對模型的訓練,自編碼器很容易學習到一個恆等函式。為了解決這個問題,研究者提出了一系列自編碼器的變種,其中比較經典的包括稀疏自編碼器和降噪自編碼器。2007 年,Bengio 等人通過堆疊多個降噪自編碼器,提出了棧式降噪自動編碼器(StackedDenoising Autoencoder, SDAE)的概念,其是一種深度神經網路結構,通過逐層非監督學習的預訓練可以學習多層次的資料抽象表示。
應用場景主要包括評分預測、文字推薦、影象推薦等。
2.受限玻爾茲曼機
玻爾茲曼機(Boltzmann machine, BM)是一種生成式隨機神經網路,由Hinton和Sejnowski在1986年提出。。BM能夠學習資料中複雜的規則,具有強大的無監督學習能力。但是,玻爾茲曼機的訓練過程非常耗時。為此,Sejnowski等 人 進 一 步 提 出 了 一 種 受 限 玻 玻 爾 茲 曼 機(Restricted Boltzmann Machine, RBM)其在玻爾茲曼機的基礎上,通過去除同層變數之間的所有連線極大地提高了學習效率。
儘管無法有效計算RBM所表示的分佈,但是通過Gibbs取樣能夠得到RBM所表示的分佈的隨機樣本。Gibbs取樣的問題是需要使用較大的取樣步數,使得RBM的訓練效率仍不高。考慮到這種情況,Hinton提出了一種對比散度(contrastivedivergence, CD)快速學習演算法,CD演算法同樣利用Gibbs取樣過程(即每次迭代包括從可見層更新隱層,以及從隱層更新可見層)來獲得隨機樣本,但是隻需迭代 k (通常 k =1)次就可獲得對模型的估計,而不需要像Gibbs取樣一樣直到可見層和隱層達到平穩分佈。
應用場景主要是使用者評分預測。
3.深度信念網路
Hinton等人在 2006 年提出了一種深度信念網路(Deep Belief Network, DBN),其是一種由多層非線性變數連線組成的生成式模型。在深度信念網路中,靠近可見層的部分是多個貝葉斯信念網路,最遠離可見層的部分則是一個 RBM,其結構如下圖所示:
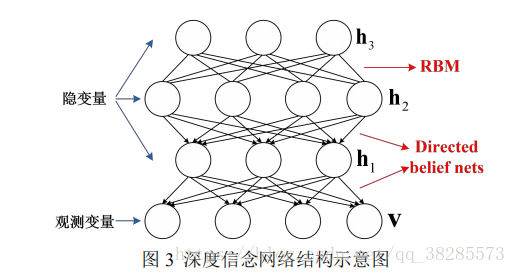
DBN 的結構可以看作由多個受限玻爾茲曼機層疊構成,網路中前一個 RBM 的隱層視為下一個 RBM 的可見層。
DBN 網路的訓練可採用一種貪婪逐層演算法。
深度信念網路當前在推薦系統中應用較少。由於DBN在建模一維資料上比較有效,因此被應用於提取音樂的特徵表示,從而進行音樂推薦。當前的應用場景僅限於音樂推薦
4.卷積神經網路
卷積神經網路是一種多層感知機,主要被用來處理二維影象資料。卷積神經網路在推薦系統中應用較為廣泛,主要被用於從影象、文字、音訊等內容中提取專案的隱藏特徵,從而獲取專案的低維向量表示,並結合使用者隱表示為使用者產生推薦。當前的應用場景主要包括影象推薦、音樂推薦、文字推薦等
5.迴圈神經網路
1986年 Rumelhart 等人[34]提出迴圈神經網路(Recurrent Neural Network, RNN)的概念。RNN 的最大特點在於神經網路各隱層之間的節點是具有連線的,它能夠通過獲取輸入層的輸出和前一時刻的隱層狀態來計算當前時刻隱層的輸出,也就是說 RNN 能夠對過去的資訊進行記憶。將 RNN 展開之後發現,它是一類所有層共享相同權值的深度前饋神經網路。但是,普通的 RNN結構存在梯度消失問題,很難學習資料之間的長程依賴關係。針對這個問題,研究者相繼提出了一些RNN 的變種,其中最著名的包括 Hochreiter 等人提出的長短時記憶網路(Long Short-Term Memory, LSTM)和 Cho 等人[67]提出的門限迴圈單元(GatedRecurrent Unit, GRU)。
隨著深度學習的不斷髮展,通過增加更加廣泛的記憶模組,研究者提出了記憶網路(Memory Network)、棧式增強迴圈網路(Stack-augmented Recurrent Net)、神經圖靈機(Neural Turing Machines, NTM)和可微分神經計算機(Differentiable Neural Computer,DNC)模型來建模資料之間長程依賴關係。尤其是 NTM 等工作,通過將 RNN 與注意力機制進行結合,極大地發展了迴圈神經網路的研究與應用。
迴圈神經網路在推薦系統中的應用主要是用來建模資料之間的序列影響,從而幫助獲取更有效的使用者和專案隱表示。。主要包括兩個方面:首先是被應用於建模推薦系統中使用者行為的序列模式,其次是在獲取使用者和專案隱表示的過程中,迴圈神經網路被應用於建模使用者和專案相關的文字資訊中詞語之間序列影響。當前的應用場景主要包括評分預測、影象推薦、文字推薦、基於位置社交網路中的興趣點推薦等。
二、基於深度學習的推薦系統
1.基於深度學的推薦系統通常將各類使用者和專案相關的資料作為輸入,利用深度學習模型學習到使用者和專案的隱表示,並利用這種隱表示為使用者產生專案推薦。下圖是基於深度學習的推薦系統框架:
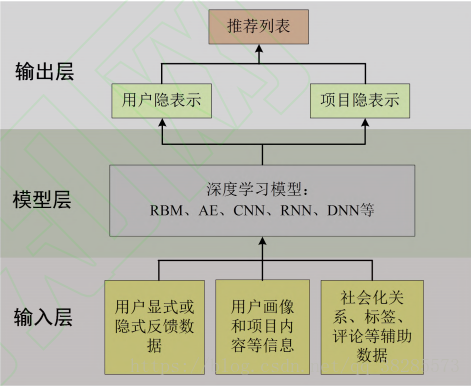
2.深度學習在推薦系統中的運用主要分為五個方向
1)深度學習在基於內容的推薦系統中的運用
2)深度學習在協同過濾中的運用
3)深度學習在混合推薦中的運用
4)深度學習在基於社交網路的推薦系統中的運用
5)深度學習在情感感知的推薦系統中的運用
目的都是利用深度學習得到使用者的隱表示和專案的隱表示再處理產生推薦列表
3.深度學習在基於內容的推薦系統中的運用
深度學習在基於內容的推薦中主要被用於從專案的內容資訊中提取專案的隱表示,以及從使用者的畫像資訊以及歷史行為資料中獲取使用者的隱表示,然後基於隱表示通過計算用使用者和專案的匹配度來產生推薦。在假設使用者和專案攜帶輔助資訊的情況下,深度神經網路模型被作為有效的特徵提取工具。
1)基於多層感知機的方法
深度結構化語義模型:
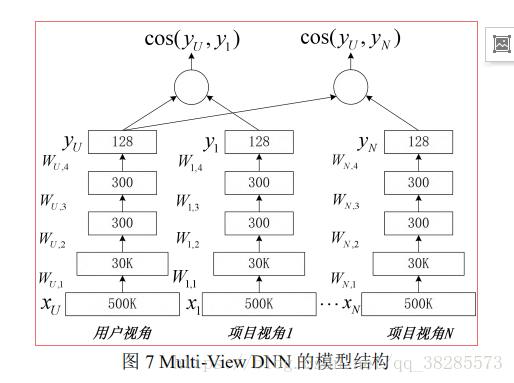
Elkahky等人考慮到傳統的基於內容的推薦系統中,使用者特徵難以獲取的問題,通過分析使用者的瀏覽記錄和搜尋記錄提取使用者的特徵,豐富使用者的特徵表示。作者將深度結構化語義模型(DSSM,Deep Structured SemanticModels)進行擴充套件,提出了一種多視角深度神經網 絡 模 型 ( Multi-View Deep Neural Network, Multi-View DNN),該模型通過使用者和專案兩種資訊實體的語義匹配來實現使用者的專案推薦,是一種實用性非常強的基於內容的推薦方法。
Zheng等人通過採用與DSSM相似的結構,考慮將評論資訊融入到推薦系統中以緩解推薦系統的資料稀疏問題,並提高推薦系統的質量,提出了一種深度協作作神經網路模型(Deep CooperativeNeural Network, DeepCoNN)。其主要思路是利用兩個並行的神經網路模型學習使用者和專案的隱特徵,一個網路通過使用者的所有評論資料建模了使用者的偏好,另一個網路通過專案的所有評論資訊建模專案的特徵,然後在兩個神經網路上面構建一個互動層來預測使用者對專案的評分。該方法通過利用使用者評論的文字內容資訊,有效提升了推薦的質量。Xu等人基於DSSM模型研究標籤感知的個性化推薦問題,分別利用使用者的所有標籤和專案的所有標籤定義使用者和專案的輸入特徵,從而學習使用者和專案的隱表示,通過計算使用者隱表示和專案隱表示的相似度來產生推薦。Chen等人研究了位置感知的個性化新聞推薦問題。通過DSSM中增加一個位置通道,利用MLP從使用者資訊、專案資訊和位置區域性主題分佈中學習使用者、項專案和位置的隱表示,最後聯合三個方面的資訊計算特定位置下使用者興趣與新聞內容之間的關聯度來產生新聞推薦。
2)基於卷積神經網路

3)基於RNN和DBN

4.深度學習載協同過濾中的運用
1)基於RBM的協同過濾(玻爾茲曼機)
2007年Salakhutdinov等人[46]首次將深度學習應用於解決推薦問題,提出一種基於受限玻爾茲曼機的協同過濾推薦模型。
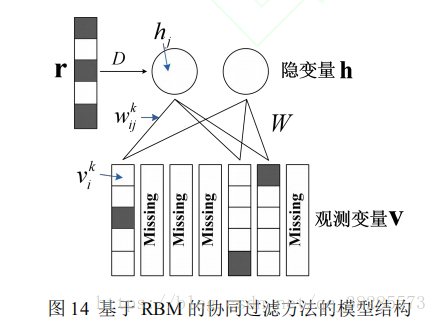
Phung等人[47]通過將Salakhutdinov等人的工作進行擴充套件,用於建模使用者評分的序數特徵,採用一種統一的方式同時抓住了相似性和共現性。此外,考慮到RBM模型僅僅利用了專案之間的關聯,Georgiev等人[48]通過增加使用者之間的關聯,對RBM模型進行了擴充套件,並且對模型的訓練和預測過程進行了簡化,同時還使得模型能夠直接處理實值評分資料。何潔月等人[49]將RBM模型進行擴充套件,提出一種基於實值狀態的玻爾茲曼機,該模型從三個方面對RBM進行改進,一是能夠直接將評分資料作為可見單元的狀態,不再需要轉化為 K 維的0-1向量表示,二是在訓練資料中增加使用了未評分資訊,三是將好友信任關係融入到該模型之中,能夠有效緩解模型的稀疏性。
2)基於自編碼器的協同過濾方法

Sedhain等人[37]提 出 了 一 種 基 於 自 編 碼 器 的 協 同 過 濾 方 法(AutoRec),該模型的輸入為評分矩陣R中的一行(User-based)或者一列(Item-based),利用一個編碼過程和一個解碼過程產生輸出,通過最小化重構誤差進行模型引數優化。Strub等人[95]採用兩個棧式降噪自編碼器(SDAE),將使用者和專案的評分向量分別作為輸入,分別學習使用者和專案的隱表示,然後通過隱表示對缺失評分進行預測。
協同降噪自編碼模型
Wu等人[20]利用降噪自編碼器來解決top-N推薦問題,提出了一種協同降噪 自 編 碼 器 模 型 ( Collaborative Denoising Auto-Encoders, CDAE)。CDAE與AutoRec方法的結構類似,通過將使用者的評分向量作為輸入,學習使用者的低維向量表示來進行推薦。但是與AutoRec相比存在一些差異:一是該方法不是評分預測,而是top-N推薦;二是該方法通過在評分向量中加入了噪聲資料,提升了模型的魯棒性;三是考慮不同使用者的個性化因素,為每個使用者引入了一個使用者因子提升了推薦的準確性。
3)基於分散式表示技術的系統過濾方法

4)基於RNN的協同過濾演算法
基於迴圈神經網路的協同過濾的主要思路是利用迴圈神經網路建模使用者歷史序列行為對當前時刻使用者行為的影響,從而實現使用者的專案推薦和行為預測。
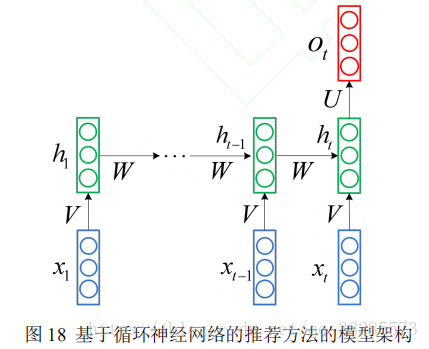
根據應用場景不同,基於迴圈神經網路的協同過濾模型主要被用於基於會話的推薦、融入時間序列資訊的協同過濾等應用中.
Song 等人[12]通過融入時間資訊並在多種粒度上建模使用者的興趣偏好,提出一種多等級時間深度語義結構化模型(Mutli-Rate TDSSM)。Liu 等人[73]考慮到推薦系統中的使用者行為往往存在多種型別,採用迴圈神經網路模型和 Log 雙線性模型(Log-BiLinear, LBL)[99]分別建模使用者行為之間的長程依賴關係和短時情境資訊,從而提出了一種迴圈 Log 雙線性模型(Recurrent Log-BiLinear, RLBL)實現使用者在下一時刻的行為型別預測。
Dai 等人[78]考慮到使用者偏好和專案特徵會因為使用者互動而隨時間演化,基於迴圈神經網路和多維時間點過程模型,提出了一種循
環 共 演 化 特 徵 嵌 入 過 程 模 型 ( RecurrentCoevolutionary Feature Embedding Processes)實現使用者偏好和專案特徵的演化跟蹤,並學習使用者和專案在每一時刻的隱表示,最後通過對使用者和專案的隱表示進行內積來產生專案推薦。
5)基於生成對抗網路的協同過濾方法