hdfs的四大機制和兩大核心
HDFS的四大機制:
1.心跳機制
在hdfs的整個執行過程中,需要datanode定時向namenode傳送心跳報告,namenode可以通過心跳報告確定datanode是可以正常工作的
傳送心跳報告的作用:
1)報告自己的存活情況
2)報告自己的塊的資訊
心跳報告週期 : 3s 不能太長,也不能太短
可以通過hdfs-deault.xml來進行設定
<property> <name>dfs.heartbeat.interval</name> <value>3</value> <description>Determines datanode heartbeat interval in seconds.</description> </property>
問題:
每隔3s datanode會向namenode傳送一個心跳報告,namenode如何判斷一個datanode宕機了?
首先,在連續10次心跳報告接受不到 (就是連續30秒接受不到datanode的心跳) 認為datanode可能宕機了(不能判定宕機)
namenode會主動的向datanode傳送檢查:
30000ms=300s=5min
<property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> <description> This time decides the interval to check for expired datanodes. With this value and dfs.heartbeat.interval, the interval of deciding the datanode is stale or not is also calculated. The unit of this configuration is millisecond. </description> </property>
預設情況下 檢查2次 10min 斷定datanode宕機了
判斷datanode宕機的時間為:
103s+25min=630s
2.安全模式
叢集啟動順序:
namenode----->datanode----->secondarynamenode
叢集啟動的過程中namenode做的事情:
1)將硬碟中的元資料載入到記憶體中
2)接受datanode的心跳報告 1)判斷datanode的存活率 2)載入塊的儲存節點資訊
這個過程中namenode處於安全模式的 叢集也是處於安全模式的—叢集的一個自我保護的模式
叢集處於安全模式的時候不對外提供服務的 不對外提供寫服務 對外提供讀的服務
叢集啟動過程中自動離開安全模式的依據:
1)datanode節點的啟動的個數:預設0
<property>
<name>dfs.namenode.safemode.min.datanodes</name>
<value>0</value>
<description>
Specifies the number of datanodes that must be considered alive
before the name node exits safemode.
Values less than or equal to 0 mean not to take the number of live
datanodes into account when deciding whether to remain in safe mode
during startup.
Values greater than the number of datanodes in the cluster
will make safe mode permanent.
</description>
</property>
預設情況下 叢集中的datanode節點啟動0個也可以離開安全模式
2)資料塊(排除副本)的彙報情況
叢集處於安全模式的時候 每一個數據塊的副本最小保證個數 預設1個
<property>
<name>dfs.namenode.replication.min</name>
<value>1</value>
<description>Minimal block replication.
</description>
</property>
所有資料塊的存活率(不考慮副本的)
假設叢集中 10000個數據塊 至少0.999*10000=9990個數據塊正常的才能離開安全模式
如果資料塊少於這個數 這個時候叢集一直處於安全模式
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0.999f</value>
<description>
Specifies the percentage of blocks that should satisfy
the minimal replication requirement defined by dfs.namenode.replication.min.
Values less than or equal to 0 mean not to wait for any particular
percentage of blocks before exiting safemode.
Values greater than 1 will make safe mode permanent.
</description>
</property>
手動進入和離開安全模式的命令:
hdfs dfsadmin -safemode enter/leave/get/wait
enter 進入安全模式
leave 離開安全模式
get 獲取安全模式的狀態
wait 等待離開安全模式
叢集處於安全模式 哪些事情可以做?哪些事情不可以做?
1)讀操作 不可修改元資料的操作
hadoop fs -ls / 可以
hadoop fs -cat / 可以
hadoop fs -tail / 可以
hadoop fs -get / /
不修改元資料的操作都可以進行
2)寫的操作 修改元資料資訊
hadoop fs -mkdir /
hadoop fs -put / /
hadoop fs -rm -r -f /
需要修改元資料的操作 都不可以進行的
3、機架策略
預設2個機架的時候 3個副本的情況下
機架:存放伺服器的
1)第一個副本存放在客戶端所在節點(客戶端是叢集中的某一個節點)
如果客戶端不是叢集中的某一個節點 任意儲存
2)第二個副本儲存在與第一個副本不同機架的任意節點上
3)第三個副本儲存在與第二個副本相同機架的不同節點上
4、負載均衡
hdfs來說 負載均衡指的是每一個datanode節點上儲存的資料和他的硬體匹配 實際上說的是佔有率相當的
叢集如果沒有處於負載均衡的時候 叢集會自動進行負載均衡的
進行負載均衡的過程 說白了就是資料塊的移動的過程 肯定跨節點 跨機架 需要網路傳輸
下面的引數 叢集自動進行負載均衡的頻寬 很慢 預設1M/s
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>1048576</value>
<description>
Specifies the maximum amount of bandwidth that each datanode
can utilize for the balancing purpose in term of
the number of bytes per second.
</description>
</property>
叢集規模的比較小的情況下 20個節點以下 自動進行負載均衡就可以了
叢集的規模比較大的時候:1000個節點
自動進行負載均衡 太慢了
這個手動進行負載均衡
1)修改負載均衡的頻寬 加大
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>104857600000</value>
<description>
Specifies the maximum amount of bandwidth that each datanode
can utilize for the balancing purpose in term of
the number of bytes per second.
</description>
</property>
2)告訴叢集及時進行負載均衡
start-balancer.sh -t 10%
不存在絕對的負載均衡
-t 10% 最大的節點的佔有百分比 和最小節點佔有的百分比差值 不能超過10% 指定的是負載均衡的評價標準
這個命令 提交的時候不會立即執行 類似於java中的垃圾回收
叢集空閒的時候進行負載均衡 提升叢集負載均衡的效率的
2、HDFS的兩大核心
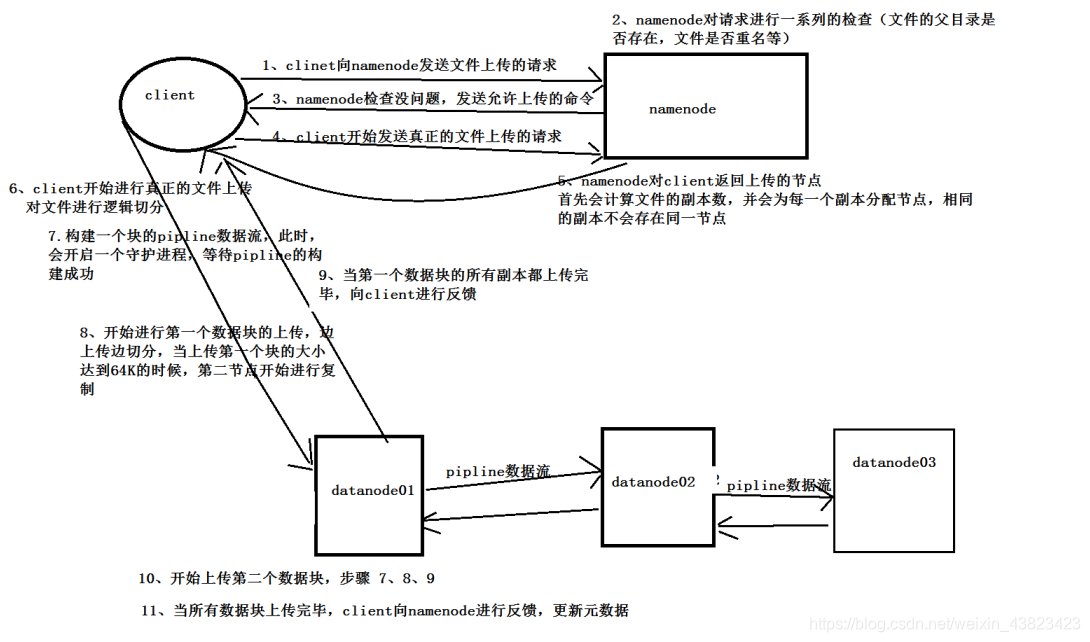
1、檔案上傳 就是寫資料的過程
1)流程
-
客戶端向namenode傳送檔案上傳的請求
-
namenode進行一系列的檢查 許可權 父目錄 檔案是否已經存在
-
namenode檢查通過 會向客戶端響應
-
客戶端會向namenode傳送檔案上傳的真正的請求 這個請求中包含、檔案的長度、檔案的大小
-
namenode會根據客戶端傳送的請求中的檔案的長度 計算資料塊的個數,並獲取叢集中的副本的配置資訊
給客戶端返回當前資料每一個數據塊需要存放的節點 hadoop.wmv 204m blk01:[hadoop01,hadoop03,hadoop04]
blk02:[hadoop01,hadoop02,hadoop04] -
客戶端開始準備檔案上傳
-
客戶端進行邏輯切塊 僅僅是一個偏移量的範圍劃分
-
客戶端開始準備上傳第一個資料塊 開啟一個後臺的阻塞程序 這個程序作用:等待資料塊上傳完成一個報告
-
構建第一個資料塊的pipline
-
開始進行資料塊上傳
-
第一個資料塊上傳成功 關閉當前的pipline
-
開始上傳第二個資料塊 重複9,10,11
-
所有的資料塊上傳成功 客戶端給namenode反饋namenode開始修改元資料資訊
2)流程圖解
3)檔案上傳的問題:
1.構建pipline的過程中 blk01:client----datanode01----datanode03—datanode04
pipline中的某一個節點宕機了 假設datanode03宕機了
datanode01會立即重試一次 還失敗 將這個節點剔除pipline 重新構建pipline
blk01:client-----datanode01-----datanode04
至少保證整個pipline中有一個存活的節點就可以
2.進行整個檔案的上傳的過程中 只需要保證至少一個副本上傳成功就認為整個資料塊上傳成功
其他副本叢集中自行非同步複製
3.進行檔案上傳的過程中 優先第一個副本的節點 是客戶端所在的節點
原因:保證副本最大程度的可以成功上傳一個
相當於本地的複製的工作 不需要網路傳輸
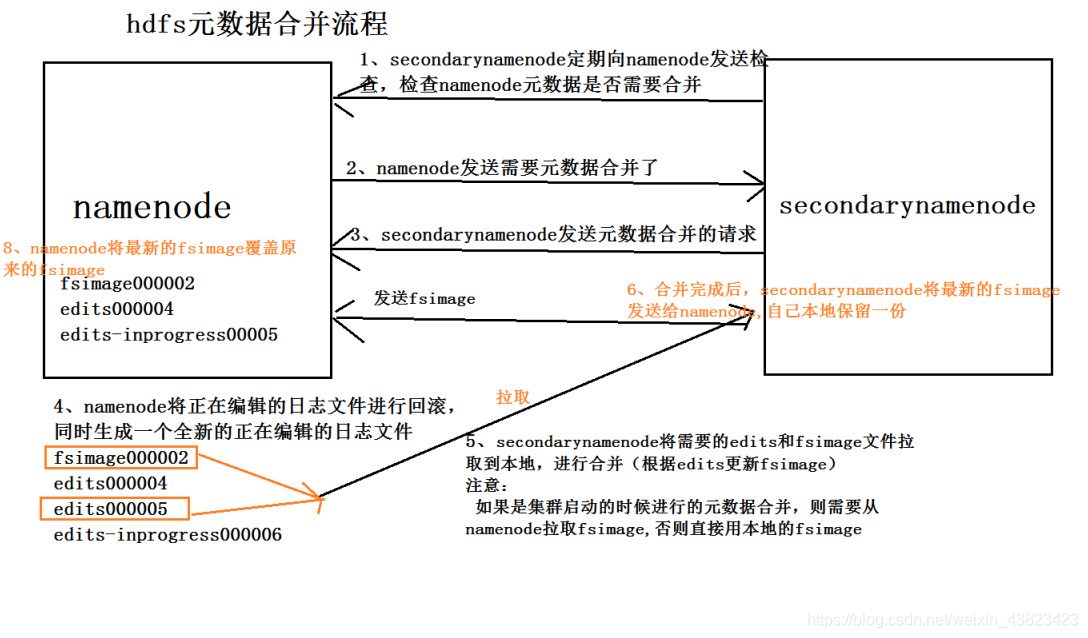
2、元資料合併
元資料的目錄結構:
1)edits * 歷史日誌檔案 一個小時滾動一次
2)edits_inprogress 正在編輯的日誌檔案
3)fsimage 元資料的映象檔案
4)seen_txid 合併點
fsimage_0000000000000000043 9:04
fsimage_0000000000000000078 10:04 最新合併的元資料檔案
fsimage_0000000000000000078====fsimage_0000000000000000043+edits檔案合併
合併完成之後 fsimage檔案的命名:fsimage_0000000000000000078 以最後一個edits檔案的id進行命名的
命名完成之後 存在namenode的元資料中 為了避免元資料丟失
原來的映象檔案fsimage_0000000000000000043不會立即刪除 下一個映象檔案合併完成的時候
前前一個映象檔案才會被刪除。
元資料合併的過程:
1)snn會向namenode傳送元資料是否合併的檢查 1min檢查一次
2)namenode需要元資料合併 會向snn進行響應
3)snn向namenode傳送元資料合併的 請求
4)namenode將正在編輯的元資料的日誌檔案進行回滾 變成一個歷史日誌檔案,同時會生成一個新的正在編輯的日誌檔案
5)snn將fsimage檔案和edits檔案拉取到snn的本地
6)snn將上面的檔案載入到記憶體中進行合併 根據edits的操作日誌修改fsimage檔案
7)合併完成,將合併完成的檔案傳送給namenode,重新命名,生成最新的fsiamge檔案 本地也會儲存一個
流程圖: