
Caffe中upgrade_proto.cpp:88] Check failed和upgrade_proto.cpp:1101] Check failed的問題
用指令碼檔案Caffe訓練自己的圖片分類時,遇到了個問題:
upgrade_proto.cpp:88] Check failed: ReadProtoFromTextFile(param_file, param) Failed to parse NetParameter file

查了一下,有答案說是因為生成的資料格式和訓練格式不一致,核對下生成資料庫檔案時設定的--backend資料格式是否和神經網路train_val.prototxt檔案中的backend屬性配置的一致,但我確定了自己的格式前後一致的。看了很久程式碼,突然發現我train_val.prototxt檔案中,竟然用了“//”作為程式碼註釋的標誌,指令碼檔案用的應該是“#”才對。。。
修改之後,又出現另一個問題:
upgrade_proto.cpp:1101] Check failed: ReadProtoFromTextFile(param_file, param) Failed to parse SolverParameter file
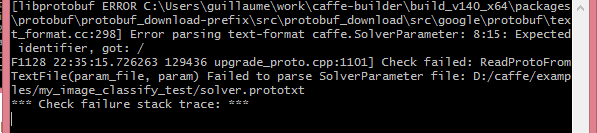
心虛的我查看了一下程式碼。。。果然又是這個問題。。改完就可以順暢的執行網路了。
相關推薦
Caffe中upgrade_proto.cpp:88] Check failed和upgrade_proto.cpp:1101] Check failed的問題
用指令碼檔案Caffe訓練自己的圖片分類時,遇到了個問題: upgrade_proto.cpp:88] Check failed: ReadProtoFromTextFile(param_file, param) Failed to parse NetParameter file 查了
caffe中的iter_size是什麼?和batch_size什麼關係 ?
iter_size : 這個引數乘上你的train prototxt中的batch_size是你實際使用的batch size。 相當於讀取batchsize*itersize個影象才做一下gradient decent。 這個引數可以規避由於gpu不足而導致的batchsize的限
1.雙目視覺官方例項-stereo_calib.cpp、stereo_calib.xml 和 stereo_match.cpp以及26張圖片
1.找到目錄 ...\OpenCV\sources\samples\cpp下的 stereo_calib.cpp、stereo_calib.xml 和 stereo_match.cpp以及26張圖片了(left01-14 right01-14)。
淺談caffe中train_val.prototxt和deploy.prototxt文件的區別
image pixel proto form 準確率 .proto 應用 網絡 基礎 本文以CaffeNet為例: 1. train_val.prototxt 首先,train_val.prototxt文件是網絡配置文件。該文件是在訓練的時候用的。 2.dep
caffe中的前向傳播和反向傳播
sla hit img 部分 可能 說明 caff .com 容易 caffe中的網絡結構是一層連著一層的,在相鄰的兩層中,可以認為前一層的輸出就是後一層的輸入,可以等效成如下的模型 可以認為輸出top中的每個元素都是輸出bottom中所有元素的函數。如果兩個神經元之間沒
caffe中的batchNorm層(caffe 中為什麼bn層要和scale層一起使用)
caffe中的batchNorm層 連結: http://blog.csdn.net/wfei101/article/details/78449680 caffe 中為什麼bn層要和scale層一起使用 這個問題首先你要理解batchnormal是做什麼的。它其實
caffe 中新增新的 layer 和相應測試的過程
新增新 layer 新增一個簡單的 layer 可以參考 https://github.com/BVLC/caffe/wiki/Simple-Example:-Sin-Layer 。 幾個主要的過程如下: 新增 include/caffe/layers/your_layer.
淺談caffe中train_val.prototxt和deploy.prototxt檔案的區別
在剛開始學習的時候,覺得train_val.prototxt檔案和deploy.prototxt檔案很相似,然後當時想嘗試利用deploy.prototxt還原出train_val.prototxt檔案,所以就進行了一下對比,水平有限,可能很多地方說的不到位,希望大神們指點批
Caffe學習筆記1:linux下建立自己的資料庫訓練和測試caffe中已有網路
本文是基於薛開宇 《學習筆記3:基於自己的資料訓練和測試“caffeNet”》基礎上,從頭到尾把實驗跑了一遍~對該文中不清楚的地方做了更正和說明。 主要工作如下: 1、下載圖片建立資料庫 2、將圖片轉化為256*256的lmdb格式 3、計算影象均值 4、定義網路修改部分引
caffe中cpu_data 和mutable_cpu_data
一開始看程式碼的時候會納悶,為啥caffe裡頭又一個 cpu_data還要有一個mutable_cpu_data constvoid* SyncedMemory::cpu_data() {
利用caffe中自帶的工具來視覺化loss 和accuracy
以前只是一股腦的訓練,卻很少注意到這些,今天仔細研究了下,發現caffe自帶技能包.方法如下:1訓練,和以前略有不同的是,./XX.sh|& tee xx.log,保證在caffe-master目錄下生成日誌檔案,或者去根目錄下的temp中尋找也可以.2在caff
Caffe中learning rate 和 weight decay 的理解
The learning rate is a parameter that determines how much an updating step influences the current value of the weights. While weight decay is an additiona
Caffe中檔案引數設定(九-1):訓練和測試自己的圖片-linux版本
在深度學習的實際應用中,我們經常用到的原始資料是圖片檔案,如jpg,jpeg,png,tif等格式的,而且有可能圖片的大小還不一致。而在caffe中經常使用的資料型別是lmdb或leveldb,因此就產生了這樣的一個問題:如何從原始圖片檔案轉換成caffe中能夠執行的db(l
Caffe搭建:常見問題解決辦法和ubuntu使用中遇到問題(持續更新)
嚴正宣告: 在linux下面使用命令列操作時,一定要懂得命令列的意思,然後再執行,要不然在不知道接下來會發生什麼的情況下輸入一通命令,linux很有可能崩掉。 因為在linux下面,使用sudo以及root許可權時,是可以對任意一個檔案進行操作處理的,即使是正在使用的系統檔案。 caffe中出現下
caffe中如何列印/輸出總loss,包括loss和正則項(待完成)
並沒有找到合適的方案,目前來看,需要修改原始碼,但是咋修改原始碼,還沒有搞定。並沒有找到合適的方案,目前來看,需要修改原始碼,但是咋修改原始碼,還沒有搞定。並沒有找到合適的方案,目前來看,需要修改原始碼
C++ 在.h檔案中包含標頭檔案和在.cpp檔案中包含標頭檔案的原則
1、 第一個原則:如果可以不包含標頭檔案,那就不要包含了,這時候前置宣告可以解決問題。如果使用的僅僅是一個類的指標,沒有使用這個類的具體物件(非指標),也沒有訪問到類的具體成員,那麼前置宣告就可以了。因為指標這一資料型別的大小是特定的,編譯器可以獲知(C++編譯
Oracle中如何建立約束,查詢約束和刪除約束(check約束,外來鍵和主鍵約束)
Oracle 建立主鍵,外來鍵, check約束的幾種方法:(write by RFH) 1. 在建立表時建立約束: //新增主鍵約束 Create table userinfo (userid number(20)constraint pk_user primary
Caffe中deploy.prototxt 和 train_val.prototxt 區別
之前用deploy.prototxt 還原train_val.prototxt過程中,遇到了坑,所以打算總結一下本人以熟悉的LeNet網路結構為例子不同點主要在一前一後,相同點都在中間train_val.prototxt 中的開頭看這個名字也知道,裡面定義的是訓練和驗證時候的網路,所以在開始的時候要定義訓練集
圖文+程式碼分析:caffe中全連線層、Pooling層、Relu層的反向傳播原理和實現
1.全連線層反向傳播 設CC為loss 全連線層輸入:(bottom_data) aa 全連線層輸出:(top_data) zz 假設 aa維度K_, zz維度N_,則權值矩陣維度為N_行*K_列,batchsize=M_ 全連線層每個輸出zi=b+∑
Java中的線程狀態轉換和線程控制常用方法
img sta () throw line star height style 技術 Java 中的線程狀態轉換: 【註】:不是 start 之後就立刻開始執行, 只是就緒了(CPU 可能正在運行其他的線程). 【註】:只有被 CPU 調度之後,線程才開始執行, 當