
BZOJ2080 POI2010 Railway & NOIP2008 雙棧排序
題目大意
給定序列(
N≤105 ),判斷能否進行雙棧排序。Sample Input
4
1 3 4 24
2 3 4 1Sample Output
TAK
1 1 2 1NIE
Output Details
TAK is equal to YES, and NIE is equal to NO.
樣例1:火車1進入側線1->火車1出來->火車2進入側線->火車3進入側線2->火車2進入側線1->火車2出來->火車3出來->火車4出來。
主要還是Spy大神和chk大神分別寫了這題的兩種解法,我一個小蒟蒻還是講講自己的心得吧。
寫到這題直接想到了NOIP2008雙棧排序的那題,那道題目在判斷是否可以雙棧排序的時候採用的是暴力建邊以及二分圖染色,時間複雜度是
#define M 1005
int n,q[M],col[M];
vector<int>G[M];
void Add_edge(int u,int v){
G[u].push_back(v);
G[v].push_back(u);
}
bool flag=1;
void color(int u){
for 上述構圖的操作基於以下這個表示式:
- 對於該序列中的一組
i,j,k(i<j<k) ,如果存在q[k]<q[i]<q[j] ,那麼i,j 一定不能同時存在於一個棧中(不只是當前同時存在,也包括曾被壓入同一個棧的情況)。
通過舉例亦可以非常快速的得到結果,嚴謹證明在codevs上有大神寫過。如果滿足上述條件,首先i要比j,k都先壓入棧中,而且為了使i彈出,k必須要先彈出,但是j已經壓住了i,所以無法進行雙棧排序。
之後由於將點分成兩個不同點集並且處於不同點集的點之間才有連線,這個新圖的構成才讓我們想到用二分圖進行處理。
由於考慮字典序,所以操作的時候要優先執行a,b的操作。即在有a,d同時出現的情況下,先a再d;在有b,c同時出現的情況下,先b再c。
(其實列印解也是一個比較困難的問題,但是請考慮自己實現)
以上是雙棧排序的題解,接下來我們考慮如何改進
導致複雜度過高的原因是我們進行了許多無用的建邊。對於最後排序好的序列,可以設想一定會有連續一段區間內的元素都是從1棧出來或者是從2棧出來,那麼這一段區間內的點就被重複構圖了,而本來這一段的點是可以縮成一個點處理的(因為Railway這題並不需要考慮如何彈出的問題)。
現在需要拋開上述的式子,如果我們模擬當前棧內的元素情況,那麼我們只需要滿足
- 對於當前兩個相鄰的區間,將其合併成大區間。
- 判斷當前區間能否放入同一個棧,如果已經知道這兩個區間必須放入不同的棧,說明無法進行雙棧排序。
- 插入新的區間,需要使該區間和目前還在棧中的所有區間放入不同的棧。所以要判斷能否放入不同的區間中。
維護這些區間的資料結構我們一般使用set。下面的程式碼還是要感謝Spy大犇w(゚Д゚)w。
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <cassert>
#include <set>
#define M 100005
using namespace std;
#define Pair pair<int,int>
#define Mp make_pair
bool used[M];
set<Pair>St;
int fa[M<<1],tmp[M<<1],ans[M],res[M];
int getfa(int x){return fa[x]==x?fa[x]:fa[x]=getfa(fa[x]);}
int main(){
int n;
scanf("%d",&n);
for(int i=1;i<=(n<<1);i++)fa[i]=i;
int ned=1;//當前到哪列火車
for(int i=1,x;i<=n;i++){
scanf("%d",&x);
used[x]=true;res[i]=x;
while(used[ned])++ned;//模擬當前車站的情況,現在<ned的都已經彈出
while(!St.empty()&&St.begin()->first<ned)St.erase(St.begin());
if(!St.empty()&&St.begin()->first<x){
set<Pair>::iterator it=St.begin(),ite;
int f=it->first;
for(;it!=St.end()&&it->first<x;){
ite=it;++it;
if(it==St.end()||it->first>x)break;
int a=f,b=it->first,pa=a+n,pb=b+n;
int afa=getfa(a),bfa=getfa(b),pafa=getfa(pa),pbfa=getfa(pb);
if(afa==pbfa||bfa==pafa){puts("NIE");return 0;}
//當前中間所有的點都要放到同一個棧裡。
fa[bfa]=afa,fa[pbfa]=pafa;
if((ite->second)+1==it->first){//此時這兩個相鄰區間是連續的,合併
Pair now=*ite;
now.second=it->second;
St.erase(ite),St.erase(it);
St.insert(now);
it=St.find(now);
}
}
int pf=f+n,px=x+n;
int ffa=getfa(f),xfa=getfa(x),pffa=getfa(pf),pxfa=getfa(px);
if(ffa==xfa||pffa==pxfa){puts("NIE");return 0;}
fa[pxfa]=ffa,fa[xfa]=pffa;
}
St.insert(Mp(x,x));
}
puts("TAK");
for(int i=1;i<=n;i++){
int a=i,pa=i+n;
int afa=getfa(a),pafa=getfa(pa);
if(~tmp[afa]){
tmp[afa]=1,ans[i]=1;
tmp[afa+(afa>n?-n:n)]=-1;
}else{
tmp[pafa]=1,ans[i]=2;
tmp[pafa+(pafa>n?-n:n)]=-1;
}
}
for(int i=1;i<=n;i++)printf("%d%c",ans[res[i]],i==n?'\n':' ');
}然後對著程式碼還要再講一點東西:
模擬進出棧操作,依次往棧中塞入當前車次,此時它與前面所有區間所存放的棧都不相同,如果前面區間存放的棧不是唯一一個,那麼說明無解。然後彈出所有小於當前ned的區間,表示當前已經進行到了第ned班火車出發,且前面都已經依次出去了。
接下來就是合併所有可以合併的區間,並且將區間的棧資訊合併。在處理棧資訊的時候運用影子並查集:
- 如果原值和影子都是並行的(a->b,shadow_a->shadow->b),表示放入同一個棧;
- 如果是交叉的(shadow_a->b,a->shadow_b),說明放入不同的棧。
非常形象。合併的時候也要注意方向,上述程式碼中要求全部都指向區間左端點(即以區間左端點作為所謂的根),這樣方便合併,而且不會因為隱性的問題使程式碼溢位。
啊啊w(゚Д゚)w除錯的時候注意你定義的那些節點的名稱,我因為名稱調了好久。
在輸出結果這個地方的處理中,因為使用了合併結果後的並查集,如果當前可以放入1號棧,說明它指向的父親應當放入1號棧,其他所有指向該父親的就不可以指向2號棧。可以設想後面會形成這樣的指向情況:
即如果讓父親塞入棧1,那麼必須要讓一些元素按照這個關係塞入2中,此時就如同程式碼中一樣只要判斷當前指向的父親是否合法即可,合法指向則塞入1中,否則塞入2中。但是最後還是略略有點遺憾——該程式碼並不是穩定的
O(nlogn) ,原因在於向後遍歷所有區間是O(n) 級別的複雜度,但是考慮到我們能很快就判斷出不滿足的情況,再加上沒有極限資料,所以很快地過掉了。
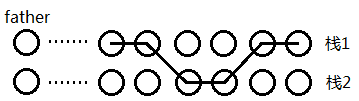
(16/9/26 更新)
接下來是穩定的
我們之前花
顯然的是,一個二分圖的這片生成森林一定也是二分圖,因為斷掉其中的一些邊不會影響原圖的二分情況。而不是二分圖的在最後模擬排序的時候一定會出現問題。
那麼我們只需要完成這個演算法(感謝vflea大犇的思路與虛擬碼)即可:
- 對給定排列計算出生成森林L。
- 計算森林的bicolor方案。
- 確定k是否為G的bicolor方案(情況如上文所說)。
第三步的做法比NOIP2008的模擬簡單,只要按照給出的染色方案判斷是否滿足題意即可。
第二步也是簡單的,在給出了森林之後,我們進行染色,但由於接下來要配合第一步的處理,所以我們需要通過查詢得到下一個相鄰的點,以及刪除這個被選過的點:
modified_dfs(v, color)/* 虛擬碼 */
k[v] = color
delete(v)
while true
do u ← get_edge(v)
if u = null
then break
modified_dfs(u, opposite(color))接下來就是第一步了。
我們通常題目中給出的樹都是沒有定根的無向圖,這是為了方便無根樹轉有根樹的時候可以從任意一個節點開始。現在G構造出的生成森林L是無向的,也就是說,我們需要構建兩條邊:u->v與v->u,才能滿足bicolor。
根據一開始提到的那個式子:
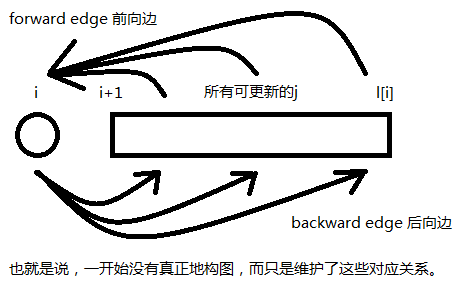
i向j連邊,相當於是i在
- 在i可轉移的區間
[i+1,l[i]] 中找到可更新的點進行染色,單次操作O(logn) 。
接下來就是相對的j->i了,即
- 區間新增某一個元素,單點查詢某元素對應的連結串列,單次操作
O(logn) 。
還有一個刪除操作,對於前面一種詢問只需要將該元素的值改成 連他媽都不認 永遠不可能被取到的值即可;而對於後面的詢問,需要將其從連結串列中全部清除。
剩下就是一大波程式碼細節。
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <vector>
#include <stack>
#define M 100005
#define K 20
using namespace std;
int n,res[M],rag[M];
/* res[i]表示當前序列i下標對應的值。
* rag[val]表示當前序列值為val的下標。
*/
struct backward{
struct Node{
int mx,id;
}tree[M<<2];
Node up(Node a,Node b){
if(a.mx>b.mx)return a;
else return b;
}
int SpMax(int a,int b){
if(a==-1)return b;
if(b==-1)return a;
if(tree[a].mx>tree[b].mx)return a;
return b;
}
void build(int L,int R,int p){
if(L==R){
tree[p]=(Node){res[L],L};
return;
}
int mid=L+R>>1;
build(L,mid,p<<1);
build(mid+1,R,p<<1|1);
tree[p]=up(tree[p<<1],tree[p<<1|1]);
}
void update(int L,int R,int pos,int p){
if(L==R){
tree[p].mx=0;
return;
}
int mid=L+R>>1;
if(pos<=mid)update(L,mid,pos,p<<1);
else update(mid+1,R,pos,p<<1|1);
tree[p]=up(tree[p<<1],tree[p<<1|1]);
}
int query(int l,int r,int mx,int L,int R,int p){
if(l>r||tree[p].mx<mx)return -1;
if(l==L&&r==R)return tree[p].id;
int mid=L+R>>1;
if(r<=mid)return query(l,r,mx,L,mid,p<<1);
else if(l>mid)return query(l,r,mx,mid+1,R,p<<1|1);
else return SpMax(query(l,mid,mx,L,mid,p<<1),query(mid+1,r,mx,mid+1,R,p<<1|1));
}
}Tree1;
int nxt[M*K],pre[M*K];
int id[M<<2],num[M*K],tot=0;
vector<int>Pos[M];//連結串列中的位置
struct forward{
void insert(int l,int r,int x,int L,int R,int p){//此時x指的是元素的值
if(l>r)return;
if(l==L&&r==R){
if(!id[p])id[p]=++tot;//將id[p]之前的指向改成現在的指向,所以要從小到大更新
num[++tot]=x;//記錄這個位置對應的元素值x
pre[nxt[id[p]]]=tot,pre[tot]=id[p];//前趨指標
nxt[tot]=nxt[id[p]],nxt[id[p]]=tot;//後繼指標
Pos[x].push_back(tot);//記錄x在連結串列中的位置
return;
}
int mid=L+R>>1;
if(r<=mid)insert(l,r,x,L,mid,p<<1);
else if(l>mid)insert(l,r,x,mid+1,R,p<<1|1);
else{
insert(l,mid,x,L,mid,p<<1);
insert(mid+1,r,x,mid+1,R,p<<1|1);
}
}
int query(int L,int R,int pos,int p){
for(int i=nxt[id[p]];i;i=nxt[i])
if(num[i]<res[pos])return num[i];
else break;
if(L==R)return -1;
int mid=L+R>>1;
if(pos<=mid)return query(L,mid,pos,p<<1);
else return query(mid+1,R,pos,p<<1|1);
}
}Tree2;
int rgt[M],color[M];//表示最後二分圖染色得到的分配方案。
void remove(int x){
Tree1.update(1,n,rag[x],1);
for(int i=0;i<Pos[x].size();i++){
int p=Pos[x][i];
nxt[pre[p]]=nxt[p];//p->pre->nxt=p->nxt
pre[nxt[p]]=pre[p];//p->nxt->pre=p->pre
}
}
void Modified_dfs(int u,int col){
color[u]=col;
remove(u);
while(true){
int v=Tree1.query(rag[u]+1,rgt[u],u,1,n,1);
if(~v)Modified_dfs(res[v],3-col);
else break;
}
while(true){
int v=Tree2.query(1,n,rag[u],1);
if(~v)Modified_dfs(v,3-col);
else break;
}
}
stack<int>S[3];
bool simulate(){
int ned=1;
S[1].push(n+2),S[2].push(n+2);
for(int i=1;i<=n;i++){
int now=res[i];
if(now>S[color[now]].top())return false;
S[color[now]].push(now);
while(S[1].top()==ned||S[2].top()==ned){
if(S[1].top()==ned)S[1].pop();
else S[2].pop();
++ned;
}
}
return true;
}
void init(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%d",&res[i]);
rag[res[i]]=i;
}
}
void solve(){
int tmp=n+1;
for(int i=n;i>=1;i--){
for(int j=res[i];j<tmp;j++)rgt[j]=i;
tmp=min(tmp,res[i]);
}//處理出對於數值j最遠的座標rgt[j]
Tree1.build(1,n,1);//處理後向邊,只需要查詢其中val最大值
for(int i=n;i>=1;i--)
Tree2.insert(rag[i]+1,rgt[i],i,1,n,1);//前向邊
for(int i=1;i<=n;i++)
if(!color[i])Modified_dfs(i,1);
if(!simulate()){puts("NIE");return;}
puts("TAK");
for(int i=1;i<=n;i++)
printf("%d%c",color[res[i]],i==n?'\n':' ');
}
int main(){init(),solve();}依舊是對著程式碼來講一些東西的時候:
本程式碼最容易出錯的問題是傳進函式的引數是數值還是下標?我除錯的時候因為這個問題感覺程式碼變得面目全非,而且花了好久才找到一大堆問題。
在
O(n) 處理中,當前下標內的值可以更新的區間是[res[i],tmp) ,tmp到n這段是已經更新過的,所以不能再進行更新。所以有可能會出現res[i