
NEON 指令集並行技術優化矩陣旋轉【Android】
阿新 • • 發佈:2018-12-24
參考連結: 利用neon技術對矩陣旋轉進行加速
目標:將輸入矩陣順時針旋轉90度,如下圖所示:
輸入矩陣 輸出矩陣


以 8x8x8bit 的矩陣(更大的矩陣可以分塊為 8x8x8bit)為例,基本的思路就是,逐漸擴大粒度(8bit 到 32bit)的 2x2 矩陣旋轉
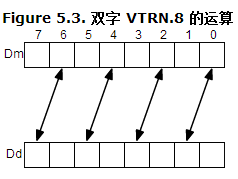
vtrn 示意圖,可以看作是 2x2 矩陣的轉置
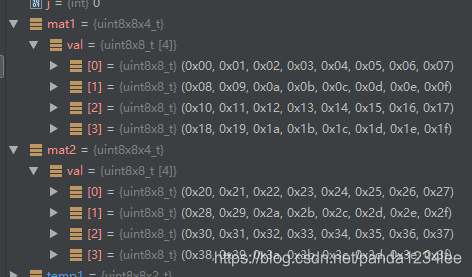
原始的資料的位元組表示形式
以 8 bit 為單位進行旋轉:
temp1 = vtrn_u8(mat1.val[1], mat1.val[0]); temp2 = vtrn_u8(mat1.val[3], mat1.val[2]); temp3 = vtrn_u8(mat2.val[1], mat2.val[0]); temp4 = vtrn_u8(mat2.val[3], mat2.val[2]);

結果以 16 bit 看作一個數(大端儲存)

再次進行旋轉得到
temp9 = vtrn_u16(temp6.val[0], temp5.val[0]);
temp10 = vtrn_u16(temp6.val[1], temp5.val[1]);
temp11 = vtrn_u16(temp8.val[0], temp7.val[0]);
temp12 = vtrn_u16(temp8.val[1], temp7.val[1]);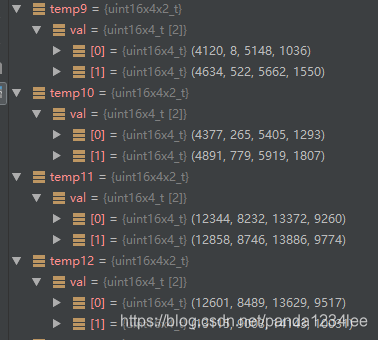
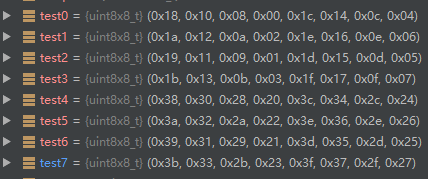
旋轉的結果對應的位元組表示形式為(大端儲存)
接著,把 32bit 當做一個數來旋轉

temp17=vtrn_u32(temp15.val[0],temp13.val[0]);
temp18=vtrn_u32(temp15.val[1],temp13.val[1]);
temp19=vtrn_u32(temp16.val[0],temp14.val[0]);
temp20=vtrn_u32(temp16.val[1],temp14.val[1]);
旋轉的結果為

對應的位元組表示形式為

即最初矩陣的順時針 90 ° 旋轉的結果
程式碼如下:
uint8x8x4_t mat1, mat2;
mat1.val[0] = vld1_u8(srcImg + i * width + j); // vec8,每個元素 8 bit
mat1.val[1] = vld1_u8(srcImg + (i + 1) * width + j);
mat1.val[2] = vld1_u8(srcImg + (i + 2) * width + j);
mat1.val[3] = vld1_u8(srcImg + (i + 3) * width + j);// 4*vec8
mat2.val[0] = vld1_u8(srcImg + (i + 4) * width + j);
mat2.val[1] = vld1_u8(srcImg + (i + 5) * width + j);
mat2.val[2] = vld1_u8(srcImg + (i + 6) * width + j);
mat2.val[3] = vld1_u8(srcImg + (i + 7) * width + j);
uint8x8x2_t temp1, temp2, temp3, temp4;
temp1 = vtrn_u8(mat1.val[1], mat1.val[0]);
temp2 = vtrn_u8(mat1.val[3], mat1.val[2]);
temp3 = vtrn_u8(mat2.val[1], mat2.val[0]);
temp4 = vtrn_u8(mat2.val[3], mat2.val[2]);
// ==============================================
uint16x4x2_t temp5, temp6, temp7, temp8;
temp5.val[0] = vreinterpret_u16_u8(temp1.val[0]);
temp5.val[1] = vreinterpret_u16_u8(temp1.val[1]);
temp6.val[0] = vreinterpret_u16_u8(temp2.val[0]);
temp6.val[1] = vreinterpret_u16_u8(temp2.val[1]);
temp7.val[0] = vreinterpret_u16_u8(temp3.val[0]);
temp7.val[1] = vreinterpret_u16_u8(temp3.val[1]);
temp8.val[0] = vreinterpret_u16_u8(temp4.val[0]);
temp8.val[1] = vreinterpret_u16_u8(temp4.val[1]);
uint16x4x2_t temp9, temp10, temp11, temp12;
temp9 = vtrn_u16(temp6.val[0], temp5.val[0]);
temp10 = vtrn_u16(temp6.val[1], temp5.val[1]);
temp11 = vtrn_u16(temp8.val[0], temp7.val[0]);
temp12 = vtrn_u16(temp8.val[1], temp7.val[1]);
// ==============================================
uint32x2x2_t temp13, temp14, temp15, temp16;
temp13.val[0]= vreinterpret_u32_u16(temp9.val[0]);
temp13.val[1]= vreinterpret_u32_u16(temp9.val[1]);
temp14.val[0]= vreinterpret_u32_u16(temp10.val[0]);
temp14.val[1]= vreinterpret_u32_u16(temp10.val[1]);
temp15.val[0]= vreinterpret_u32_u16(temp11.val[0]);
temp15.val[1]= vreinterpret_u32_u16(temp11.val[1]);
temp16.val[0]= vreinterpret_u32_u16(temp12.val[0]);
temp16.val[1]= vreinterpret_u32_u16(temp12.val[1]);
uint32x2x2_t temp17, temp18, temp19, temp20;
temp17=vtrn_u32(temp15.val[0],temp13.val[0]);
temp18=vtrn_u32(temp15.val[1],temp13.val[1]);
temp19=vtrn_u32(temp16.val[0],temp14.val[0]);
temp20=vtrn_u32(temp16.val[1],temp14.val[1]);
// ==============================================
temp1.val[0]= vreinterpret_u8_u32(temp17.val[0]);
temp1.val[1]= vreinterpret_u8_u32(temp19.val[0]);
temp2.val[0]= vreinterpret_u8_u32(temp18.val[0]);
temp2.val[1]= vreinterpret_u8_u32(temp20.val[0]);
temp3.val[0]= vreinterpret_u8_u32(temp17.val[1]);
temp3.val[1]= vreinterpret_u8_u32(temp19.val[1]);
temp4.val[0]= vreinterpret_u8_u32(temp18.val[1]);
temp4.val[1]= vreinterpret_u8_u32(temp20.val[1]);
vst1_u8 (dstImg + j * height + i, temp1.val[0]);
vst1_u8 (dstImg+ (j+1) * height + i, temp1.val[1]);
vst1_u8 (dstImg+ (j+2) * height + i, temp2.val[0]);
vst1_u8 (dstImg+ (j+3) * height + i, temp2.val[1]);
vst1_u8 (dstImg+ (j+4) * height + i, temp3.val[0]);
vst1_u8 (dstImg+ (j+5) * height + i, temp3.val[1]);
vst1_u8 (dstImg+ (j+6) * height + i, temp4.val[0]);
vst1_u8 (dstImg+ (j+7) * height + i, temp4.val[1]);