
編譯原理-語法分析 二
在第一篇文章中,我們介紹瞭如何用上下文無關文法描述一種語言的語法,和如何使用推導和規約構造一棵語法分析樹,以及如何對文法進行轉換使之能夠更適用於語法分析。在本篇文章中,我們將介紹如何使用自頂向下的方法進行語法分析,進一步的,我們將介紹一種更高效的預測分析方法。
文法&約定
為了下文需要和減少重複,我們先給出在下文中用到的一個表示式文法和一些符號約定。
下面是需要用到的表示式文法,稱其為文法G:
E→TE'
E'→+TE'|ε
T→FT'
T'→*FT'|ε
F→(E)|id
1
2
3
4
5
同樣的,我們在此給出每個下文出現的符號的約定:
大寫字母:表示非終結符號,如A、B、C等;
小寫字母:表示終結符號,如a、b、c等;
希臘字母:表示由終結符號和非終結符號組成的串或空串,如α、β、γ、ω等;
結束標記:把符號$作為結束標記,如輸入結束、棧為空等;
空串:用ε表示長度為0的串,即空串;
語言:用L(G)表示文法G可以生成的所有串的集合,即文法G代表的語言。
自頂向下的語法分析
自頂向下的語法分析可以看作為一個輸入的詞素序列構造語法分析樹的問題,它從語法分析樹的根結點開始,按照前序遍歷順序建立這棵語法分析樹的各個結點。實際上,前序遍歷的建立各個結點的過程就是一個最左推導過程。
使用自頂向下方法構造一棵語法分析樹的關鍵問題是,每次必須確定應用哪一個產生式對一個非終結符號進行推導。對一組產生式和一個非終結符號A,如果只有一個形如A→α的產生式,那麼每次對A的推導只需使用這一個產生式;但是,如果有多個左部為A的產生式如A→α|β|γ,那麼每次對A的推導就不得不決定使用哪一個產生式了。
遞迴下降的語法分析
遞迴下降的語法分析是自頂向下語法分析的通用方法,這種方法可能需要進行回溯。
考慮文法:
S→cAd
A→ab|a
1
2
我們嘗試對串cad構造語法分析樹:
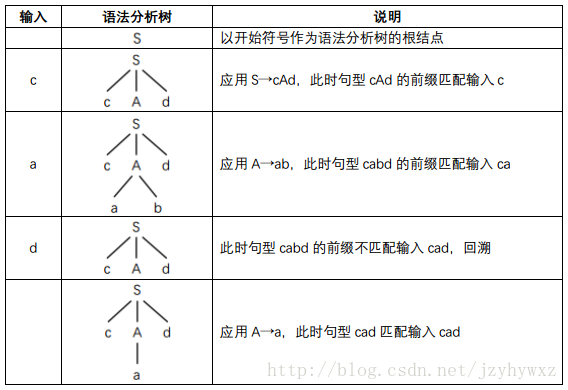
可以發現,在第一次對非終結符號A進行推導後,得到的語法分析樹的句子cabd不匹配輸入cad,因此需要進行回溯;在第二次對A進行推導後,得到的語法分析樹的句子cad匹配輸入cad,到此,成功構造了串cad的語法分析樹,因此我們說串cad是符合該文法的。
預測分析技術
遞迴下降的語法分析方法是不高效的。如果一個文法有大量的以同一個非終結符號作為左部的產生式,在使用遞迴下降的語法分析方法構造一棵語法分析樹時,就可能進行大量的回溯。如果我們能夠唯一確定每個非終結符號在每次推導時使用的產生式,那麼就可以高效的構造語法分析樹。
FIRST和FOLLOW
自頂向下語法分析器的構造可以使用和文法相關的兩個函式FIRST和FOLLOW來實現。在自頂向下語法分析過程中,FIRST和FOLLOW使我們可以根據下一個輸入符號選擇應用哪個產生式。
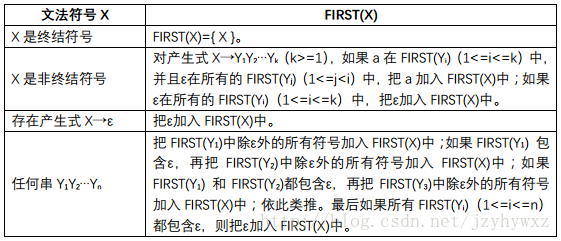
FIRST(α)是可以從α推導得到的串的第一個符號的集合,如果可以從α推匯出ε,那麼ε也在FIRST(α)中。
計算各個文法符號X的FIRST(X)時,不斷應用下列規則,直到沒有新的終結符號或ε被加入FIRST(X)中為止:
對於非終結符號A,FOLLOW(A)被定義為可能在某些句型中緊跟在A右邊的終結符號的集合,如果A是某些句型的最右符號,那麼$也在FOLLOW(A)中。
計算各個非終結符號B的FOLLOW(B)時,不斷應用下列規則,直到沒有新的終結符號被加入FOLLOW(B)中為止:
對文法G應用上述規則得到的FIRST和FOLLOW集合分別為:
預測分析表
上一節介紹瞭如何計算一個文法的FIRST和FOLLOW集合,但是,我們還不清楚FIRST和FOLLOW集合對構建語法分析樹有什麼作用。本節將如何用FIRST和FOLLOW集合構造預測分析表,這張表將幫助我們實現無回溯的遞迴下降的語法分析。
為了消除遞迴下降的語法分析過程中的回溯,我們必須確定對每個非終結符號應用哪一個產生式而不是一次次地嘗試。假設有一組產生式A→α|β,其中α、β的首符號不同並且α、β不能都生成空串ε,對輸入符號a,我們必須確定應用哪一個產生式:
如果a是α的首符號,那麼可以應用產生式A→α;如果a是β的首符號,那麼可以應用產生式A→β;
如果α可能生成空串ε,並且a可能緊跟在A之後,那麼也可以應用產生式A→α;如果β可能生成空串ε,並且a可能緊跟在A之後,那麼也可以應用產生式A→β;
如果前兩步都沒有找到匹配的產生式,那麼從A推導得到的串的字首都不能匹配a。
實際上,步驟1就是FIRST(α)或者FIRST(β),步驟2就是FOLLOW(A),步驟3報告了一個語法錯誤,經過上述步驟後,我們可以唯一確定一個產生式(或者發現一個語法錯誤)。到此,我們知道了如何根據FIRST和FOLLOW集合實現無回溯的遞迴下降的語法分析。
為了方便我們檢視每對非終結符號和輸入符號應該應用哪個產生式,我們把FIRST和FOLLOW集合“組合”成一張表,這張表記為預測分析表M[A, a],它的行頭a表示所有輸入符號和終結符號$,列頭A表示所有非終結符號,表項是零個或多個產生式:
對於FIRST(α)中的每個非終結符號a,將A→α加入到M[A, a]中;
如果ε在FIRST(α)中,那麼對於FOLLOW(A)中的每個終結符號b,將A→α加入到M[A, b]中;如果ε在FIRST(α)中且$在FOLLOW(A)中,也將A→α加入到M[A, $]中。
完成上面的操作後,如果M[A, a]中沒有產生式,那麼M[A, a]表示一個語法錯誤。
注意,上面的規則適用於任何文法,但是左遞迴和二義性的文法構建的預測分析表的某些表項可能有不止一個產生式。
對文法G應用上面的規則,得到其預測分析表如下:
LL(k)文法
對於某些文法,我們可以構造出向前看k個輸入符號的預測分析器,這類文法也稱為LL(k)文法類,其中,第一個“L”表示從左到右掃描輸入,第二個“L”表示產生最左推導,“k”表示在每一步中只需要向前看k個輸入符號來決定語法分析動作。通常情況下,我們只需要向前看一個符號,因此這裡我們只介紹LL(1)文法。
一個文法是LL(1)的,當且僅當該文法不是左遞迴和二義性的。LL(1)文法的預測分析表的每個表項最多隻有一個產生式,正因如此,我們才能唯一確定對每對非終結符號和輸入符號應用的產生式。
表驅動的預測語法分析
該節的內容實質上和上文的預測分析技術一樣,只不過更加系統的闡述瞭如何使用預測分析技術從一個輸入串得到一個最左推導。
一個由分析表驅動的語法分析器由輸入緩衝區、文法符號棧、預測分析表和結果輸出流組成,如下圖所示:
其中的預測分析過程如下:
對文法G,在上文已經得到了其預測分析表,考慮輸入串id+id*id,其預測分析過程如下:
上圖中棧的棧頂在左邊,把輸出組合起來就得到串id+id*id的一個最左推導。
---------------------
作者:jzyhywxz
來源:CSDN
原文:https://blog.csdn.net/jzyhywxz/article/details/78404558
版權宣告:本文為博主原創文章,轉載請附上博文連結!