馬蜂窩遊記爬蟲指南
阿新 • • 發佈:2018-12-24
1.首先是找到遊記地址,找到遊記地址就很費勁
在攻略和目的地欄找了,搜了半天西安,才勉強找到地址
在頁面最下方
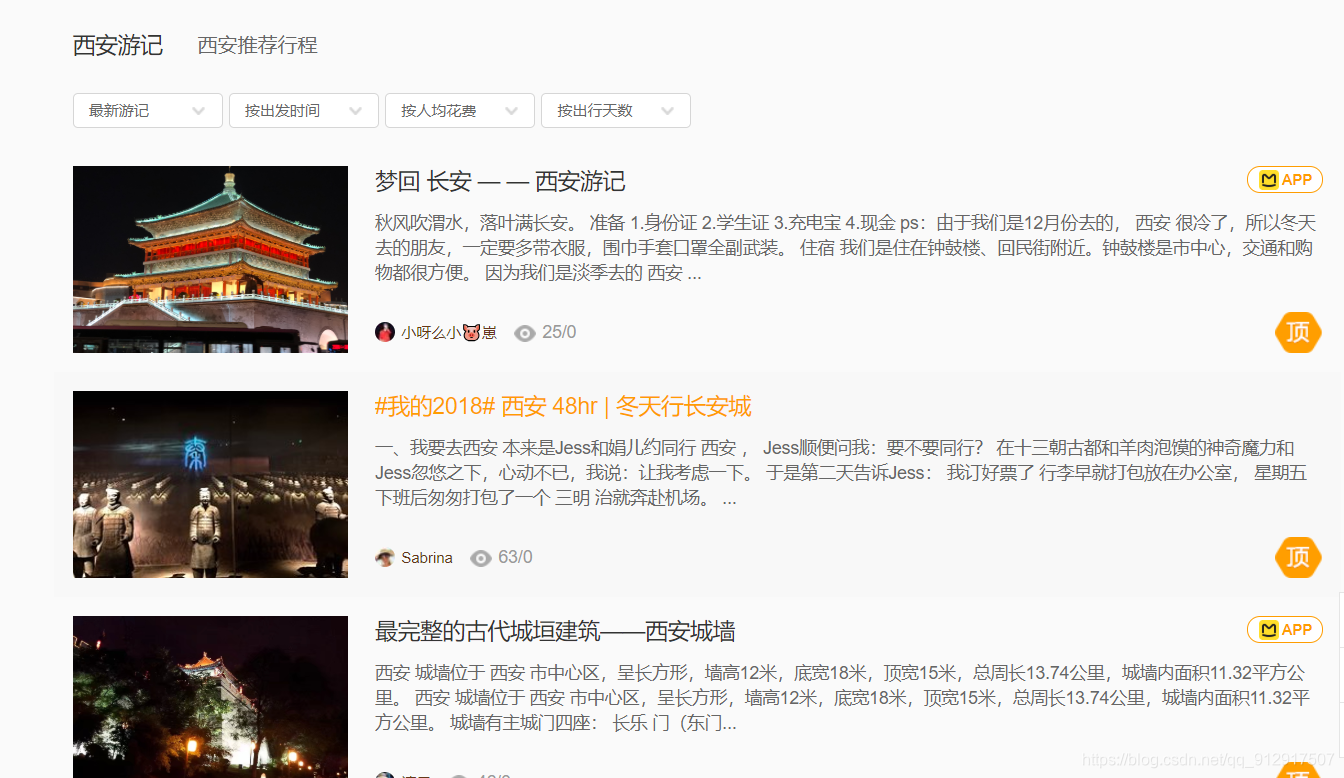
把最熱遊記改成最新遊記,最熱只出300頁,3000條,

最新就是全部2538頁,25373條

2.F12 找到分頁地址,指向翻頁按鈕
例如指向第3頁的按鈕
<a class="pi" href="1-0-3.html" title="第3頁">3</a>在F12的頁面中直接點選這個連結
可以直接進入遊記頁面
終於找到了遊記的真實地址
想爬遊記要找詳情頁
最新遊記第2頁的網址,
http:/.../2-0-2.html
第n也就是(2變成1,就是最熱遊記,只有3000篇)
http:/.../10195/2-0-n.html實際網址規則是等差數列
3.迴圈爬取詳情頁網址,可以採用網址探測器,探測一級就夠了
探測和採集的網址中會出現不是遊記詳情頁的網址,設定規則,只爬取詳情頁格式的網址
探測的網址格式如下,以第二頁為例,不設定規則,就會連圖片都探測出來,193條網址
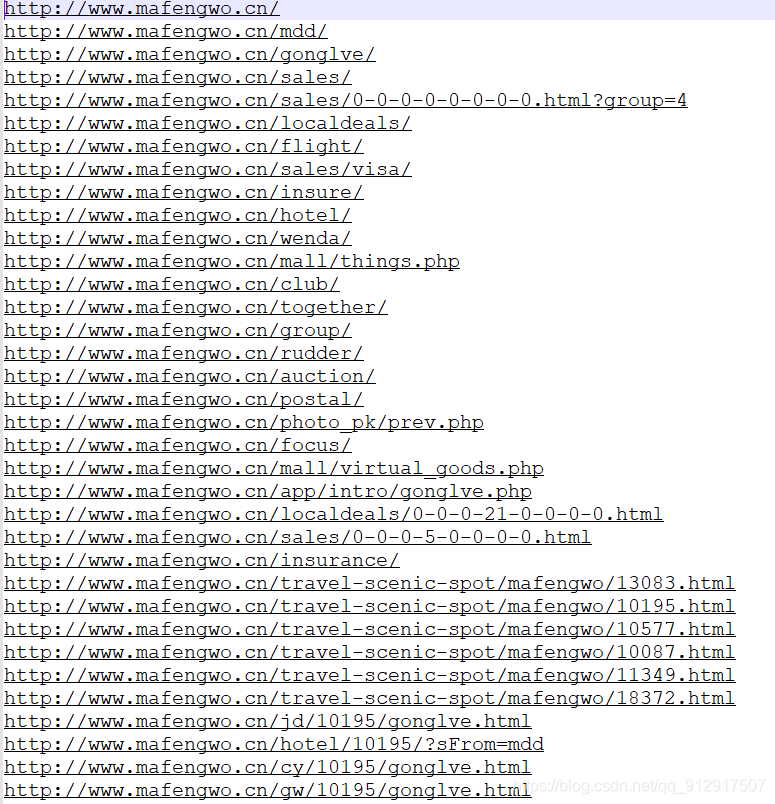
加入規則,需要包含規定字串的網址
4.爬取詳情頁內容,設定好規則
使用Xpath方法,找到各詳情頁網址你想爬的內容
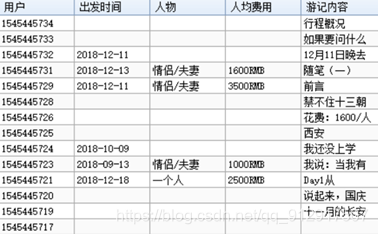
最終效果如圖所示