
利用python爬蟲成功突破12306反爬機制「打包更新」
12306自動搶票
已經到春運了,在這裡為大家奉上一個搶票的軟體,希望大家喜歡哦!
最近12306更新的比較快,而且反爬比較嚴重,研究了好長時間也不容易。
希望大家可以免費點個贊,隨手轉發一下,這裡的驗證碼。

會在本地當前目錄生成一個12306_yzm.png的圖片,輸入相應的序號即可,後續按程式輸入相應的引數即可!
有問題或者BUG請等待更新哦!
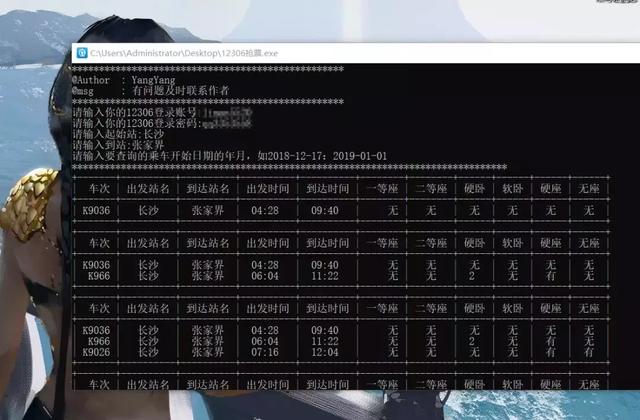
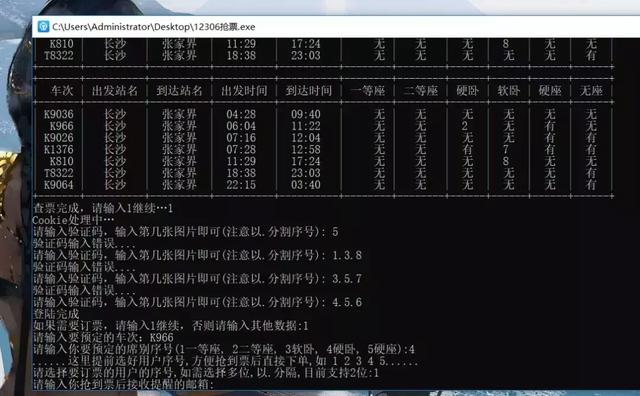
注意事項
W10請以管理員方式執行!!
有BUG歡迎留言!
https://pan.baidu.com/s/1EflMCY2a88u8635Zk6UjWA 提取碼:jk28
相關推薦
利用python爬蟲成功突破12306反爬機制「打包更新」
12306自動搶票 已經到春運了,在這裡為大家奉上一個搶票的軟體,希望大家喜歡哦! 最近12306更新的比較快,而且反爬比較嚴重,研究了好長時間也不容易。 希望大家可以免費點個贊,隨手轉發一下,這裡的驗證碼。 會在本地當
Python爬蟲六:字型反爬處理(貓眼+汽車之家)-2018.10
環境:Windows7 +Python3.6+Pycharm2017 目標:貓眼電影票房、汽車之家字型反爬的處理 --------全部文章: 京東爬蟲 、鏈家爬蟲、美團爬蟲、微信公眾號爬蟲、字型反爬--------- 前言:字型反爬,
利用Python爬蟲爬取淘寶商品做數據挖掘分析實戰篇,超詳細教程
實戰 趨勢 fat sts AI top 名稱 2萬 安裝模塊 項目內容 本案例選擇>> 商品類目:沙發; 數量:共100頁 4400個商品; 篩選條件:天貓、銷量從高到低、價格500元以上。 項目目的 1. 對商品標題進行文本分析 詞雲可視化 2.
利用python爬蟲爬取圖片並且制作馬賽克拼圖
python爬蟲 splay ise 做事 c-c sea mage item -a 想在妹子生日送妹子一張用零食(或者食物類好看的圖片)拼成的馬賽克拼圖,因此探索了一番= =。 首先需要一個軟件來制作馬賽克拼圖,這裏使用Foto-Mosaik-Edda(網上也有在
python網頁爬蟲開發之五-反爬
build referer mac eee pac -o strip 不響應 win64 1、頭信息檢查是否頻繁相同 隨機產生一個headers, #user_agent 集合 user_agent_list = [ ‘Mozilla/5.0 (Windows N
利用python爬蟲技術動態爬取地理空間資料雲中的元資料(selenium)
python爬取地理空間資料雲selenium動態點選 爬取的網址秀一下: 爬取的資訊是什麼呢? 這個資訊的爬取涉及到右邊按鈕的點選,這屬於動態爬取的範疇,需要用到selenium 好了,那麼開始寫程式碼吧 首先匯入selenium from seleni
利用Python爬蟲爬取京東商品的簡要資訊
一、前言 本文適合有一定Python基礎的同學學習Python爬蟲,無基礎請點選:慕課網——Python入門 申明:例項的主體框架來自於慕課網——Python開發簡單爬蟲 語言:Python2 IDE:VScode二、何為爬蟲 傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的UR
資料視覺化 三步走(一):資料採集與儲存,利用python爬蟲框架scrapy爬取網路資料並存儲
前言 最近在研究python爬蟲,突然想寫部落格了,那就寫點東西吧。給自己定個小目標,做一個完整的簡單的資料視覺化的小專案,把整個相關技術鏈串聯起來,目的就是為了能夠對這塊有個系統的認識,具體設計思路如下: 1. 利用python爬蟲框架scr
利用python爬蟲爬取京東商城商品圖片
筆者曾經用python第三方庫requests來爬取京東商城的商品頁內容,經過解析之後發現只爬到了商品頁一半的圖片。(這篇文章我們以爬取智慧手機圖片為例)當滑鼠沒有向下滑時,此時檢視原始碼的話,就會看到上圖的內容,只有三十個 li 標籤(一個li標籤中有一個圖片地址)。但是滑
大神教你如果學習Python爬蟲 如何才能高效地爬取海量數據
Python 爬蟲 分布式 大數據 編程 Python如何才能高效地爬取海量數據我們都知道在互聯網時代,數據才是最重要的,而且如果把數據用用得好的話,會創造很大的價值空間。但是沒有大量的數據,怎麽來創建價值呢?如果是自己的業務每天都能產生大量的數據,那麽數據量的來源問題就解決啦,但是沒有數
【Python爬蟲】從html裏爬取中國大學排名
ext 排名 所有 一個 requests 空格 創建 .text request from bs4 import BeautifulSoupimport requestsimport bs4 #bs4.element.Tag時用的上#獲取網頁頁面HTMLdef
python爬蟲-20行代碼爬取王者榮耀所有英雄圖片,小白也輕輕松松
需要 tis tca wcf 爬取 html eas request 有用 1.環境 python3.6 需要用到的庫: re、os、requests 2.簡介 王者榮耀可以算得上是比較受歡迎的手遊之一了,應該有不少的人都入坑過農藥,我們今天的目的就是要爬取王者榮耀的高
Python爬蟲初探 - selenium+beautifulsoup4+chromedriver爬取需要登錄的網頁信息
-- pro tag bug gui 結果 .com 工作 ges 目標 之前的自動答復機器人需要從一個內部網頁上獲取的消息用於回復一些問題,但是沒有對應的查詢api,於是想到了用腳本模擬瀏覽器訪問網站爬取內容返回給用戶。詳細介紹了第一次探索python爬蟲的坑。 準備工作
【Python爬蟲實戰專案一】爬取大眾點評團購詳情及團購評論
1 專案簡介 從大眾點評網收集北京市所有美髮、健身類目的團購詳情以及團購評論,儲存為本地txt檔案。 技術:Requests+BeautifulSoup 以美髮為例:http://t.dianping.com/list/beijing?q=美髮 爬取內容包括: 【團購詳情】團購名稱、原
Python爬蟲實習筆記 | Week3 資料爬取和正則再學習
2018/10/29 1.所思所想:雖然自己的考試在即,但工作上不能有半點馬虎,要認真努力,不辜負期望。中午和他們去吃飯,算是吃飯創新吧。下午爬了雞西的網站,還有一些欄位沒爬出來,正則用的不熟悉,此時終於露出端倪,心情不是很好。。明天上午把正則好好看看。 2.工作: [1].哈爾濱:html p
python 爬蟲proxy,BeautifulSoup+requests+mysql 爬取樣例
實現思路: 由於反扒機制,所以需要做代理切換,去爬取,內容通過BeautifulSoup去解析,最後入mysql庫 1.在西刺免費代理網獲取代理ip,並自我檢測是否可用 2.根據獲取的可用代理ip去傳送requests模組的請求,帶上代理 3.內容入庫 注:日
Python爬蟲系列之小說網爬取
今日爬蟲—小說網 再次宣告所有爬蟲僅僅為技術交流,沒有任何惡意,若有侵權請☞私信☚ 此次爬取由主頁爬取到各本小說地址,然後通過這些地址獲取到小說目錄結構,在通過目錄結構獲取章節內容,同時以小說名字為資料夾,每一個章節為txt文字儲存到本地。 話不多說,直接上程式碼
Python爬蟲實戰 requests+beautifulsoup+ajax 爬取半次元Top100的cos美圖
1.Python版本以及庫說明 Python3.7.1 Python版本urlencode 可將字串以URL編碼,用於編碼處理bs4 解析html的利器re 正則表示式,用於查詢頁面的一些特定內容requests 得到網頁html、jpg等資源的
Python爬蟲入門之豆瓣短評爬取
採用工具pyCharm,python3,工具的安裝在這就不多說了,之所以採用python3是因為python2只更新維護到2020年。 新建python專案 File-Settings-project interpreter,點右上角+號,安裝requests,lx
爬蟲案例|從攻克反爬機制到地理資訊視覺化!
上圖是上海醫療服務資訊便民查詢系統網站(http://www.soyi.sh.cn/)上公佈的醫療機構位置的熱力圖。 本案例先從該網站抓取全部醫療機構的座標資訊,然後用免費的BDP個人版(http://www.bdp.cn)線上做圖。爬取資料時,我找到了資料的API介面,