淺析Scrapy框架執行的基本流程
一、Twisted的下載任務基本過程
首先需要我們匯入三個基本的模組
1 from twisted.internet importreactor 2 from twisted.web.client import getPage 3 from twisted.internet import defer
-
-
getPage的作用是自動幫我們建立socket物件,模擬瀏覽器給伺服器傳送請求,放到reactor裡面,一旦下載到需要的資料,socket將發生變化,就可以被reactor監聽到。(如果下載完成,自動從事件迴圈中移除) -
defer裡面的defer.Deferred()的作用是建立一個特殊的socket物件,它不會發送請求,如果放在事件迴圈裡面,將永遠不會被移除掉,需要我們自己手動移除,作用就是使事件迴圈一直監聽,不會停止。(不會發請求,手動移除)
1、利用getPage建立socket
def response(content): print(content) def task(): url = "http://www.baidu.com" d = getPage(url) # 建立socket物件,獲取返回的物件d,它其實也是一個Deferred物件d.addCallback(response) # 當頁面下載完成,自動執行函式response,來處理返回資料
但以上內容你可以理解只是建立了socket,並且給了執行結束後應該執行的函式。但還沒有加到事件迴圈。
2.將socket新增到事件迴圈中
def response(content): print(content) @defer.inlineCallbacks # 新增事件迴圈 def task(): url = "http://www.baidu.com" d = getPage(url) d.addCallback(response) yield d
3、開始事件迴圈
def response(content): print(content) @defer.inlineCallbacks def task(): url = "http://www.baidu.com" d = getPage(url.encode('utf-8')) d.addCallback(response) yield d task() # 執行函式 reactor.run() # 開啟事件迴圈。不先執行函式的話,在內部迴圈中該函式是不會執行的。
4、開始事件迴圈(自動結束)
def response(content): print(content) @defer.inlineCallbacks def task(): url = "http://www.baidu.com" d = getPage(url.encode('utf-8')) d.addCallback(response) yield d d = task() dd = defer.DeferredList([d,]) dd.addBoth(lambda _:reactor.stop()) # 監聽d是否完成或者失敗,如果是,呼叫回撥函式,終止事件迴圈 reactor.run()
5、併發操作
_closewait = None def response(content): print(content) @defer.inlineCallbacks def task(): """ 每個爬蟲的開始:stats_request :return: """ url = "http://www.baidu.com" d1 = getPage(url.encode('utf-8')) d1.addCallback(response) url = "http://www.cnblogs.com" d2 = getPage(url.encode('utf-8')) d2.addCallback(response) url = "http://www.bing.com" d3 = getPage(url.encode('utf-8')) d3.addCallback(response) global _closewait _close = defer.Deferred() yield _closewait spider1 = task() dd = defer.DeferredList([spider1,]) dd.addBoth(lambda _:reactor.stop()) reactor.run()
6、手動關閉
_closewait = None count = 0 def response(content): print(content) global count count += 1 if count == 3: # 當等於3時,說明發出去的url的響應都拿到了 _closewait.callback(None) @defer.inlineCallbacks def task(): """ 每個爬蟲的開始:stats_request :return: """ url = "http://www.baidu.com" d1 = getPage(url.encode('utf-8')) d1.addCallback(response) url = "http://www.cnblogs.com" d2 = getPage(url.encode('utf-8')) d2.addCallback(response) url = "http://www.bing.com" d3 = getPage(url.encode('utf-8')) d3.addCallback(response) global _closewait _close = defer.Deferred() yield _closewait spider = task() dd = defer.DeferredList([spider, ]) dd.addBoth(lambda _:reactor.stop()) reactor.run()
(2)將socket新增到事件迴圈中
(3)開始事件迴圈 (內部發送請求,並接受響應;當所有的socekt請求完成後,終止事件迴圈)
在理解了上面的內容之後,那麼接下來的部分將會變得輕鬆,基本的思想和上面差不多。
1、首先我們建立一個爬蟲ChoutiSpider,如下程式碼所示。
有些人可能不知道start_requests是什麼,其實這個跟我們用Scrapy建立的一樣,這個函式在我們繼承的scrapy.Spider裡面,作用就是取start_url列表裡面的url,並把url和規定好的回撥函式parse傳給Request類處理。需要注意的是這裡的Request我們只是簡單的接收來自start_requests傳來的值,不做真正的處理,例如傳送url請求什麼的
from twisted.internet import defer from twisted.web.client import getPage from twisted.internet import reactor class Request(object): def __init__(self,url,callback): self.url = url self.callback = callback class ChoutiSpider(object): name = 'chouti' def start_requests(self): start_url = ['http://www.baidu.com','http://www.bing.com',] for url in start_url: yield Request(url,self.parse) def parse(self,response): print(response) #response是下載的頁面 yield Request('http://www.cnblogs.com',callback=self.parse)
2、建立引擎Engine,用來接收需要執行的spider物件
from twisted.internet import defer from twisted.web.client import getPage from twisted.internet import reactor class Request(object): def __init__(self,url,callback): self.url = url self.callback = callback class ChoutiSpider(object): name = 'chouti' def start_requests(self): start_url = ['http://www.baidu.com','http://www.bing.com',] for url in start_url: yield Request(url,self.parse) def parse(self,response): print(response) #response是下載的頁面 yield Request('http://www.cnblogs.com',callback=self.parse) import queue Q = queue.Queue() # 排程器 class Engine(object): def __init__(self): self._closewait = None @defer.inlineCallbacks def crawl(self,spider): start_requests = iter(spider.start_requests()) # 把生成器Request物件轉換為迭代器 while True: try: request = next(start_requests) # 把Request物件放到排程器裡面 Q.put(request) except StopIteration as e: break self._closewait = defer.Deferred() yield self._closewait
from twisted.internet import defer from twisted.web.client import getPage from twisted.internet import reactor class Request(object): def __init__(self,url,callback): self.url = url self.callback = callback class ChoutiSpider(object): name = 'chouti' def start_requests(self): start_url = ['http://www.baidu.com','http://www.bing.com',] for url in start_url: yield Request(url,self.parse) def parse(self,response): print(response) #response是下載的頁面 yield Request('http://www.cnblogs.com',callback=self.parse) import queue Q = queue.Queue() class Engine(object): def __init__(self): self._closewait = None self.max = 5 # 最大併發數 self.crawlling = [] # 正在爬取的爬蟲個數 def get_response_callback(self,content,request): # content就是返回的response, request就是一開始返回的迭代物件 self.crawlling.remove(request) result = request.callback(content) # 執行parse方法 import types if isinstance(result,types.GeneratorType): # 判斷返回值是否是yield,如 for req in result: # 果是則加入到佇列中 Q.put(req) def _next_request(self): """ 去排程器中取request物件,併發送請求 最大併發數限制 :return: """ # 什麼時候終止 if Q.qsize() == 0 and len(self.crawlling) == 0: self._closewait.callback(None) # 結束defer.Deferred return if len(self.crawlling) >= self.max: return while len(self.crawlling) < self.max: try: req = Q.get(block=False) # 設定為非堵塞 self.crawlling.append(req) d = getPage(req.url.encode('utf-8')) # 傳送請求 # 頁面下載完成,執行get_response_callback,並且將一開始的迭代物件req作為引數傳過去 d.addCallback(self.get_response_callback,req) # 未達到最大併發數,可以再去排程器中獲取Request d.addCallback(lambda _:reactor.callLater(0, self._next_request)) # callLater表示多久後呼叫 except Exception as e: print(e) return @defer.inlineCallbacks def crawl(self,spider): # 將初始Request物件新增到排程器 start_requests = iter(spider.start_requests()) while True: try: request = next(start_requests) Q.put(request) except StopIteration as e: break # 去排程器中取request,併發送請求 # self._next_request() reactor.callLater(0, self._next_request) self._close = defer.Deferred() yield self._closewait spider = ChoutiSpider() _active = set() engine = Engine() d = engine.crawl(spider) _active.add(d) dd = defer.DeferredList(_active) dd.addBoth(lambda _:reactor.stop()) reactor.run()
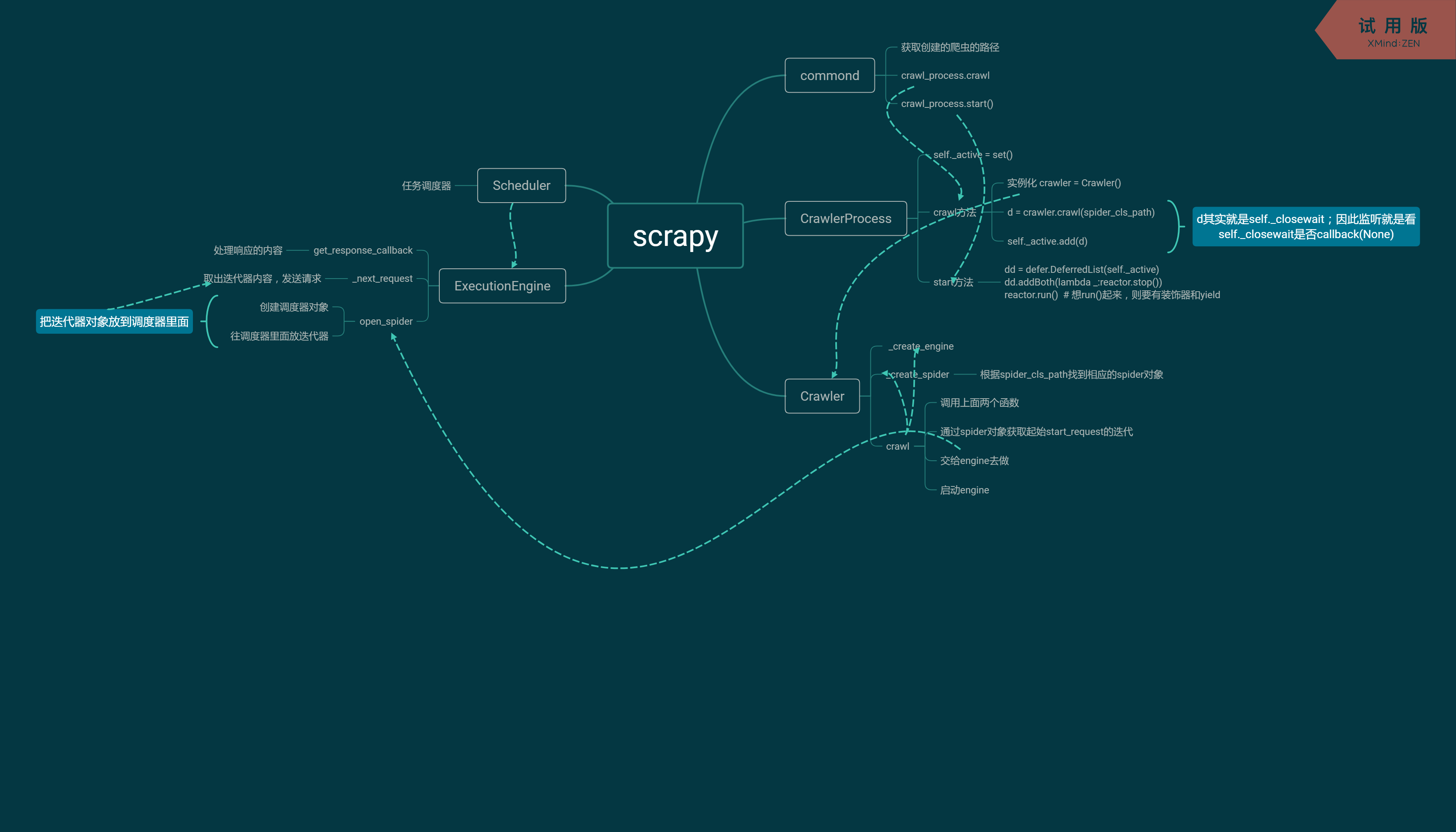
上面其實就是Scrapy框架的基本實現過程,不過要想更進一步的瞭解,就需要模仿Scrapy的原始碼,把各個函式的功能獨立封裝起來,如下。
三、封裝
from twisted.internet import reactor from twisted.web.client import getPage from twisted.internet import defer from queue import Queue class Request(object): """ 用於封裝使用者請求相關資訊 """ def __init__(self,url,callback): self.url = url self.callback = callback class HttpResponse(object): # 對返回的content和request做進一步封裝,集合到response裡面。然後通過回撥函式parse呼叫response.xxx可以呼叫不同的功能。具體過程略 def __init__(self,content,request): self.content = content self.request = request class Scheduler(object): """ 任務排程器 """ def __init__(self): self.q = Queue() def open(self): pass def next_request(self): # 取排程器裡面的值併發送 try: req = self.q.get(block=False) except Exception as e: req = None return req def enqueue_request(self,req): self.q.put(req) def size(self): return self.q.qsize() class ExecutionEngine(object): """ 引擎:所有排程 """ def __init__(self): self._closewait = None self.scheduler = None self.max = 5 self.crawlling = [] def get_response_callback(self,content,request): self.crawlling.remove(request) response = HttpResponse(content,request) result = request.callback(response) # 執行request裡面的回撥函式(parse) import types if isinstance(result,types.GeneratorType): for req in result: self.scheduler.enqueue_request(req) def _next_request(self): if self.scheduler.size() == 0 and len(self.crawlling) == 0: self._closewait.callback(None) return while len(self.crawlling) < self.max: req = self.scheduler.next_request() if not req: return self.crawlling.append(req) d = getPage(req.url.encode('utf-8')) d.addCallback(self.get_response_callback,req) d.addCallback(lambda _:reactor.callLater(0,self._next_request)) @defer.inlineCallbacks def open_spider(self,start_requests): self.scheduler = Scheduler() # 建立排程器物件 while True: try: req = next(start_requests) except StopIteration as e: break self.scheduler.enqueue_request(req) # 放進排程器裡面 yield self.scheduler.open() # 使用那個裝飾器後一定要有yield,因此傳個 None 相當於yield None reactor.callLater(0,self._next_request) @defer.inlineCallbacks def start(self): self._closewait = defer.Deferred() yield self._closewait class Crawler(object): """ 使用者封裝排程器以及引擎的... """ def _create_engine(self): # 建立引擎物件 return ExecutionEngine() def _create_spider(self,spider_cls_path): """ :param spider_cls_path: spider.chouti.ChoutiSpider :return: """ module_path,cls_name = spider_cls_path.rsplit('.',maxsplit=1) import importlib m = importlib.import_module(module_path) cls = getattr(m,cls_name) return cls() @defer.inlineCallbacks def crawl(self,spider_cls_path): engine = self._create_engine() # 需要把任務交給引擎去做 spider = self._create_spider(spider_cls_path) # 通過路徑獲取spider,建立物件 start_requests = iter(spider.start_requests()) yield engine.open_spider(start_requests) # 把迭代器往排程器裡面放 yield engine.start() # 相當於self._closewait方法 class CrawlerProcess(object): """ 開啟事件迴圈 """ def __init__(self): self._active = set() def crawl(self,spider_cls_path): # 每個爬蟲過來只負責建立一個crawler物件 """ :param spider_cls_path: :return: """ crawler = Crawler() d = crawler.crawl(spider_cls_path) self._active.add(d) def start(self): # 開啟事件迴圈 dd = defer.DeferredList(self._active) dd.addBoth(lambda _:reactor.stop()) reactor.run() # 想run()起來,則要有裝飾器和yield class Commond(object): def run(self): crawl_process = CrawlerProcess() spider_cls_path_list = ['spider.chouti.ChoutiSpider','spider.cnblogs.CnblogsSpider',] for spider_cls_path in spider_cls_path_list: crawl_process.crawl(spider_cls_path) # 建立多個defer物件,也就是把d新增到_active裡面 crawl_process.start() # 統一呼叫一次,相當於reactor.run() if __name__ == '__main__': cmd = Commond() cmd.run()
其實上面的程式碼就是從下往上依次執行,每個類之間各個完成不同的功能。
配合下面的思維導圖,希望可以幫助理解。