
時間序列實戰(一)
匯入資料,並轉化為時間序列
#coding:utf-8
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pylab as plt
plt.rcParams['font.sans-serif']=['SimHei']
from matplotlib.pylab import rcParams
from statsmodels.tsa.stattools import adfuller
dateparse = lambda dates: pd.datetime.strptime(dates, '%Y/%m/%d' 平穩性檢測
- 方法一:時序圖
from pylab import *
plt.plot(ts)
plt.title(u'當天出庫')
show()輸出:
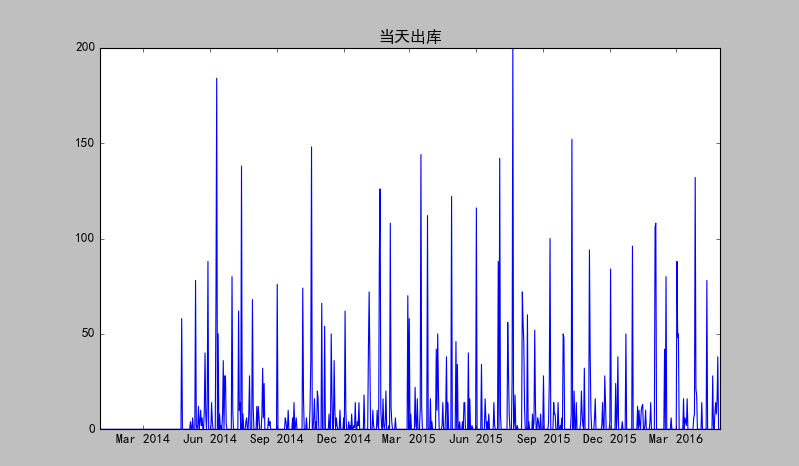
序列始終在一個常數值附近隨機波動,且波動範圍有界,且沒有明顯的趨勢性或週期性,所以可認為是平穩序列。
- 方法二:自相關圖
from statsmodels.graphics.tsaplots import plot_pacf,plot_acf
plot_acf(ts)
show()輸出:
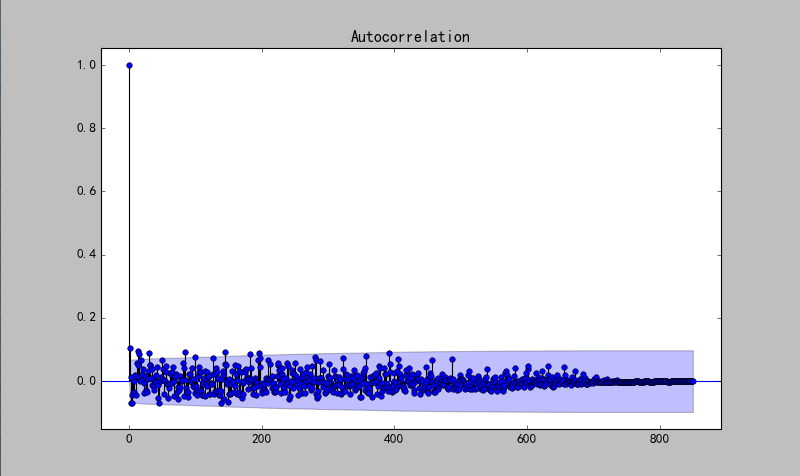
自相關係數會很快衰減向0,所以可認為是平穩序列。
- 方法三:ADF單位根檢驗(精確判斷)
temp = np.array(ts)
t = sm.tsa.stattools.adfuller(temp) # ADF檢驗
output=pd.DataFrame(index=['Test Statistic Value', "p-value", "Lags Used", "Number of Observations Used","Critical Value(1%)","Critical Value(5%)","Critical Value(10%)"],columns=['value'])
output['value' 輸出:
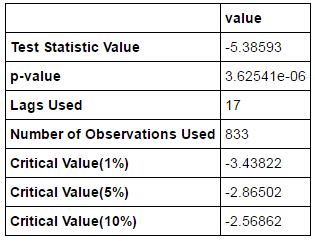
單位根檢驗統計量對應的P值遠小於0.05,故該序列可確認為平穩序列。
純隨機性檢驗(白噪聲檢驗)
from statsmodels.stats.diagnostic import acorr_ljungbox
print u'序列的純隨機性檢測結果為:',acorr_ljungbox(ts,lags = 1)輸出:
序列的純隨機性檢測結果為: (array([ 9.10802245]), array([ 0.00254491]))P=0.00254491,統計量的P值小於顯著性水平0.05,則可以以95%的置信水平拒絕原假設,認為序列為非白噪聲序列(否則,接受原假設,認為序列為純隨機序列。)
綜上:原序列為平穩非白噪聲序列,適用於ARMA模型。
識別ARMA模型階次
- 方法一:ACF、PACF 判斷模型階次
from statsmodels.graphics.tsaplots import plot_pacf,plot_acf
plot_acf(ts)
plot_pacf(ts)
show()輸出:
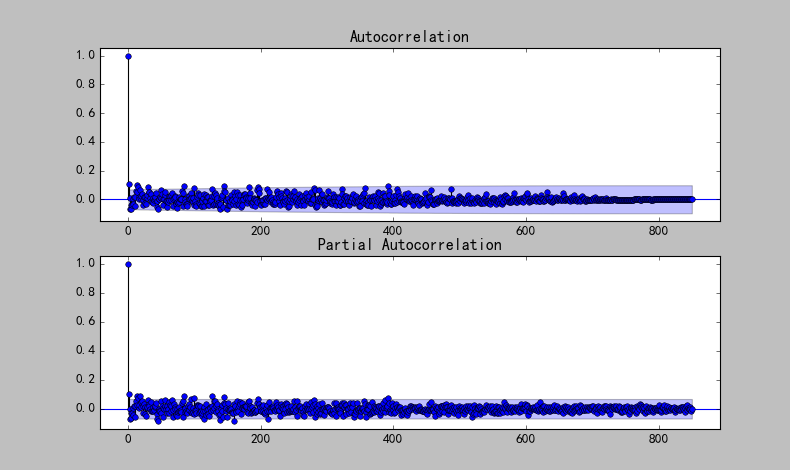
可以看出,模型的階次應該為(200,400),階數高,計算量過大。採用另外一種方法確定階數。
- 方法二:資訊準則定階
目前選擇模型常用如下準則: (其中L為似然函式,k為引數數量,n為觀察數)
AIC = -2 ln(L) + 2 k 中文名字:赤池資訊量 akaike information criterion
BIC = -2 ln(L) + ln(n)*k 中文名字:貝葉斯資訊量 bayesian information criterion
HQ = -2 ln(L) + ln(ln(n))*k hannan-quinn criterion
我們常用的是AIC準則,同時需要儘量避免出現過擬合的情況。所以優先考慮的模型應是AIC值最小的那一個模型。
為了控制計算量,在此限制AR最大階不超過6,MA最大階不超過4。 但是這樣帶來的壞處是可能為區域性最優。
import statsmodels.api as sm
sm.tsa.arma_order_select_ic(ts,max_ar=6,max_ma=4,ic='aic')['aic_min_order'] # AIC輸出:
(3, 2)sm.tsa.arma_order_select_ic(ts,max_ar=6,max_ma=4,ic='bic')['bic_min_order'] # BIC輸出:
(1, 0)sm.tsa.arma_order_select_ic(ts,max_ar=6,max_ma=4,ic='hqic')['hqic_min_order'] # HQIC輸出:
(3, 2)AIC求解的模型階次為(3,2)
BIC求解的模型階次為(1,0)
HQIC求解的模型階次為(3,2)
這裡就以AIC準則為準,選擇(3,2),也可依次嘗試每一種準則,選擇最優。
模型的建立及預測
上一步驟已確定了ARMA模型的階數為(3,2),接下來進行模型的建立和預測工作。將原資料分為訓練集和測試集,選擇最後10個數據用於預測。
order = (3,2)
train = ts[:-10]
test = ts[-10:]
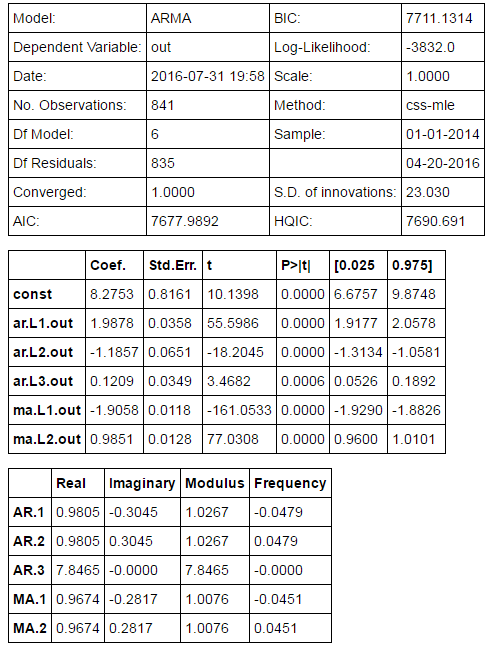
tempModel = sm.tsa.ARMA(train,order).fit()
#tempModel.summary2()給出一份模型報告輸出:
接下來預測最後10天的資料:
tempModel.forecast(10)輸出:
(array([ 5.29077389, 3.45200299, 4.61117218, 6.3501017 ,
8.20994055, 9.98513142, 11.51878938, 12.68732223,
13.40622711, 13.6351102 ]),
array([ 23.03022024, 23.10739399, 23.12377736, 23.15402121,
23.17973782, 23.19614362, 23.20345806, 23.20486727,
23.20499493, 23.20820176]),
array([[-39.84762834, 50.42917612],
[-41.837657 , 48.74166298],
[-40.71059863, 49.93294299],
[-39.03094596, 51.73114937],
[-37.22151076, 53.64139185],
[-35.47847465, 55.4487375 ],
[-33.95915273, 56.99673149],
[-32.79338188, 58.16802634],
[-32.07472721, 58.88718143],
[-31.85212939, 59.12234979]]))最後10天的預測資料為:
5.29077389, 3.45200299, 4.61117218, 6.3501017 ,8.20994055,
9.98513142, 11.51878938, 12.68732223,13.40622711, 13.6351102
擬合效果:
delta = tempModel.fittedvalues - train
score = 1 - delta.var()/train.var()
print score輸出:
0.0353600467617擬合效果遠小於1,可見效果不好。。。
predicts = tempModel.predict('2016/4/21', '2016/4/30', dynamic=True)
print len(predicts)
comp = pd.DataFrame()
comp['original'] = test
comp['predict'] = predicts
comp.plot()效果圖:
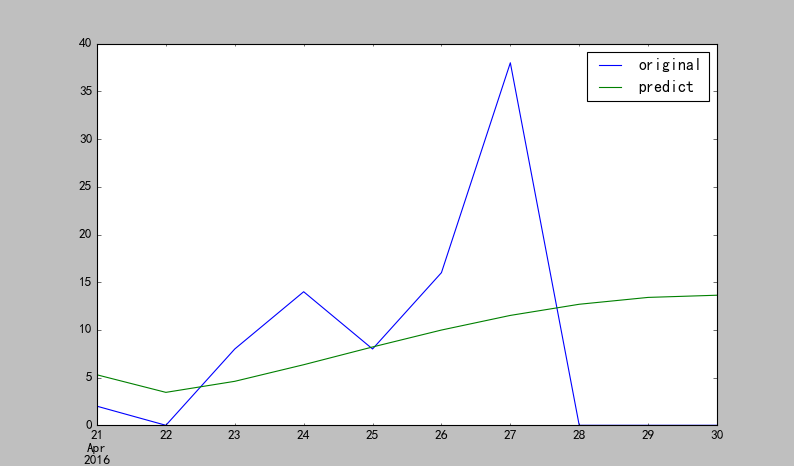
至此,整個流程結束。但是,擬合效果並不好。
總結
導致擬合效果欠佳的原因可能有:
- 使用資料為原始資料,未加任何預處理(主要原因)。原始資料中存在著異常值、不一致、缺失值,嚴重影響了建模的執行效率,造成較大偏差。;
- 在模型定階過程中,為了控制計算量,限制AR最大階不超過6,MA最大階不超過4,從了影響了引數的確定,導致區域性最優。
接下來會從這兩個方面考慮,改進並完善結果。