
Google Dapper 大規模分散式系統的跟蹤方案
這是引用網上翻譯的谷歌在監控方面的重要論文,對於大規模分散式系統的監控和呼叫跟蹤,具有極強的指導意義。現有的很多分散式監控系統,如Spring Cloud 的 Sleuth+Zipkin,就是這種設計的一種實現。
概述
當代的網際網路的服務,通常都是用複雜的、大規模分散式叢集來實現的。網際網路應用構建在不同的軟體模組集上,這些軟體模組,有可能是由不同的團隊開發、可能使用不同的程式語言來實現、有可能布在了幾千臺伺服器,橫跨多個不同的資料中心。因此,就需要一些可以幫助理解系統行為、用於分析效能問題的工具。
Dapper--Google生產環境下的分散式跟蹤系統,應運而生。那麼我們就來介紹一個大規模叢集的跟蹤系統,它是如何滿足一個低損耗、應用透明的、大範圍部署這三個需求的。當然Dapper設計之初,參考了一些其他分散式系統的理念,尤其是Magpie和X-Trace,但是我們之所以能成功應用在生產環境上,還需要一些畫龍點睛之筆,例如取樣率的使用以及把程式碼植入限制在一小部分公共庫的改造上。
1. 介紹
我們開發Dapper是為了收集更多的複雜分散式系統的行為資訊,然後呈現給Google的開發者們。這樣的分散式系統有一個特殊的好處,因為那些大規模的低端伺服器,作為網際網路服務的載體,是一個特殊的經濟划算的平臺。想要在這個上下文中理解分散式系統的行為,就需要監控那些橫跨了不同的應用、不同的伺服器之間的關聯動作。
下面舉一個跟搜尋相關的例子,這個例子闡述了Dapper可以應對哪些挑戰。比如一個前段服務可能對上百臺查詢伺服器發起了一個Web查詢,每一個查詢都有自己的Index。這個查詢可能會被髮送到多個的子系統,這些子系統分別用來處理廣告、進行拼寫檢查或是查詢一些像圖片、視訊或新聞這樣的特殊結果。根據每個子系統的查詢結果進行篩選,得到最終結果,最後彙總到頁面上。我們把這種搜尋模型稱為“全域性搜尋”(universal search)。總的來說,這一次全域性搜尋有可能呼叫上千臺伺服器,涉及各種服務。而且,使用者對搜尋的耗時是很敏感的,而任何一個子系統的低效都導致導致最終的搜尋耗時。如果一個工程師只能知道這個查詢耗時不正常,但是他無從知曉這個問題到底是由哪個服務呼叫造成的,或者為什麼這個呼叫效能差強人意。首先,這個工程師可能無法準確的定位到這次全域性搜尋是呼叫了哪些服務,因為新的服務、乃至服務上的某個片段,都有可能在任何時間上過線或修改過,有可能是面向使用者功能,也有可能是一些例如針對性能或安全認證方面的功能改進。其次,你不能苛求這個工程師對所有參與這次全域性搜尋的服務都瞭如指掌,每一個服務都有可能是由不同的團隊開發或維護的。再次,這些暴露出來的服務或伺服器有可能同時還被其他客戶端使用著,所以這次全域性搜尋的效能問題甚至有可能是由其他應用造成的。舉個例子,一個後臺服務可能要應付各種各樣的請求型別,而一個使用效率很高的儲存系統,比如Bigtable,有可能正被反覆讀寫著,因為上面跑著各種各樣的應用。
上面這個案例中我們可以看到,對Dapper我們只有兩點要求:無所不在的部署,持續的監控。無所不在的重要性不言而喻,因為在使用跟蹤系統的進行監控時,即便只有一小部分沒被監控到,那麼人們對這個系統是不是值得信任都會產生巨大的質疑。另外,監控應該是7x24小時的,畢竟,系統異常或是那些重要的系統行為有可能出現過一次,就很難甚至不太可能重現。那麼,根據這兩個明確的需求,我們可以直接推出三個具體的設計目標:
1.低消耗:跟蹤系統對線上服務的影響應該做到足夠小。在一些高度優化過的服務,即使一點點損耗也會很容易察覺到,而且有可能迫使線上服務的部署團隊不得不將跟蹤系統關停。
2.應用級的透明:對於應用的程式設計師來說,是不需要知道有跟蹤系統這回事的。如果一個跟蹤系統想生效,就必須需要依賴應用的開發者主動配合,那麼這個跟蹤系統也太脆弱了,往往由於跟蹤系統在應用中植入程式碼的bug或疏忽導致應用出問題,這樣才是無法滿足對跟蹤系統“無所不在的部署”這個需求。面對當下想Google這樣的快節奏的開發環境來說,尤其重要。
3.延展性:Google至少在未來幾年的服務和叢集的規模,監控系統都應該能完全把控住。
一個額外的設計目標是為跟蹤資料產生之後,進行分析的速度要快,理想情況是資料存入跟蹤倉庫後一分鐘內就能統計出來。儘管跟蹤系統對一小時前的舊資料進行統計也是相當有價值的,但如果跟蹤系統能提供足夠快的資訊反饋,就可以對生產環境下的異常狀況做出快速反應。
做到真正的應用級別的透明,這應該是當下面臨的最挑戰性的設計目標,我們把核心跟蹤程式碼做的很輕巧,然後把它植入到那些無所不在的公共元件種,比如執行緒呼叫、控制流以及RPC庫。使用自適應的取樣率可以使跟蹤系統變得可伸縮,並降低效能損耗,這些內容將在第4.4節中提及。結果展示的相關係統也需要包含一些用來收集跟蹤資料的程式碼,用來圖形化的工具,以及用來分析大規模跟蹤資料的庫和API。雖然單獨使用Dapper有時就足夠讓開發人員查明異常的來源,但是Dapper的初衷不是要取代所有其他監控的工具。我們發現,Dapper的資料往往側重效能方面的調查,所以其他監控工具也有他們各自的用處。
1.1 文獻的總結
分散式系統跟蹤工具的設計空間已經被一些優秀文章探索過了,其中的Pinpoint[9]、Magpie[3]和X-Trace[12]和Dapper最為相近。這些系統在其發展過程的早期傾向於寫入研究報告中,即便他們還沒來得及清楚地評估系統當中一些設計的重要性。相比之下,由於Dapper已經在大規模生產環境中摸爬滾打了多年,經過這麼多生產環境的驗證之後,我們認為這篇論文最適合重點闡述在部署Dapper的過程中我們有那些收穫,我們的設計思想是如何決定的,以及以什麼樣的方式實現它才會最有用。Dappe作為一個平臺,承載基於Dapper開發的效能分析工具,以及Dapper自身的監測工具,它的價值在於我們可以在回顧評估中找出一些意想不到的結果。
雖然Dapper在許多高階的設計思想上吸取了Pinpoint和Magpie的研究成果,但在分散式跟蹤這個領域中,Dapper的實現包含了許多新的貢獻。例如,我們想實現低損耗的話,特別是在高度優化的而且趨於極端延遲敏感的Web服務中,取樣率是很必要的。或許更令人驚訝的是,我們發現即便是1/1000的取樣率,對於跟蹤資料的通用使用層面上,也可以提供足夠多的資訊。
我們的系統的另一個重要的特徵,就是我們能實現的應用級的透明。我們的元件對應用的侵入被先限制在足夠低的水平上,即使想Google網頁搜尋這麼大規模的分散式系統,也可以直接進行跟蹤而無需加入額外的標註(Annotation)。雖然由於我們的部署系統有幸是一定程度的同質化的,所以更容易做到對應用層的透明這點,但是我們證明了這是實現這種程度的透明性的充分條件。
2. Dapper的分散式跟蹤
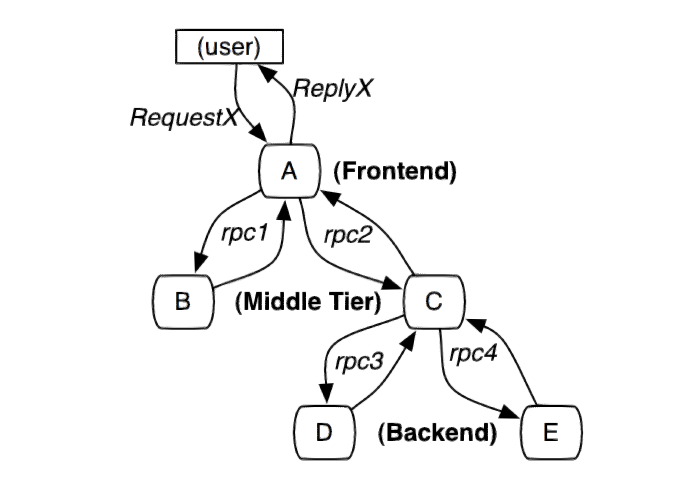
圖1:這個路徑由使用者的X請求發起,穿過一個簡單的服務系統。用字母標識的節點代表分散式系統中的不同處理過程。
分散式服務的跟蹤系統需要記錄在一次特定的請求後系統中完成的所有工作的資訊。舉個例子,圖1展現的是一個和5臺伺服器相關的一個服務,包括:前端(A),兩個中間層(B和C),以及兩個後端(D和E)。當一個使用者(這個用例的發起人)發起一個請求時,首先到達前端,然後傳送兩個RPC到伺服器B和C。B會馬上做出反應,但是C需要和後端的D和E互動之後再返還給A,由A來響應最初的請求。對於這樣一個請求,簡單實用的分散式跟蹤的實現,就是為伺服器上每一次你傳送和接收動作來收集跟蹤識別符號(message identifiers)和時間戳(timestamped events)。
為了將所有記錄條目與一個給定的發起者(例如,圖1中的RequestX)關聯上並記錄所有資訊,現在有兩種解決方案,黑盒(black-box)和基於標註(annotation-based)的監控方案。黑盒方案[1,15,2]假定需要跟蹤的除了上述資訊之外沒有額外的資訊,這樣使用統計迴歸技術來推斷兩者之間的關係。基於標註的方案[3,12,9,16]依賴於應用程式或中介軟體明確地標記一個全域性ID,從而連線每一條記錄和發起者的請求。雖然黑盒方案比標註方案更輕便,他們需要更多的資料,以獲得足夠的精度,因為他們依賴於統計推論。基於標註的方案最主要的缺點是,很明顯,需要程式碼植入。在我們的生產環境中,因為所有的應用程式都使用相同的執行緒模型,控制流和RPC系統,我們發現,可以把程式碼植入限制在一個很小的通用元件庫中,從而實現了監測系統的應用對開發人員是有效地透明。
我們傾向於認為,Dapper的跟蹤架構像是內嵌在RPC呼叫的樹形結構。然而,我們的核心資料模型不只侷限於我們的特定的RPC框架,我們還能跟蹤其他行為,例如Gmail的SMTP會話,外界的HTTP請求,和外部對SQL伺服器的查詢等。從形式上看,我們的Dapper跟蹤模型使用的樹形結構,Span以及Annotation。
2.1 跟蹤樹和span
在Dapper跟蹤樹結構中,樹節點是整個架構的基本單元,而每一個節點又是對span的引用。節點之間的連線表示的span和它的父span直接的關係。雖然span在日誌檔案中只是簡單的代表span的開始和結束時間,他們在整個樹形結構中卻是相對獨立的,任何RPC相關的時間資料、零個或多個特定應用程式的Annotation的相關內容會在2.3節中討論。
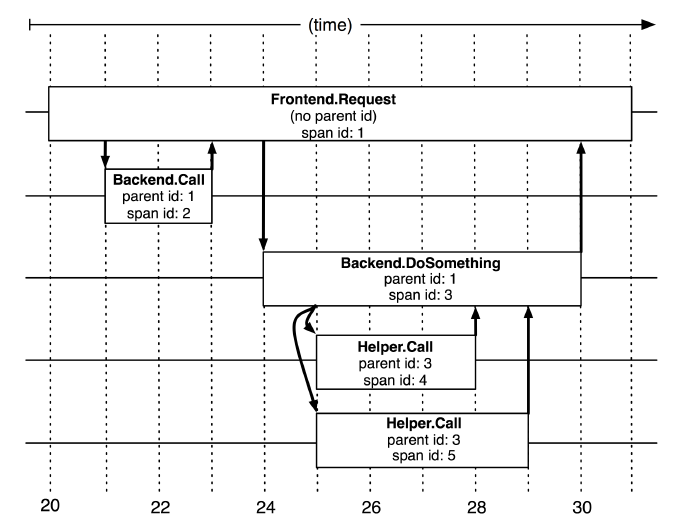
圖2:5個span在Dapper跟蹤樹種短暫的關聯關係
在圖2中說明了span在一個大的跟蹤過程中是什麼樣的。Dapper記錄了span名稱,以及每個span的ID和父ID,以重建在一次追蹤過程中不同span之間的關係。如果一個span沒有父ID被稱為root span。所有span都掛在一個特定的跟蹤上,也共用一個跟蹤id(在圖中未示出)。所有這些ID用全域性唯一的64位整數標示。在一個典型的Dapper跟蹤中,我們希望為每一個RPC對應到一個單一的span上,而且每一個額外的元件層都對應一個跟蹤樹型結構的層級。
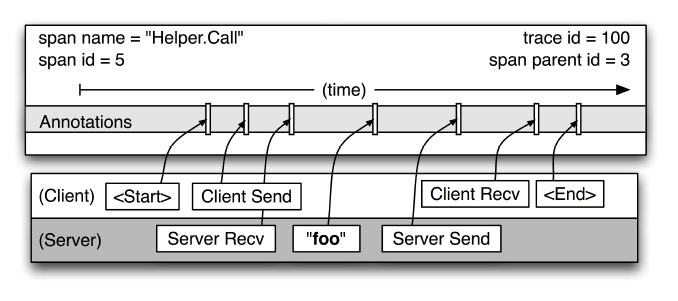
圖3:在圖2中所示的一個單獨的span的細節圖
圖3給出了一個更詳細的典型的Dapper跟蹤span的記錄點的檢視。在圖2中這種某個span表述了兩個“Helper.Call”的RPC(分別為server端和client端)。span的開始時間和結束時間,以及任何RPC的時間資訊都通過Dapper在RPC元件庫的植入記錄下來。如果應用程式開發者選擇在跟蹤中增加他們自己的註釋(如圖中“foo”的註釋)(業務資料),這些資訊也會和其他span資訊一樣記錄下來。
記住,任何一個span可以包含來自不同的主機資訊,這些也要記錄下來。事實上,每一個RPC span可以包含客戶端和伺服器兩個過程的註釋,使得連結兩個主機的span會成為模型中所說的span。由於客戶端和伺服器上的時間戳來自不同的主機,我們必須考慮到時間偏差。在我們的分析工具,我們利用了這個事實:RPC客戶端傳送一個請求之後,伺服器端才能接收到,對於響應也是一樣的(伺服器先響應,然後客戶端才能接收到這個響應)。這樣一來,伺服器端的RPC就有一個時間戳的一個上限和下限。
2.2 植入點
Dapper可以以對應用開發者近乎零浸入的成本對分散式控制路徑進行跟蹤,幾乎完全依賴於基於少量通用元件庫的改造。如下:
- 當一個執行緒在處理跟蹤控制路徑的過程中,Dapper把這次跟蹤的上下文的在ThreadLocal中進行儲存。追蹤上下文是一個小而且容易複製的容器,其中承載了Scan的屬性比如跟蹤ID和span ID。
- 當計算過程是延遲呼叫的或是非同步的,大多數Google開發者通過執行緒池或其他執行器,使用一個通用的控制流庫來回調。Dapper確保所有這樣的回撥可以儲存這次跟蹤的上下文,而當回撥函式被觸發時,這次跟蹤的上下文會與適當的執行緒關聯上。在這種方式下,Dapper可以使用trace ID和span ID來輔助構建非同步呼叫的路徑。
- 幾乎所有的Google的程序間通訊是建立在一個用C++和Java開發的RPC框架上。我們把跟蹤植入該框架來定義RPC中所有的span。span的ID和跟蹤的ID會從客戶端傳送到服務端。像那樣的基於RPC的系統被廣泛使用在Google中,這是一個重要的植入點。當那些非RPC通訊框架發展成熟並找到了自己的使用者群之後,我們會計劃對RPC通訊框架進行植入。
Dapper的跟蹤資料是獨立於語言的,很多在生產環境中的跟蹤結合了用C++和Java寫的程序的資料。在3.2節中,我們討論應用程式的透明度時我們會把這些理論的是如何實踐的進行討論。
2.3 Annotation

上述植入點足夠推匯出複雜的分散式系統的跟蹤細節,使得Dapper的核心功能在不改動Google應用的情況下可用。然而,Dapper還允許應用程式開發人員在Dapper跟蹤的過程中新增額外的資訊,以監控更高級別的系統行為,或幫助除錯問題。我們允許使用者通過一個簡單的API定義帶時間戳的Annotation,核心的示例程式碼入圖4所示。這些Annotation可以新增任意內容。為了保護Dapper的使用者意外的過分熱衷於日誌的記錄,每一個跟蹤span有一個可配置的總Annotation量的上限。但是,應用程式級的Annotation是不能替代用於表示span結構的資訊和記錄著RPC相關的資訊。
除了簡單的文字Annotation,Dapper也支援的key-value對映的 Annotation,提供給開發人員更強的跟蹤能力,如持續的計數器,二進位制訊息記錄和在一個程序上跑著的任意的使用者資料。鍵值對的Annotation方式用來在分散式追蹤的上下文中定義某個特定應用程式的相關型別。
2.4 取樣率
低損耗的是Dapper的一個關鍵的設計目標,因為如果這個工具價值未被證實但又對效能有影響的話,你可以理解服務運營人員為什麼不願意部署它。況且,我們想讓開發人員使用Annotation的API,而不用擔心額外的開銷。我們還發現,某些型別的Web服務對植入帶來的效能損耗確實非常敏感。因此,除了把Dapper的收集工作對基本元件的效能損耗限制的儘可能小之外,我們還有進一步控制損耗的辦法,那就是遇到大量請求時只記錄其中的一小部分。我們將在4.4節中討論跟蹤的取樣率方案的更多細節。
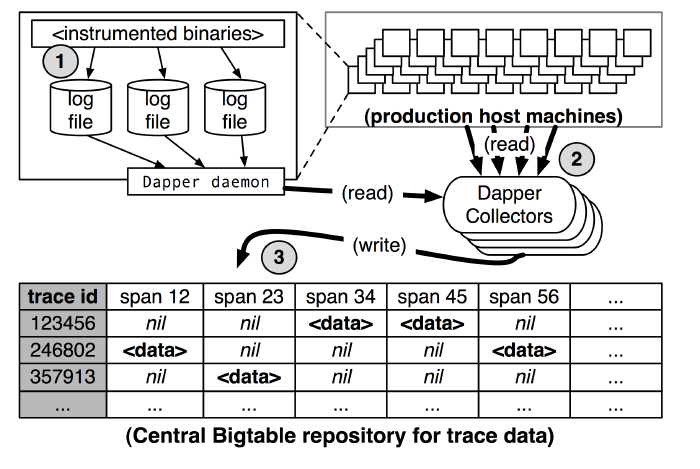
圖5:Dapper收集管道的總覽
2.5 跟蹤的收集
Dapper的跟蹤記錄和收集管道的過程分為三個階段(參見圖5)。首先,span資料寫入(1)本地日誌檔案中。然後Dapper的守護程序和收集元件把這些資料從生產環境的主機中拉出來(2),最終寫到(3)Dapper的Bigtable倉庫中。一次跟蹤被設計成Bigtable中的一行,每一列相當於一個span。Bigtable的支援稀疏表格佈局正適合這種情況,因為每一次跟蹤可以有任意多個span。跟蹤資料收集(即從應用中的二進位制資料傳輸到中央倉庫所花費的時間)的延遲中位數少於15秒。第98百分位的延遲(The 98th percentile latency)往往隨著時間的推移呈現雙峰型;大約75%的時間,第98百分位的延遲時間小於2分鐘,但是另外大約25%的時間,它可以增漲到幾個小時。
Dapper還提供了一個API來簡化訪問我們倉庫中的跟蹤資料。 Google的開發人員用這個API,以構建通用和特定應用程式的分析工具。第5.1節包含更多如何使用它的資訊。
2.5.1 帶外資料跟蹤收集
tip1:帶外資料:傳輸層協議使用帶外資料(out-of-band,OOB)來發送一些重要的資料,如果通訊一方有重要的資料需要通知對方時,協議能夠將這些資料快速地傳送到對方。為了傳送這些資料,協議一般不使用與普通資料相同的通道,而是使用另外的通道。
tip2:這裡指的in-band策略是把跟蹤資料隨著呼叫鏈進行傳送,out-of-band是通過其他的鏈路進行跟蹤資料的收集,Dapper的寫日誌然後進行日誌採集的方式就屬於out-of-band策略
Dapper系統請求樹樹自身進行跟蹤記錄和收集帶外資料。這樣做是為兩個不相關的原因。首先,帶內收集方案--這裡跟蹤資料會以RPC響應頭的形式被返回--會影響應用程式網路動態。在Google裡的許多規模較大的系統中,一次跟蹤成千上萬的span並不少見。然而,RPC迴應大小--甚至是接近大型分散式的跟蹤的根節點的這種情況下-- 仍然是比較小的:通常小於10K。在這種情況下,帶內Dapper的跟蹤資料會讓應用程式資料和傾向於使用後續分析結果的資料量相形見絀。其次,帶內收集方案假定所有的RPC是完美巢狀的。我們發現,在所有的後端的系統返回的最終結果之前,有許多中介軟體會把結果返回給他們的呼叫者。帶內收集系統是無法解釋這種非巢狀的分散式執行模式的。
2.6 安全和隱私考慮
記錄一定量的RPC有效負載資訊將豐富Dapper的跟蹤能力,因為分析工具能夠在有效載荷資料(方法傳遞的引數)中找到相關的樣例,這些樣例可以解釋被監控系統的為何表現異常。然而,有些情況下,有效載荷資料可能包含的一些不應該透露給未經授權使用者(包括正在debug的工程師)的內部資訊。
由於安全和隱私問題是不可忽略的,dapper中的雖然儲存RPC方法的名稱,但在這個時候不記錄任何有效載荷資料。相反,應用程式級別的Annotation提供了一個方便的可選機制:應用程式開發人員可以在span中選擇關聯那些為以後分析提供價值的資料。
Dapper還提供了一些安全上的便利,是它的設計者事先沒有預料到的。通過跟蹤公開的安全協議引數,Dapper可以通過相應級別的認證或加密,來監視應用程式是否滿足安全策略。例如。Dapper還可以提供資訊,以基於策略的的隔離系統按預期執行,例如支撐敏感資料的應用程式不與未經授權的系統元件進行了互動。這樣的測算提供了比原始碼稽核更強大的保障。
3. Dapper部署狀況
Dapper作為我們生產環境下的跟蹤系統已經超過兩年。在本節中,我們會彙報系統狀態,把重點放在Dapper如何滿足了我們的目標——無處不在的部署和應用級的透明。
3.1 Dapper執行庫
也許Dapper程式碼中中最關鍵的部分,就是對基礎RPC、執行緒控制和流程控制的元件庫的植入,其中包括span的建立,取樣率的設定,以及把日誌寫入本地磁碟。除了做到輕量級,植入的程式碼更需要穩定和健壯,因為它與海量的應用對接,維護和bug修復變得困難。植入的核心程式碼是由未超過1000行的C++和不超過800行Java程式碼組成。為了支援鍵值對的Annotation還添加了額外的500行程式碼。
3.2 生產環境下的涵蓋面
Dapper的滲透可以總結為兩個方面:一方面是可以建立Dapper跟蹤的過程(與Dapper植入的元件庫相關),和生產環境下的伺服器上在執行Dapper跟蹤收集守護程序。Dapper的守護程序的分佈相當於我們伺服器的簡單的拓撲圖,它存在於Google幾乎所有的伺服器上。這很難確定精確的Dapper-ready程序部分,因為過程即便不產生跟蹤資訊Dapper也是無從知曉的。儘管如此,考慮到無處不在Dapper元件的植入庫,我們估計幾乎每一個Google的生產程序都是支援跟蹤的。
在某些情況下Dapper的是不能正確的跟蹤控制路徑的。這些通常源於使用非標準的控制流,或是Dapper的錯誤的把路徑關聯歸到不相關的事件上。Dapper提供了一個簡單的庫來幫助開發者手動控制跟蹤傳播作為一種變通方法。目前有40個C++應用程式和33個Java應用程式需要一些手動控制的追蹤傳播,不過這只是上千個的跟蹤中的一小部分。也有非常小的一部分程式使用的非元件性質的通訊庫(比如原生的TCP Socket或SOAP RPC),因此不能直接支援Dapper的跟蹤。但是這些應用可以單獨接入到Dapper中,如果需要的話。
考慮到生產環境的安全,Dapper的跟蹤也可以關閉。事實上,它在部署的早起就是預設關閉的,直到我們對Dapper的穩定性和低損耗有了足夠的信心之後才把它開啟。Dapper的團隊偶爾會執行審查尋找跟蹤配置的變化,來看看那些服務關閉了Dapper的跟蹤。但這種情況不多見,而且通常是源於對監控對效能消耗的擔憂。經過了對實際效能消耗的進一步調查和測量,所有這些關閉Dapper跟蹤都已經恢復開啟了,不過這些已經不重要了。
3.3 跟蹤Annotation的使用
程式設計師傾向於使用特定應用程式的Annotation,無論是作為一種分散式除錯日誌檔案,還是通過一些應用程式特定的功能對跟蹤進行分類。例如,所有的Bigtable的請求會把被訪問的表名也記錄到Annotation中。目前,70%的Dapper span和90%的所有Dapper跟蹤都至少有一個特殊應用的Annotation。
41個Java應用和68個C++應用中都新增自定義的Annotation為了更好地理解應用程式中的span在他們的服務中的行為。值得注意的是,迄今為止我們的Java開發者比C++開發者更多的在每一個跟蹤span上採用Annotation的API。這可能是因為我們的Java應用的作用域往往是更接近終端使用者(C++偏底層);這些型別的應用程式經常處理更廣泛的請求組合,因此具有比較複雜的控制路徑。
4. 處理跟蹤損耗
跟蹤系統的成本由兩部分組成:1.正在被監控的系統在生成追蹤和收集追蹤資料的消耗導致系統性能下降,2。需要使用一部分資源來儲存和分析跟蹤資料。雖然你可以說一個有價值的元件植入跟蹤帶來一部分效能損耗是值得的,我們相信如果基本損耗能達到可以忽略的程度,那麼對跟蹤系統最初的推廣會有極大的幫助。
在本節中,我們會展現一下三個方面:Dapper元件操作的消耗,跟蹤收集的消耗,以及Dapper對生產環境負載的影響。我們還介紹了Dapper可調節的取樣率機制如何幫我們處理低損耗和跟蹤代表性之間的平衡和取捨。
4.1 生成跟蹤的損耗
生成跟蹤的開銷是Dapper效能影響中最關鍵的部分,因為收集和分析可以更容易在緊急情況下被關閉。Dapper執行庫中最重要的跟蹤生成消耗在於建立和銷燬span和annotation,並記錄到本地磁碟供後續的收集。根span的建立和銷燬需要損耗平均204納秒的時間,而同樣的操作在其他span上需要消耗176納秒。時間上的差別主要在於需要在跟span上給這次跟蹤分配一個全域性唯一的ID。
如果一個span沒有被取樣的話,那麼這個額外的span下建立annotation的成本幾乎可以忽略不計,他由在Dapper執行期對ThreadLocal查詢操作構成,這平均只消耗9納秒。如果這個span被計入取樣的話,會用一個用字串進行標註--在圖4中有展現--平均需要消耗40納秒。這些資料都是在2.2GHz的x86伺服器上採集的。
在Dapper執行期寫入到本地磁碟是最昂貴的操作,但是他們的可見損耗大大減少,因為寫入日誌檔案和操作相對於被跟蹤的應用系統來說都是非同步的。不過,日誌寫入的操作如果在大流量的情況,尤其是每一個請求都被跟蹤的情況下就會變得可以察覺到。我們記錄了在4.3節展示了一次Web搜尋的負載下的效能消耗。
4.2 跟蹤收集的消耗
讀出跟蹤資料也會對正在被監控的負載產生干擾。表1展示的是最壞情況下,Dapper收集日誌的守護程序在高於實際情況的負載基準下進行測試時的cpu使用率。在生產環境下,跟蹤資料處理中,這個守護程序從來沒有超過0.3%的單核cpu使用率,而且只有很少量的記憶體使用(以及堆碎片的噪音)。我們還限制了Dapper守護程序為核心scheduler最低的優先順序,以防在一臺高負載的伺服器上發生cpu競爭。
Dapper也是一個頻寬資源的輕量級的消費者,每一個span在我們的倉庫中傳輸只佔用了平均426的byte。作為網路行為中的極小部分,Dapper的資料收集在Google的生產環境中的只佔用了0.01%的網路資源。
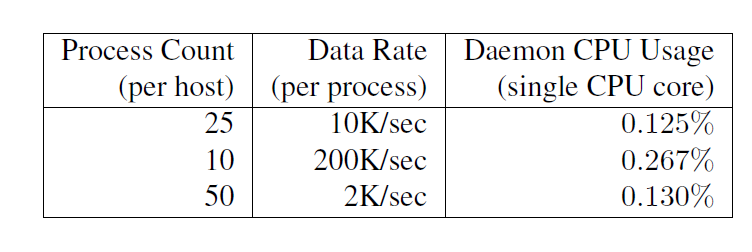
表1:Dapper守護程序在負載測試時的CPU資源使用率
4.3 在生產環境下對負載的影響
每個請求都會利用到大量的伺服器的高吞吐量的線上服務,這是對有效跟蹤最主要的需求之一;這種情況需要生成大量的跟蹤資料,並且他們對效能的影響是最敏感的。在表2中我們用叢集下的網路搜尋服務作為例子,我們通過調整取樣率,來衡量Dapper在延遲和吞吐量方面對效能的影響。
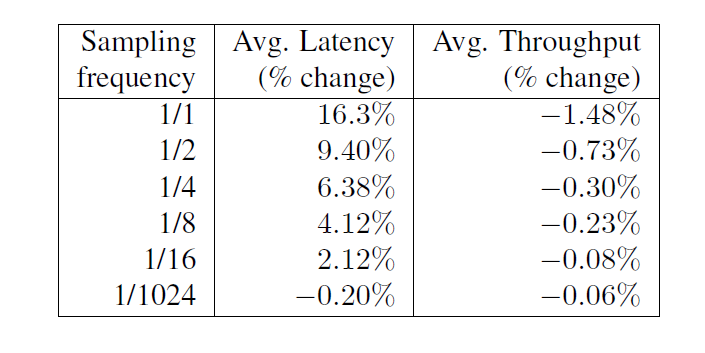
表2:網路搜尋叢集中,對不同取樣率對網路延遲和吞吐的影響。延遲和吞吐的實驗誤差分別是2.5%和0.15%。
我們看到,雖然對吞吐量的影響不是很明顯,但為了避免明顯的延遲,跟蹤的取樣還是必要的。然而,延遲和吞吐量的帶來的損失在把取樣率調整到小於1/16之後就全部在實驗誤差範圍內。在實踐中,我們發現即便取樣率調整到1/1024仍然是有足夠量的跟蹤資料的用來跟蹤大量的服務。保持Dapper的效能損耗基線在一個非常低的水平是很重要的,因為它為那些應用提供了一個寬鬆的環境使用完整的Annotation API而無懼效能損失。使用較低的取樣率還有額外的好處,可以讓持久化到硬碟中的跟蹤資料在垃圾回收機制處理之前保留更長的時間,這樣為Dapper的收集元件給了更多的靈活性。
4.4 可變取樣
任何給定程序的Dapper的消耗和每個程序單位時間的跟蹤的取樣率成正比。Dapper的第一個生產版本在Google內部的所有程序上使用統一的取樣率,為1/1024。這個簡單的方案是對我們的高吞吐量的線上服務來說是非常有用,因為那些感興趣的事件(在大吞吐量的情況下)仍然很有可能經常出現,並且通常足以被捕捉到。
然而,在較低的取樣率和較低的傳輸負載下可能會導致錯過重要事件,而想用較高的取樣率就需要能接受的效能損耗。對於這樣的系統的解決方案就是覆蓋預設的取樣率,這需要手動干預的,這種情況是我們試圖避免在dapper中出現的。
我們在部署可變取樣的過程中,引數化配置取樣率時,不是使用一個統一的取樣方案,而是使用一個取樣期望率來標識單位時間內取樣的追蹤。這樣一來,低流量低負載自動提高取樣率,而在高流量高負載的情況下會降低取樣率,使損耗一直保持在控制之下。實際使用的取樣率會隨著跟蹤本身記錄下來,這有利於從Dapper的跟蹤資料中準確的分析。
4.5 應對積極取樣(Coping with aggressive sampling)
新的Dapper使用者往往覺得低取樣率--在高吞吐量的服務下經常低至0.01%--將會不利於他們的分析。我們在Google的經驗使我們相信,對於高吞吐量服務,積極取樣(aggressive sampling)並不妨礙最重要的分析。如果一個顯著的操作在系統中出現一次,他就會出現上千次。低吞吐量的服務--也許是每秒請求幾十次,而不是幾十萬--可以負擔得起跟蹤每一個請求,這是促使我們下決心使用自適應取樣率的原因。
4.6 在收集過程中額外的取樣
上述取樣機制被設計為儘量減少與Dapper執行庫協作的應用程式中明顯的效能損耗。Dapper的團隊還需要控制寫入中央資料庫的資料的總規模,因此為達到這個目的,我們結合了二級取樣。
目前我們的生產叢集每天產生超過1TB的取樣跟蹤資料。Dapper的使用者希望生產環境下的程序的跟蹤資料從被記錄之後能儲存至少兩週的時間。逐漸增長的追蹤資料的密度必須和Dapper中央倉庫所消耗的伺服器及硬碟儲存進行權衡。對請求的高取樣率還使得Dapper收集器接近寫入吞吐量的上限。
為了維持物質資源的需求和漸增的Bigtable的吞吐之間的靈活性,我們在收集系統自身上增加了額外的取樣率的支援。我們充分利用所有span都來自一個特定的跟蹤並分享同一個跟蹤ID這個事實,雖然這些span有可能橫跨了數千個主機。對於在收集系統中的每一個span,我們用hash演算法把跟蹤ID轉成一個標量Z,這裡0<=Z<=1。如果Z比我們收集系統中的係數低的話,我們就保留這個span資訊,並寫入到Bigtable中。反之,我們就拋棄他。通過在取樣決策中的跟蹤ID,我們要麼儲存、要麼拋棄整個跟蹤,而不是單獨處理跟蹤內的span。我們發現,有了這個額外的配置引數使管理我們的收集管道變得簡單多了,因為我們可以很容易地在配置檔案中調整我們的全域性寫入率這個引數。
如果整個跟蹤過程和收集系統只使用一個取樣率引數確實會簡單一些,但是這就不能應對快速調整在所有部署的節點上的執行期取樣率配置的這個要求。我們選擇了執行期取樣率,這樣就可以優雅的去掉我們無法寫入到倉庫中的多餘資料,我們還可以通過調節收集系統中的二級取樣率係數來調整這個執行期取樣率。Dapper的管道維護變得更容易,因為我們就可以通過修改我們的二級取樣率的配置,直接增加或減少我們的全域性覆蓋率和寫入速度。
5. 通用的Dapper工具
幾年前,當Dapper還只是個原型的時候,它只能在Dapper開發者耐心的支援下使用。從那時起,我們逐漸迭代的建立了收集元件,程式設計介面,和基於Web的互動式使用者介面,幫助Dapper的使用者獨立解決自己的問題。在本節中,我們會總結一下哪些的方法有用,哪些用處不大,我們還提供關於這些通用的分析工具的基本的使用資訊。
5.1 Dapper Depot API
Dapper的“Depot API”或稱作DAPI,提供在Dapper的區域倉庫中對分散式跟蹤資料一個直接訪問。DAPI和Dapper跟蹤倉庫被設計成串聯的,而且DAPI意味著對Dapper倉庫中的元資料暴露一個乾淨和直觀的的介面。我們使用了以下推薦的三種方式去暴露這樣的介面:
- 通過跟蹤ID來訪問:DAPI可以通過他的全域性唯一的跟蹤ID讀取任何一次跟蹤資訊。
- 批量訪問:DAPI可以利用的MapReduce提供對上億條Dapper跟蹤資料的並行讀取。使用者重寫一個虛擬函式,它接受一個Dapper的跟蹤資訊作為其唯一的引數,該框架將在使用者指定的時間視窗中呼叫每一次收集到的跟蹤資訊。
- 索引訪問:Dapper的倉庫支援一個符合我們通用呼叫模板的唯一索引。該索引根據通用請求跟蹤特性(commonly-requested trace features)進行繪製來識別Dapper的跟蹤資訊。因為跟蹤ID是根據偽隨機的規則建立的,這是最好的辦法去訪問跟某個服務或主機相關的跟蹤資料。
所有這三種訪問模式把使用者指向不同的Dapper跟蹤記錄。正如第2.1節所述的,Dapper的由span組成的跟蹤資料是用樹形結構建模的,因此,跟蹤資料的資料結構,也是一個簡單的由span組成遍歷樹。Span就相當於RPC呼叫,在這種情況下,RPC的時間資訊是可用的。帶時間戳的特殊的應用標註也是可以通過這個span結構來訪問的。
選擇一個合適的自定義索引是DAPI設計中最具挑戰性的部分。壓縮儲存要求在跟蹤資料種建立一個索引的情況只比實際資料小26%,所以消耗是巨大的。最初,我們部署了兩個索引:第一個是主機索引,另一個是服務名的索引。然而,我們並沒有找到主機索引和儲存成本之間的利害關係。當用戶對每一臺主機感興趣的時候,他們也會對特定的服務感興趣,所以我們最終選擇把兩者相結合,成為一個組合索引,它允許以服務名稱,主機,和時間戳的順序進行有效的查詢。
5.1.1 DAPI在Google內部的使用
DAPI在谷歌的使用有三類:使利用DAPI的持續的線上Web應用,維護良好的可以在控制檯上呼叫的基於DAPI的工具,可以被寫入,執行、不過大部分已經被忘記了的一次性分析工具。我們知道的有3個永續性的基於DAPI的應用程式,8個額外的按需定製的基於DAPI分析工具,以及使用DAPI框架構建的約15~20一次性的分析工具。在這之後的工具就這是很難說明了,因為開發者可以構建、執行和丟棄這些專案,而不需要Dapper團隊的技術支援。
5.2 Dapper的使用者介面
絕大多數使用者使用發生在基於web的使用者互動介面。篇幅有限,我們不能列出每一個特點,而只能把典型的使用者工作流在圖6中展示。
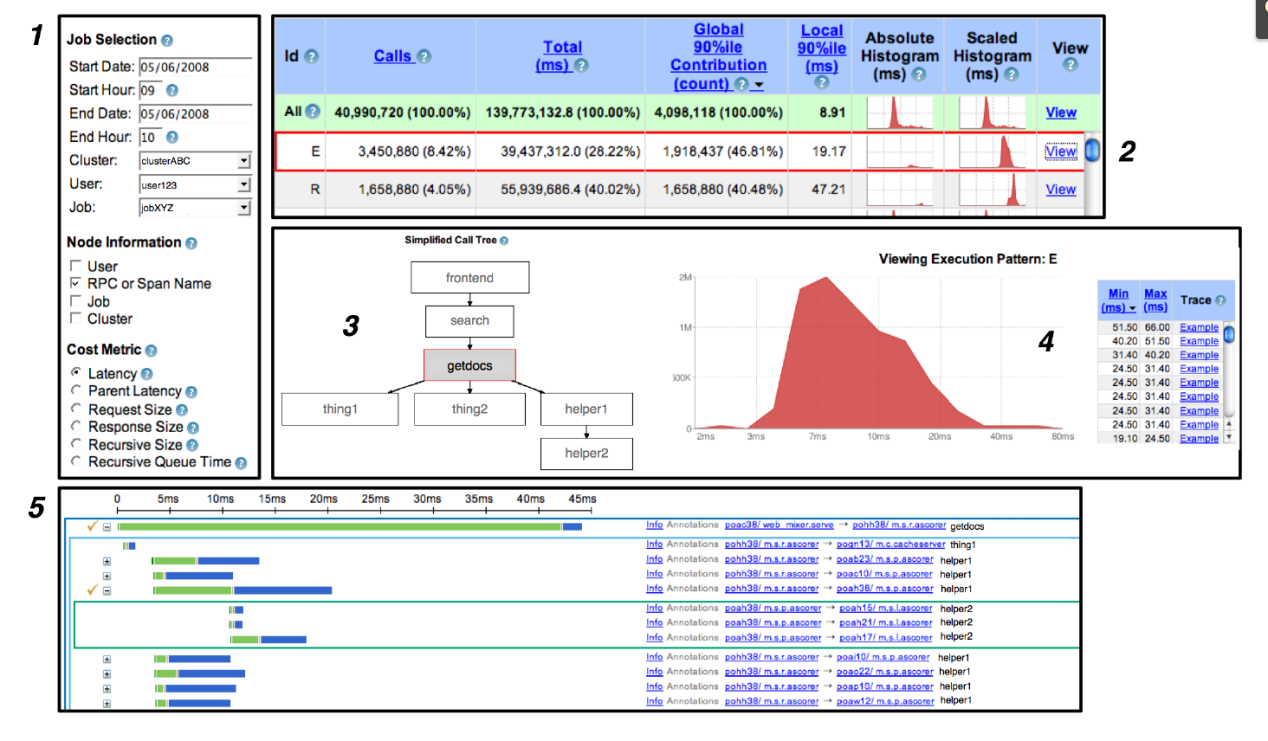
圖6
- 使用者描述的他們關心的服務和時間,和其他任何他們可以用來區分跟蹤模板的資訊(比如,span的名稱)。他們還可以指定與他們的搜尋最相關的成本度量(cost metric)(比如,服務響應時間)。
- 一個關於效能概要的大表格,對應確定的服務關聯的所有分散式處理圖表。使用者可以把這些執行圖示排序成他們想要的,並選擇一種直方圖去展現出更多的細節。
- 一旦某個單一的分散式執行部分被選中後,使用者能看到關於執行部分的的圖形化描述。被選中的服務被高亮展示在該圖的中心。
- 在生成與步驟1中選中的成本度量(cost metric)維度相關的統計資訊之後,Dapper的使用者介面會提供了一個簡單的直方圖。在這個例子中,我們可以看到一個大致的所選中部分的分散式響應時間分佈圖。使用者還會看到一個關於具體的跟蹤資訊的列表,展現跟蹤資訊在直方圖中被劃分為的不同區域。在這個例子中,使用者點選列表種第二個跟蹤資訊例項時,會在下方看到這個跟蹤資訊的詳細檢視(步驟5)。
- 絕大多數Dapper的使用者最終的會檢查某個跟蹤的情況,希望能收集一些資訊去了解系統行為的根源所在。我們沒有足夠的空間來做跟蹤檢視的審查,但我們使用由一個全域性時間軸(在上方可以看到),並能夠展開和摺疊樹形結構的互動方式,這也很有特點。分散式跟蹤樹的連續層用內嵌的不同顏色的矩形表示。每一個RPC的span被從時間上分解為一個伺服器程序中的消耗(綠色部分)和在網路上的消耗(藍色部分)。使用者Annotation沒有顯示在這個截圖中,但他們可以選擇性的以span的形式包含在全域性時間軸上。
為了讓使用者查詢實時資料,Dapper的使用者介面能夠直接與Dapper每一臺生產環境下的伺服器上的守護程序進行互動。在該模式下,不可能指望能看到上面所說的系統級的圖表展示,但仍然可以很容易基於效能和網路特性選取一個特定的跟蹤。在這種模式下,可在幾秒鐘內查到實時的資料。
根據我們的記錄,大約有200個不同的Google工程師在一天內使用的Dapper的UI;在一週的過程中,大約有750-1000不同的使用者。這些使用者數,在新功能的內部通告上,是按月連續的。通常使用者會發送特定跟蹤的連線,這將不可避免地在查詢跟蹤情況時中產生很多一次性的,持續時間較短的互動。
6. 經驗
Dapper在Google被廣泛應用,一部分直接通過Dapper的使用者介面,另一部分間接地通過對Dapper API的二次開發或者建立在基於api的應用上。在本節中,我們並不打算羅列出每一種已知的Dapper使用方式,而是試圖覆蓋Dapper使用方式的“基本向量”,並努力來說明什麼樣的應用是最成功的。
6.1 在開發中使用Dapper
Google AdWords系統是圍繞一個大型的關鍵詞定位準則和相關文字廣告的資料庫搭建的。當新的關鍵字或廣告被插入或修改時,它們必須通過服務策略術語的檢查(如檢查不恰當的語言,這個過程如果使用自動複查系統來做的話會更加有效)。
當輪到從頭重新設計一個廣告審查服務時,這個團隊迭代的從第一個系統原型開始使用Dapper,並且,最終用Dapper一直維護著他們的系統。Dapper幫助他們從以下幾個方面改進了他們的服務:
- 效能:開發人員針對請求延遲的目標進行跟蹤,並對容易優化的地方進行定位。Dapper也被用來確定在關鍵路徑上不必要的序列請求--通常來源於不是開發者自己開發的子系統--並促使團隊持續修復他們。
- 正確性:廣告審查服務圍繞大型資料庫系統搭建。系統同時具有隻讀副本策略(資料訪問廉價)和讀寫的主策略(訪問代價高)。Dapper被用來在很多種情況中確定,哪些查詢是無需通過主策略訪問而可以採用副本策略訪問。Dapper現在可以負責監控哪些主策略被直接訪問,並對重要的系統常量進行保障。
- 理解性:廣告審查查詢跨越了各種型別的系統,包括BigTable—之前提到的那個資料庫,多維索引服務,以及其他各種C++和Java後端服務。Dapper的跟蹤用來評估總查詢成本,促進重新對業務的設計,用以在他們的系統依賴上減少負載。
- 測試:新的程式碼版本會經過一個使用Dapper進行跟蹤的QA過程,用來驗證正確的系統行為和效能。在跑測試的過程中能發現很多問題,這些問題來自廣告審查系統自身的程式碼或是他的依賴包。
廣告審查團隊廣泛使用了Dapper Annotation API。Guice[13]開源的AOP框架用來在重要的軟體元件上標註“@Traced”。這些跟蹤資訊可以進一步被標註,包含:重要子路徑的輸入輸出大小、基礎資訊、其他除錯資訊,所有這些資訊將會額外發送到日誌檔案中。
同時,我們也發現了一些廣告審查小組在使用方面的不足。比如:他們想根據他們所有跟蹤的Annotation資訊,在一個互動時間段內進行搜尋,然而這就必須跑一個自定義的MapReduce或進行每一個跟蹤的手動檢查。另外,在Google還有一些其他的系統在也從通用除錯日誌中收集和集中資訊,把那些系統的海量資料和Dapper倉庫整合也是有價值的。
總的來說,即便如此,廣告審查團隊仍然對Dapper的作用進行了以下評估,通過使用Dapper的跟蹤平臺的資料分析,他們的服務延遲性已經優化了兩個數量級。
6.1.1 與異常監控的整合
Google維護了一個從執行程序中不斷收集並集中異常資訊報告的服務。如果這些異常發生在Dapper跟蹤取樣的上下文中,那麼相應的跟蹤ID和span的ID也會作為元資料記錄在異常報告中。異常監測服務的前端會提供一個連結,從特定的異常資訊的報告直接導向到他們各自的分散式跟蹤。廣告審查團隊使用這個功能可以瞭解bug發生的更大範圍的上下文。通過暴露基於簡單的唯一ID構建的介面,Dapper平臺被整合到其他事件監測系統會相對容易。
6.2 解決延遲的長尾效應
考慮到移動部件的數量、程式碼庫的規模、部署的範圍,除錯一個像全文搜尋那樣服務(第1節裡提到過)是非常具有挑戰性的。在這節,我們描述了我們在減輕全文搜尋的延遲分佈的長尾效應上做的各種努力。Dapper能夠驗證端到端的延遲的假設,更具體地說,Dapper能夠驗證對於搜尋請求的關鍵路徑。當一個系統不僅涉及數個子系統,而是幾十個開發團隊的涉及到的系統的情況下,端到端效能較差的根本原因到底在哪,這個問題即使是我們最好的和最有經驗的工程師也無法正確回答。在這種情況下,Dapper可以提供急需的資料,而且可以對許多重要的效能問題得出結論。
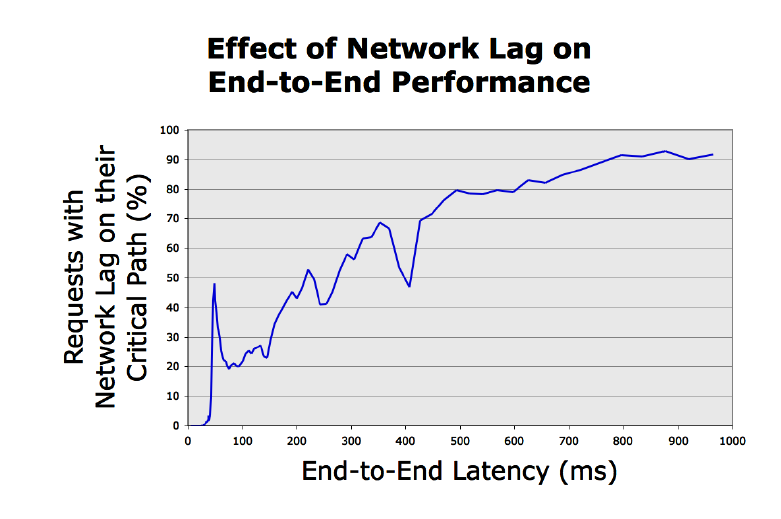
圖7:全域性搜尋的跟蹤片段,在不常遇到高網路延遲的情況下,在沿著關鍵路徑的端到端的請求延遲,如圖所示。
在除錯延遲長尾效應的過程中,工程師可以建立一個小型庫,這個小型庫可以根據DAPI跟蹤物件來推斷關鍵路徑的層級結構。這些關鍵路徑的結構可以被用來診斷問題,並且為全文搜尋提供可優先處理的預期的效能改進。Dapper的這項工作導致了下列發現:
- 在關鍵路徑上的短暫的網路效能退化不影響系統的吞吐量,但它可能會對延遲異常值產生極大的影響。在圖7中可以看出,大部分的全域性搜尋的緩慢的跟蹤都來源於關鍵路徑的網路效能退化。
- 許多問題和代價很高的查詢模式來源於一些意想不到的服務之間的互動。一旦發現,往往容易糾正它們,但是Dapper出現之前想找出這些問題是相當困難的。
- 通用的查詢從Dapper之外的安全日誌倉庫中收取,並使用Dapper唯一的跟蹤ID,與Dapper的倉庫做關聯。然後,該對映用來建立關於在全域性搜尋中的每一個獨立子系統都很慢的例項查詢的列表。
6.3 推斷服務依賴
在任何給定的時間內,Google內部的一個典型的計算叢集是一個彙集了成千上萬個邏輯“任務”的主機,一套的處理器在執行一個通用的方法。Google維護著許多這樣的叢集,當然,事實上,我們發現在一個叢集上計算著的這些任務通常依賴於其他的叢集上的任務。由於任務們之間的依賴是動態改變的,所以不可能僅從配置資訊上推斷出所有這些服務之間的依賴關係。不過,除了其他方面的原因之外,在公司內部的各個流程需要準確的服務依賴關係資訊,以確定瓶頸所在,以及計劃服務的遷移。Google的可稱為“Service Dependencies”的專案是通過使用跟蹤Annotation和DAPI MapReduce介面來實現自動化確定服務依賴歸屬的。
Dapper核心元件與Dapper跟蹤Annotation一併使用的情況下,“Service Dependencies”專案能夠推算出任務各自之間的依賴,以及任務和其他軟體元件之間的依賴。比如,所有的BigTable的操作會加上與受影響的表名稱相關的標記。運用Dapper的平臺,Service Dependencies團隊就可以自動的推算出依賴於命名的不同資源的服務粒度。
6.4 不同服務的網路使用率
Google投入了大量的人力和物力資源在他的網路結構上。從前網路管理員可能只關注獨立的硬體資訊、常用工具及以及搭建出的各種全域性網路鳥瞰圖的dashboard上的資訊。網路管理員確實可以一覽整個網路的健康狀況,但是,當遇到問題時,他們很少有能夠準確查詢網路負載的工具,用來定位應用程式級別的罪魁禍首。
雖然Dapper不是設計用來做鏈路級的監控的,但是我們發現,它是非常適合去做叢集之間網路活動性的應用級任務的分析。Google能夠利用Dapper這個平臺,建立一個不斷更新的控制檯,來顯示叢集之間最活躍的網路流量的應用級的熱點。此外,使用Dapper我們能夠為昂貴的網路請求提供指出的構成原因的跟蹤,而不是面對不同伺服器之間的資訊孤島而無所適從。建立一個基於Dapper API的dashboard總共沒花超過2周的時間。
6.5 分層和共享儲存系統
在Google的許多儲存系統是由多重獨立複雜層級的分散式基礎裝置組成的。例如,Google的App Engine[5]就是搭建在一個可擴充套件的實體儲存系統上的。該實體儲存系統在基於BigTable上公開某些RDBMS功能。 BigTable的同時使用Chubby[7](分散式鎖系統)及GFS。再者,像BigTable這樣的系統簡化了部署,並更好的利用了計算資源。
在這種分層的系統,並不總是很容易確定終端使用者資源的消費模式。例如,來自於一個給定的BigTable單元格的GFS大資訊量主要來自於一個使用者或是由多個使用者產生,但是在GFS層面,這兩種明顯的使用場景是很難界定。而且,如果缺乏一個像Dapper一樣的工具的情況下,對共享服務的競爭可能會同樣難於除錯。
第5.2節中所示的Dapper的使用者介面可以聚合那些呼叫任意公共服務的多個客戶端的跟蹤的效能資訊。這就很容易讓提供這些服務的源從多個維度給他們的使用者排名。(例如,入站的網路負載,出站的網路負載,或服務請求的總時間)
6.6 Dapper的救火能力(Firefighting)
對於一些“救火”任務,Dapper可以處理其中的一部分。“救火”任務在這裡是指一些有風險很高的在分散式系統上的操作。通常情況下,Dapper使用者當正在進行“救火”任務時需要使用新的資料,並且沒有時間寫新的DAPI程式碼或等待週期性的報告執行。
對於那些高延遲,不,可能更糟糕的那些在正常負載下都會響應超時的服務,Dapper使用者介面通常會把這些延遲瓶頸的位置隔離出來。通過與Dapper守護程序的直接通訊,那些特定的高延遲的跟蹤資料輕易的收集到。當出現災難性故障時,通常是沒有必要去看統計資料以確定根本原因,只檢視示例跟蹤就足夠了(因為前文提到過從Dapper守護程序中幾乎可以立即獲得跟蹤資料)。
但是,如在6.5節中描述的共享的儲存服務,要求當用戶活動過程中突然中斷時能儘可能快的彙總資訊。對於事件發生之後,共享服務仍然可以利用匯總的的Dapper資料,但是,除非收集到的Dapper資料的批量分析能在問題出現10分鐘之內完成,否則Dapper面對與共享儲存服務相關的“救火”任務就很難按預想的那般順利完成。
7. 其他收穫
雖然迄今為止,我們在Dapper上的經驗已經大致符合我們的預期,但是也出現了一些積極的方面是我們沒有充分預料到的。首先,我們獲得了超出預期的Dapper使用用例的數量,對此我們可謂歡心鼓舞。另外,在除了幾個的在第6節使用經驗中提到過的一些用例之外,還包括資源核算系統,對指定的通訊模式敏感的服務的檢查工具,以及一種對RPC壓縮策略的分析器,等等。我們認為這些意想不到的用例一定程度上是由於我們向開發者以一種簡單的程式設計介面的方式開放了跟蹤資料儲存的緣故,這使得我們能夠充分利用這個大的多的社群的創造力。除此之外,Dapper對舊的負載的支援也比預期的要簡單,只需要在程式中引入一個用新版本的重新編譯過的公共元件庫(包含常規的執行緒使用,控制流和RPC框架)即可。
Dapper在Google內部的廣泛使用還為我們在Dapper的侷限性上提供了寶貴的反饋意見。下面我們將介紹一些我們已知的最重要的Dapper的不足:
- 合併的影響:我們的模型隱含的前提是不同的子系統在處理的都是來自同一個被跟蹤的請求。在某些情況下,緩衝一部分請求,然後一次性操作一個請求集會更加有效。(比如,磁碟上的一次合併寫入操作)。在這種情況下,一個被跟蹤的請求可以看似是一個大型工作單元。此外,當有多個追蹤請求被收集在一起,他們當中只有一個會用來生成那個唯一的跟蹤ID,用來給其他span使用,所以就無法跟蹤下去了。我們正在考慮的解決方案,希望在可以識別這種情況的前提下,用盡可能少的記錄來解決這個問題。
- 跟蹤批處理負載:Dapper的設計,主要是針對線上服務系統,最初的目標是瞭解一個使用者請求產生的系統行為。然而,離線的密集型負載,例如符合MapReduce[10]模型的情況,也可以受益於效能挖潛。在這種情況下,我們需要把跟蹤ID與一些其他的有意義的工作單元做關聯,諸如輸入資料中的鍵值(或鍵值的範圍),或是一個MapReduce shard。
- 尋找根源:Dapper可以有效地確定系統中的哪一部分致使系統整個速度變慢,但並不總是能夠找出問題的根源。例如,一個請求很慢有可能不是因為它自己的行為,而是由於佇列中其他排在它前面的(queued ahead of)請求還沒處理完。程式可以使用應用級的annotation把佇列的大小或過載情況寫入跟蹤系統。此外,如果這種情況屢見不鮮,那麼在ProfileMe[11]中提到的成對的取樣技術可以解決這個問題。它由兩個時間重疊的取樣率組成,並觀察它們在整個系統中的相對延遲。
- 記錄核心級的資訊:一些核心可見的事件的詳細資訊有時對確定問題根源是很有用的。我們有一些工具,能夠跟蹤或以其他方式描述核心的執行,但是,想用通用的或是不那麼突兀的方式,是很難把這些資訊到捆綁到使用者級別的跟蹤上下文中。我們正在研究一種妥協的解決方案,我們在使用者層面上把一些核心級的活動引數做快照,然後繫結他們到一個活動的span上。
8. 相關產品
在分散式系統跟蹤領域,有一套完整的體系,一部分系統主要關注定位到故障位置,其他的目標是針對性能進行優化。 Dapper確實被用於發現系統問題,但它更通常用於探查效能不足,以及提高全面大規模的工作負載下的系統行為的理解。
與Dapper相關的黑盒監控系統,比如Project5[1],WAP5[15]和Sherlock[2],可以說不依賴執行庫的情況下,黑盒監控系統能夠實現更高的應用級透明。黑盒的缺點是一定程度上不夠精確,並可能在統計推斷關鍵路徑時帶來更大的系統損耗。
對於分散式系統監控來說,基於Annotation的中介軟體或應用自身是一個可能是更受歡迎的解決辦法.拿Pip[14]和Webmon[16]系統舉例,他們更依賴於應用級的Annotation,而X-Trace[12],Pinpoint[9]和Magpie[3]大多集中在對庫和中介軟體的修改。Dapper更接近後者。像Pinpoint,X-Trace,和早期版本的Magpie一樣,Dapper採用了全域性識別符號把分散式系統中各部分相關的事件聯絡在一起。和這些系統類似,Dapper嘗試避免使用應用級Annotation,而是把的植入隱藏在通用元件模組內。Magpie放棄使用全域性ID,仍然試圖正確的完成請求的正確傳播,他通過採用應用系統各自寫入的事件策略,最終也能精確描述不同事件之間關係。但是目前還不清楚Magpie在實際環境中實現透明性這些策略到底多麼有效。 X-Trace的核心Annotation比Dapper更有野心一些,因為X-Trace系統對於跟蹤的收集,不僅在跟蹤節點層面上,而且在節點內部不同的軟體層也會進行跟蹤。而我們對於元件的低效能損耗的要求迫使我們不能採用X-Trace這樣的模型,而是朝著把一個請求連線起來完整跟蹤所能做到的最小代價而努力。而Dapper的跟蹤仍然可以從可選的應用級Annotation中獲益。
9. 總結
在本文中,我們介紹Dapper這個Google的生產環境下的分散式系統跟蹤平臺,並彙報了我們開發和使用它的相關經驗。 Dapper幾乎在部署在所有的Google系統上,並可以在不需要應用級修改的情況下進行跟蹤,而且沒有明顯的效能影響。Dapper對於開發人員和運維團隊帶來的好處,可以從我們主要的跟蹤使用者介面的廣泛使用上看出來,另外我們還列舉了一些Dapper的使用用例來說明Dapper的作用,這些用例有些甚至都沒有Dapper開發團隊參與,而是被應用的開發者開發出來的。
據我們所知,這是第一篇彙報生產環境下分散式系統跟蹤框架的論文。事實上,我們的主要貢獻源於這個事實:論文中回顧的這個系統已經執行兩年之久。我們發現,結合對開發人員提供簡單API和對應用系統完全透明來增強跟蹤的這個決定,是非常值得的。
我們相信,Dapper比以前的基於Annotation的分散式跟蹤達到更高的應用透明度,這一點已經通過只需要少量人工干預的工作量得以證明。雖然一定程度上得益於我們的系統的同質性,但它本身仍然是一個重大的挑戰。最重要的是,我們的設計提出了一些實現應用級透明性的充分條件,對此我們希望能夠對更錯雜環境下的解決方案的開發有所幫助。
最後,通過開放Dapper跟蹤倉庫給內部開發者,我們促使更多的基於跟蹤倉庫的分析工具的產生,而僅僅由Dapper團隊默默的在資訊孤島中埋頭苦幹的結果遠達不到現在這麼大的規模,這個決定促使了設計和實施的展開。
Acknowledgments
We thank Mahesh Palekar, Cliff Biffle, Thomas Kotzmann, Kevin Gibbs, Yonatan Zunger, Michael Kleber, and Toby Smith for their experimental data and feedback about Dapper experiences. We also thank Silvius Rus for his assistance with load testing. Most importantly, though, we thank the outstanding team of engineers who have continued to develop and improve Dapper over the years; in order of appearance, Sharon Perl, Dick Sites, Rob von Behren, Tony DeWitt, Don Pazel, Ofer Zajicek, Anthony Zana, Hyang-Ah Kim, Joshua MacDonald, Dan Sturman, Glenn Willen, Alex Kehlenbeck, Brian McBarron, Michael Kleber, Chris Povirk, Bradley White, Toby Smith, Todd Derr, Michael De Rosa, and Athicha Muthitacharoen. They have all done a tremendous amount of work to make Dapper a day-to-day reality at Google.
References
[1] M. K. Aguilera, J. C. Mogul, J. L. Wiener, P. Reynolds, and A. Muthitacharoen. Performance Debugging for Distributed Systems of Black Boxes. In Proceedings of the 19th ACM Symposium on Operating Systems Principles, December 2003.
[2] P. Bahl, R. Chandra, A. Greenberg, S. Kandula, D. A. Maltz, and M. Zhang. Towards Highly Reliable Enterprise Network Services Via Inference of Multi-level Dependencies. In Proceedings of SIGCOMM, 2007.
[3] P. Barham, R. Isaacs, R. Mortier, and D. Narayanan. Magpie: online modelling and performance-aware systems. In Proceedings of USENIX HotOS IX, 2003.
[4] L. A. Barroso, J. Dean, and U. Holzle. Web Search for a Planet: The Google Cluster Architecture. IEEE Micro, 23(2):22–28, March/April 2003.
[5] T. O. G. Blog. Developers, start your engines. http://googleblog.blogspot.com/2008/04/developers-start-your-engines.html,2007.
[6] T. O. G. Blog. Universal search: The best answer is still the best answer. http://googleblog.blogspot.com/2007/05/universal-search-best-answer-is-still.html, 2007.
[7] M. Burrows. The Chubby lock service for loosely-coupled distributed systems. In Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation, pages 335 – 350, 2006.
[8] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: A Distributed Storage System for Structured Data. In Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI’06), November 2006.
[9] M. Y. Chen, E. Kiciman, E. Fratkin, A. fox, and E. Brewer. Pinpoint: Problem Determination in Large, Dynamic Internet Services. In Proceedings of ACM International Conference on Dependable Systems and Networks, 2002.
[10] J. Dean and S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. In Proceedings of the 6th USENIX Symposium on Operating Systems Design and Implementation (OSDI’04), pages 137 – 150, December 2004.
[11] J. Dean, J. E. Hicks, C. A. Waldspurger, W. E. Weihl, and G. Chrysos. ProfileMe: Hardware Support for Instruction-Level Profiling on Out-of-Order Processors. In Proceedings of the IEEE/ACM International Symposium on Microarchitecture, 1997.
[12] R. Fonseca, G. Porter, R. H. Katz, S. Shenker, and I. Stoica. X-Trace: A Pervasive Network Tracing Framework. In Proceedings of USENIX NSDI, 2007.
[13] B. Lee and K. Bourrillion. The Guice Project Home Page. http://code.google.com/p/google-guice/, 2007.
[14] P. Reynolds, C. Killian, J. L. Wiener, J. C. Mogul, M. A. Shah, and A. Vahdat. Pip: Detecting the Unexpected in Distributed Systems. In Proceedings of USENIX NSDI, 2006.
[15] P. Reynolds, J. L. Wiener, J. C. Mogul, M. K. Aguilera, and A. Vahdat. WAP5: Black Box Performance Debugging for Wide-Area Systems. In Proceedings of the 15th International World Wide Web Conference, 2006.
[16] P. K. G. T. Gschwind, K. Eshghi and K. Wurster. WebMon: A Performance Profiler for Web Transactions. In E-Commerce Workshop, 2002.