
淺析HBase:為高效的可擴充套件大規模分散式系統而生
什麼是HBase
Apache HBase是執行在Hadoop叢集上的資料庫。為了實現更好的可擴充套件性(scalability),HBase放鬆了對ACID(資料庫的原子性,一致性,隔離性和永續性)的要求。因此HBase並不是一個傳統的關係型資料庫。另外,與關係型資料庫不同的是,儲存在HBase中的資料也不需要遵守某種嚴格的集合格式,這使得HBase是用來儲存結構不嚴格的資料的理想工具。
HBase在大資料應用的架構中應用非常廣泛。但是基於其與關係型資料庫迥異的設計模式,實現這些應用也與基於關係型資料庫來實現非常不同。下文將會對比HBase和關係型資料庫,並淺析HBase的特性。
關係型資料庫與HBase的對比
首先我們要明白在已經存在關係型資料庫的情況下,為什麼產生了所謂的NoSQL/HBase這樣的費關係型資料庫?要解答這個問題,我們需要先了解一下關係型資料庫的優勢和缺點。
- 關係型資料庫提供了標準的資料永續性模型
- SQL語言是事實上的資料操作標準語言
- 關係型資料庫內建了併發資料操作的管理機制
- 關係型資料庫提供全面的資料操作工具
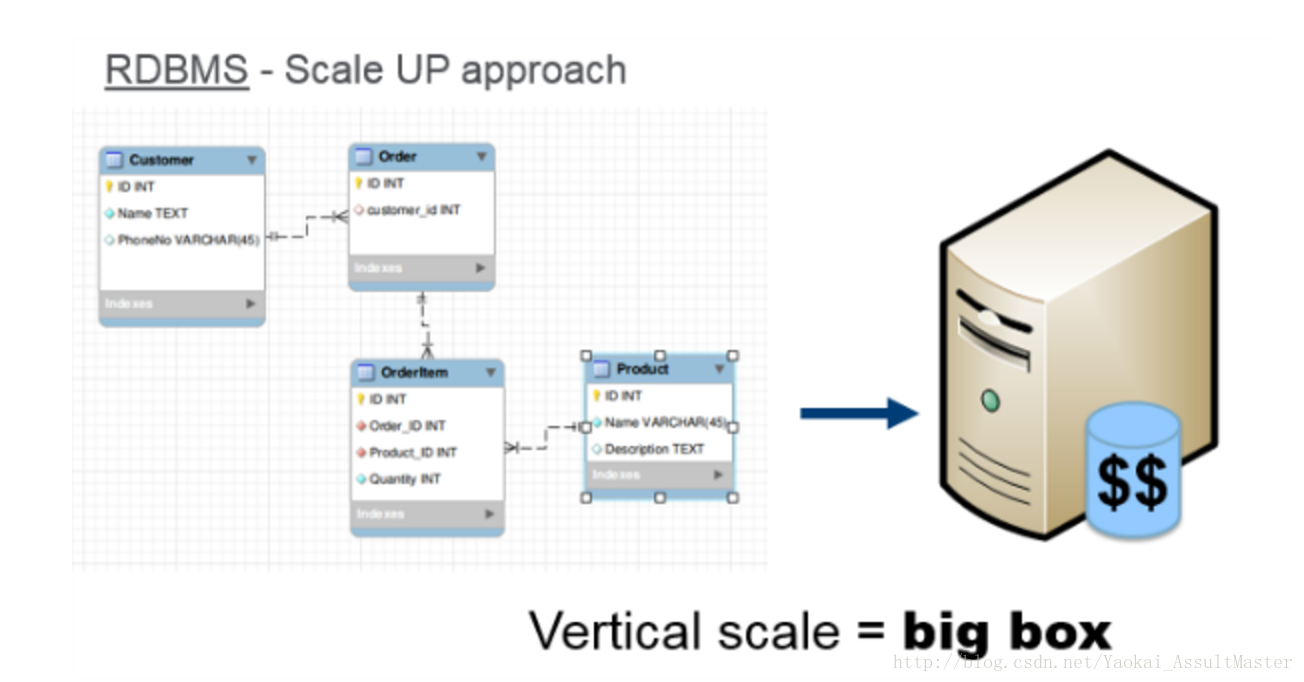
關係型資料庫是長期以來資料儲存的標準工具,那麼我們為什麼還在尋找新的資料儲存方法呢?原因是現在需要儲存的資料越來越多,工業界對資料儲存工具可伸展性的要求也越來越高。一種簡單直接的擴充套件方法是垂直擴充套件,也就是採用更大更高效的伺服器來儲存。但是這種方法成本很高,且可擴充套件性存在一個上限(單臺伺服器的效能是有限的)。
關係型資料庫的侷限性
除垂直擴充套件之外,我們也可以採用水平擴充套件的方法。也就是用伺服器叢集來滿足要求。用來叢集的伺服器可以是效能普通的伺服器。這樣就可以大大降低運營成本。如果我們要採用水平擴充套件的方法來擴充套件關係型資料庫,關係型資料庫中的資料勢必要根據row key分佈儲存,也就意味著某些row key對應的行儲存在某一臺伺服器上,另一些row key對應的行儲存在另一臺伺服器上。然而,要分割一個關係型資料庫是非常複雜的,並且關係型資料庫不具備自動分散式儲存的功能。不僅如此,分佈儲存關係型資料庫,我們將失去總體上的資料庫查詢功能及事務(transaction)的一致性。總而言之,關係型資料庫是為在單臺伺服器上執行而設計的。
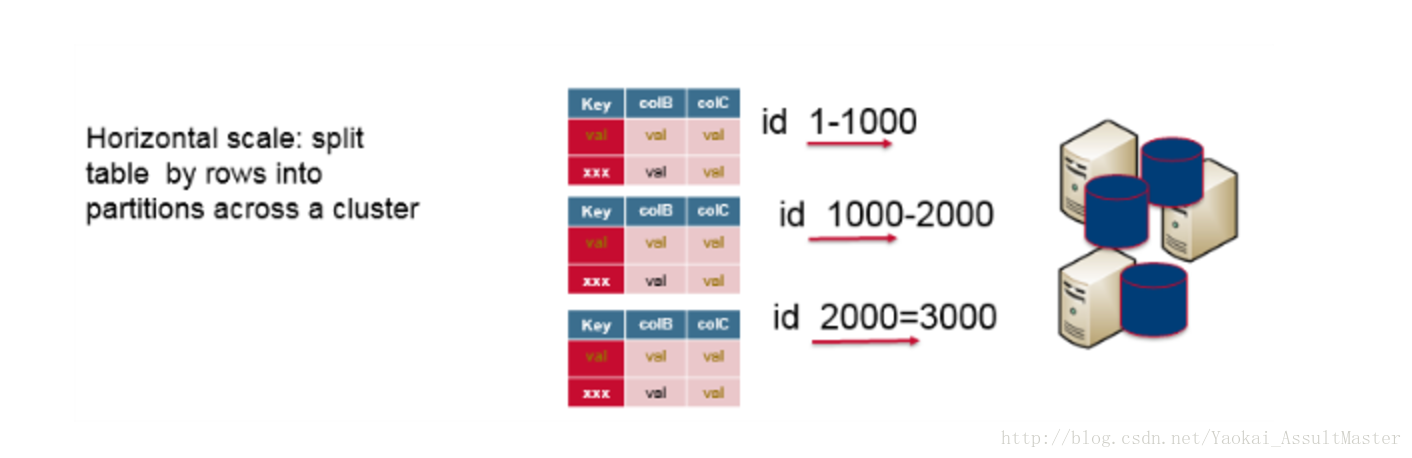
除此之外,關係型資料庫中資料庫規範化(database normalization)的理念消除了資料的重複儲存,使得資料儲存更高效。在查詢時為了將資料重新組織起來,就需要需要Join操作。這也進一步使得關係型資料庫的分散式儲存更為困難。
HBase的高效,分散式,可擴充套件性的設計理念
由於HBase在設計上不支援關係和Join這樣的概念,需要一起查詢的資料就被存在一起。因此也就避免了關係型資料庫的一些侷限性。下圖表現了HBase和關係型資料庫在資料儲存模型上的不同。
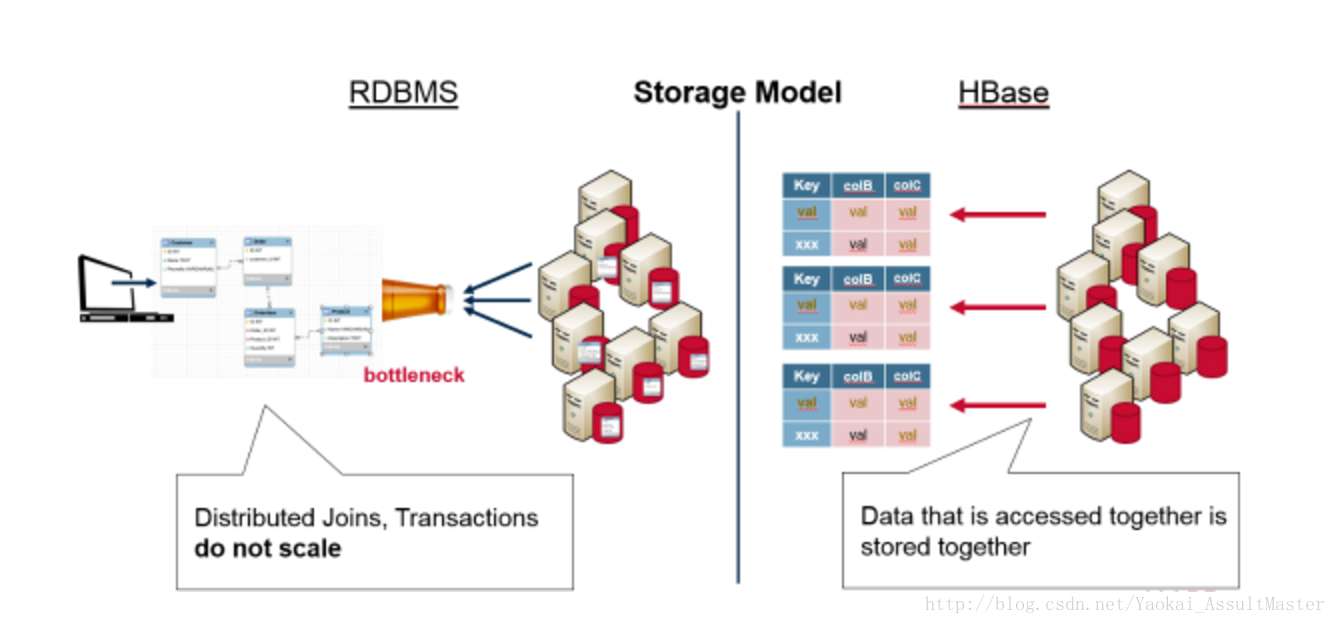
由於HBase將所有需要一起查詢到資料儲存在一起這一特性,HBase叢集就自然能夠根據key來組織資料。在水平分割的時候,key值的範圍就可以被用來分割資料。每一個伺服器儲存全部資料的一個子集。同時分散式的資料還可以被同時訪問。這大大增強了HBase的可擴充套件性。HBase實際上是Google Big Table的一個實現。Big Table是Google提出的一個用來儲存大規模資料的一個分散式系統。
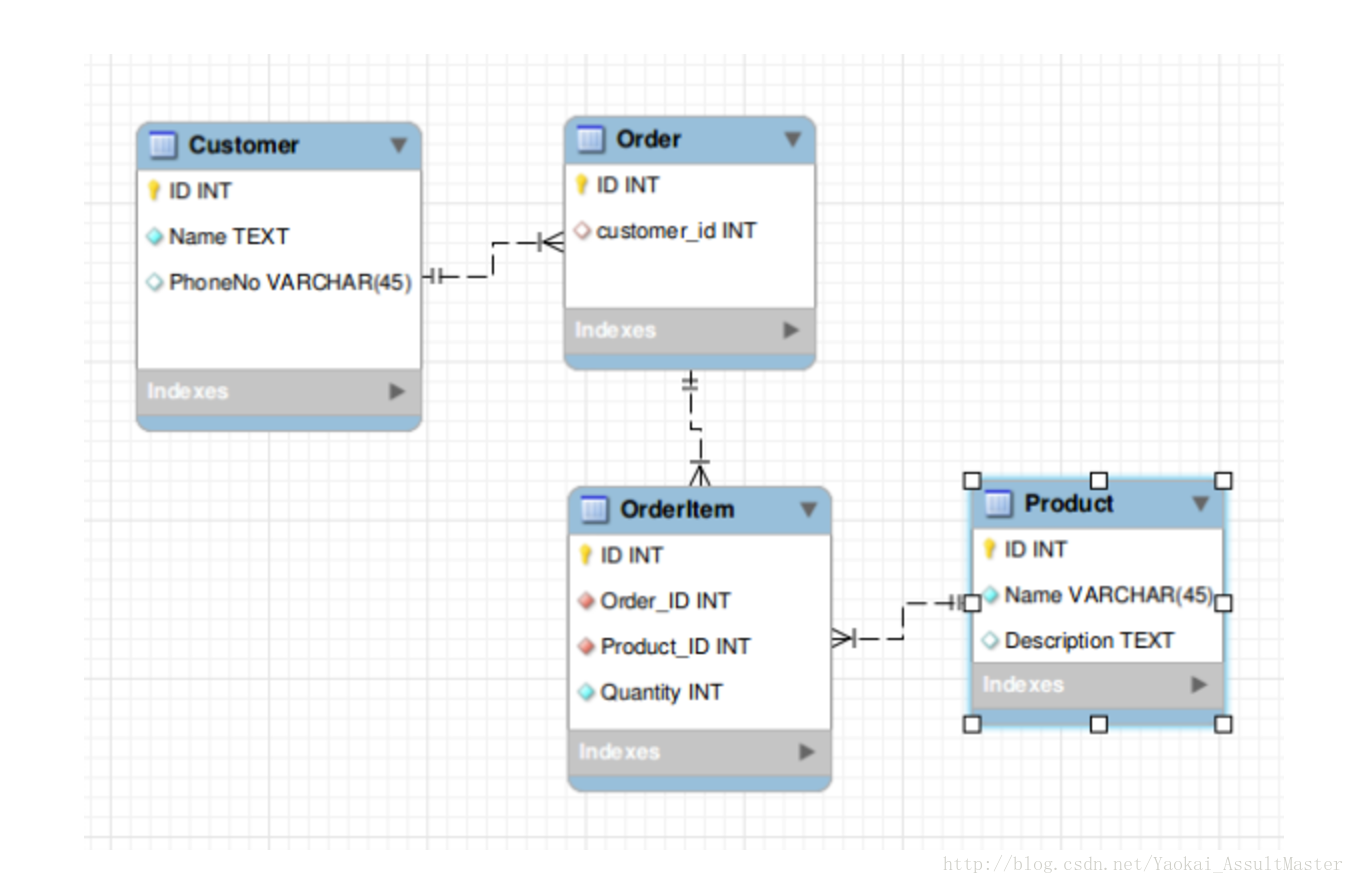
HBase是基於Column family data store的理念設計的:每一行根據一個row key索引。也就是我們用來查詢的主鍵。同時每一行中有若干column family。每一個column family中有若干相關的column。如下圖所示。
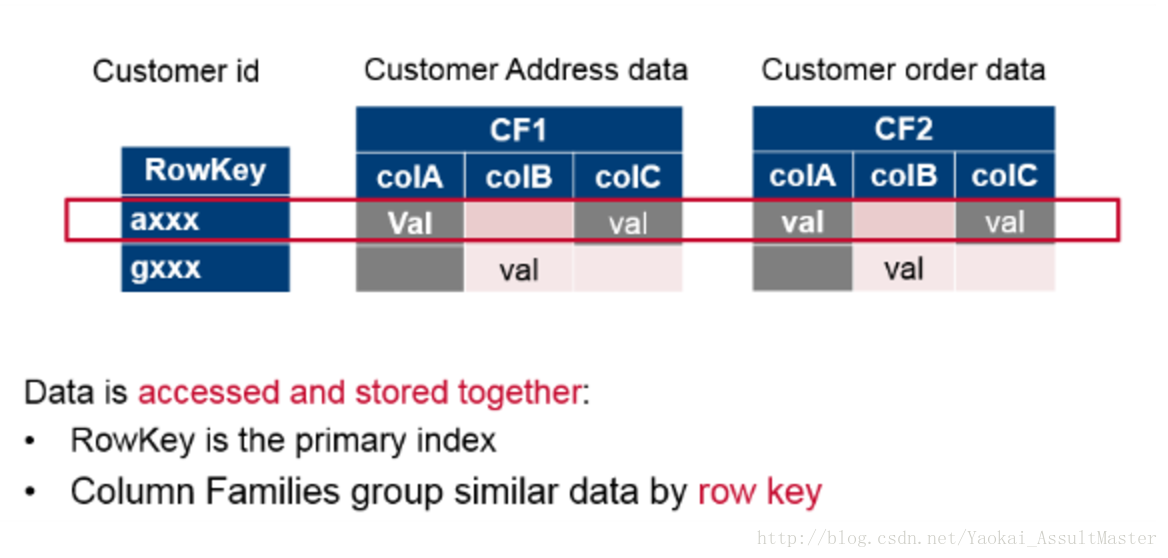
HBase中的row key也是HBase分散式儲存資料的主要根據。在分佈儲存資料的時候,根據row key值的範圍,每一臺伺服器儲存全部資料的一個子集。HBase提供基於行的原子性操作保證。也就是每一個row key對應的行為一個原子操作的單元。
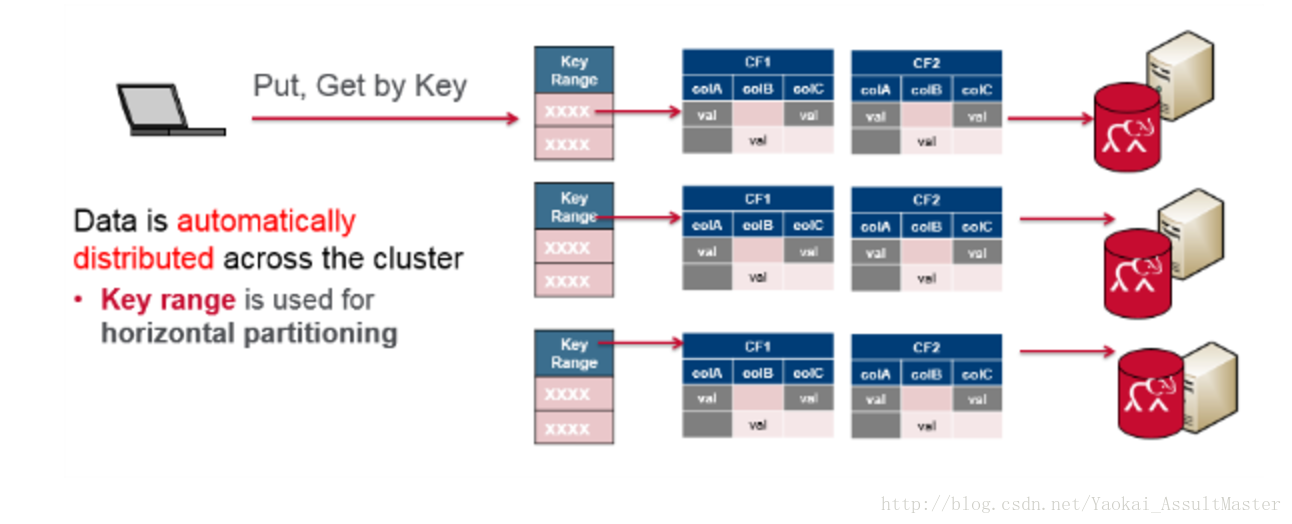
HBase的資料模型
HBase中的資料根據row key分佈。row key類似於關係型資料庫中的主鍵(primary key)。HBase中的資料記錄根據row key的值排序。這是HBase資料儲存的一個重要原則,也是HBase設計架構的一個重要部分。
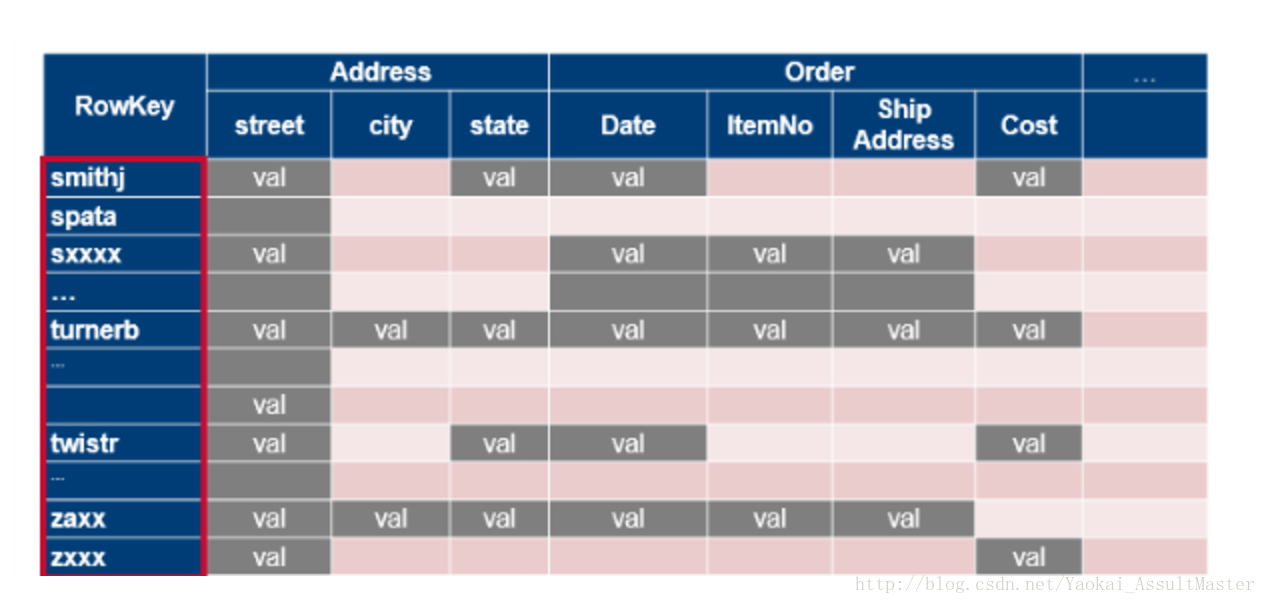
HBase中資料表根據row key的值分割為不同的區域,每個區域包含一部分連續的行。這些區域被分配給叢集中不同的稱為區域伺服器的資料結點。可擴充套件性就是通過將區域分配給叢集中的不同伺服器實現的。這一操作是自動進行的。也就是HBase如何根據水平擴充套件設計的。
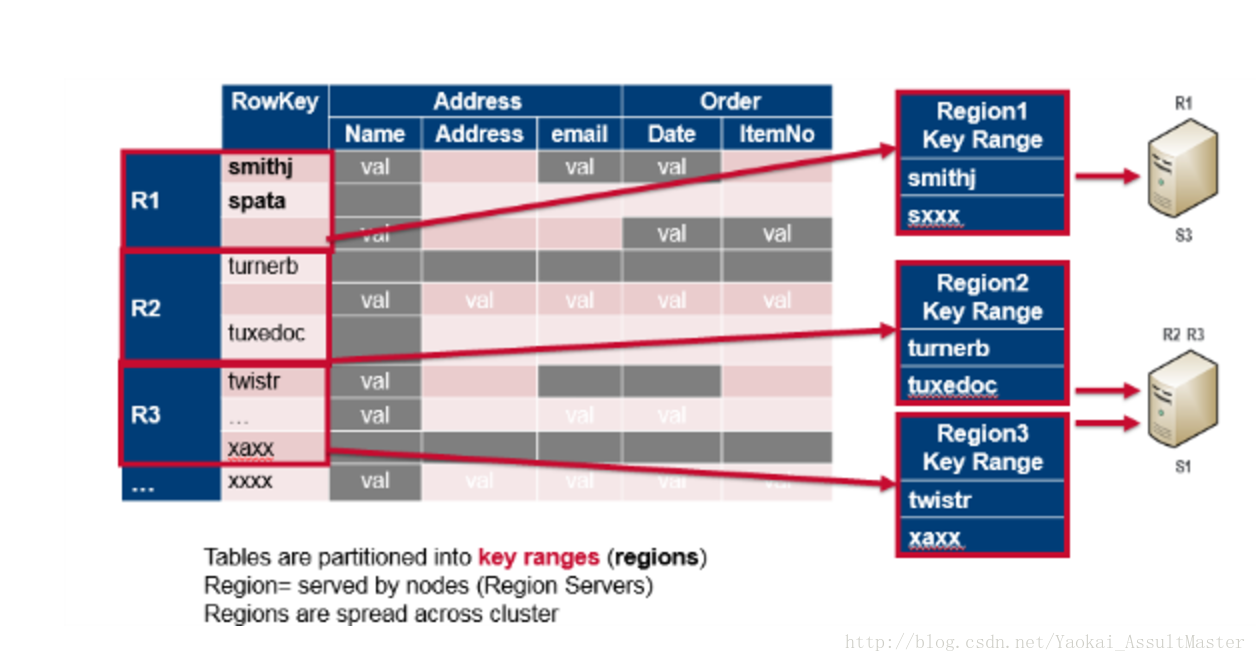
下圖表示了column family是如何對映到儲存檔案的。不同的Column family被儲存在不同的檔案中。這些檔案可以被分別訪問。
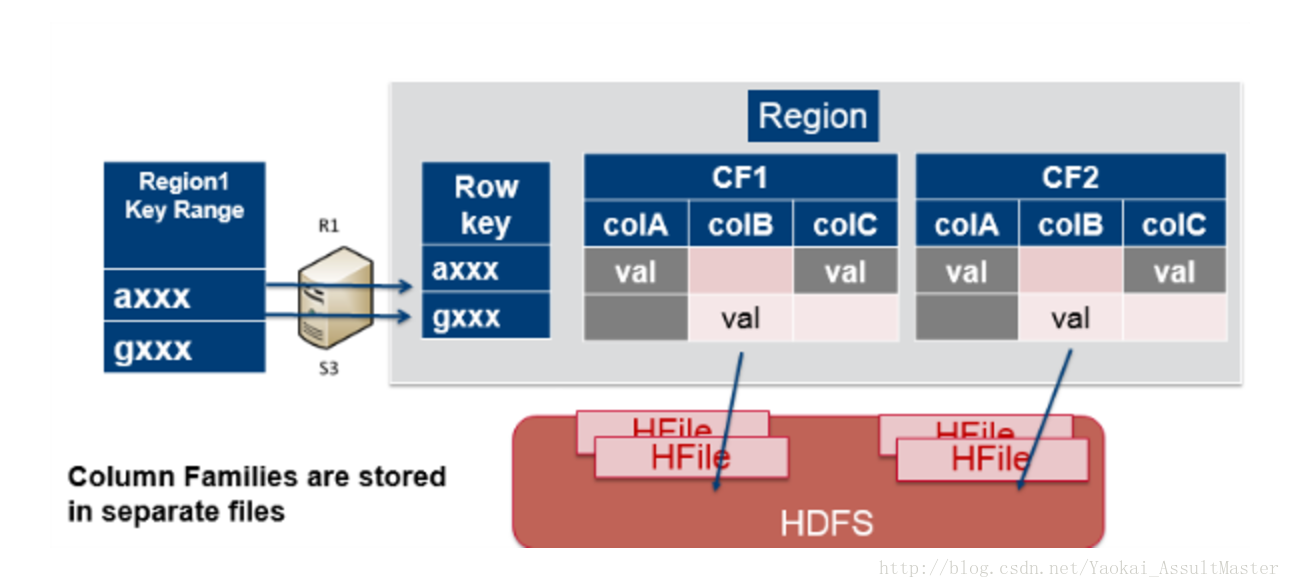
資料儲存在HBase表格的cell中。cell中包含key和value以及一些其他的資訊(如version, type等)。其中key部分包括row key,column family,column qualifier, timestamp。並且對於每一個值,key部分都會與其一同被儲存。如下圖所示。
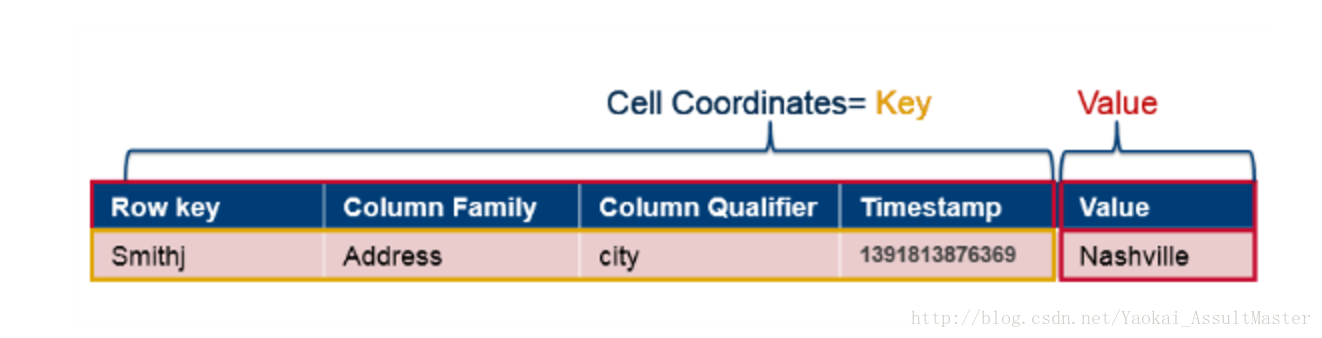
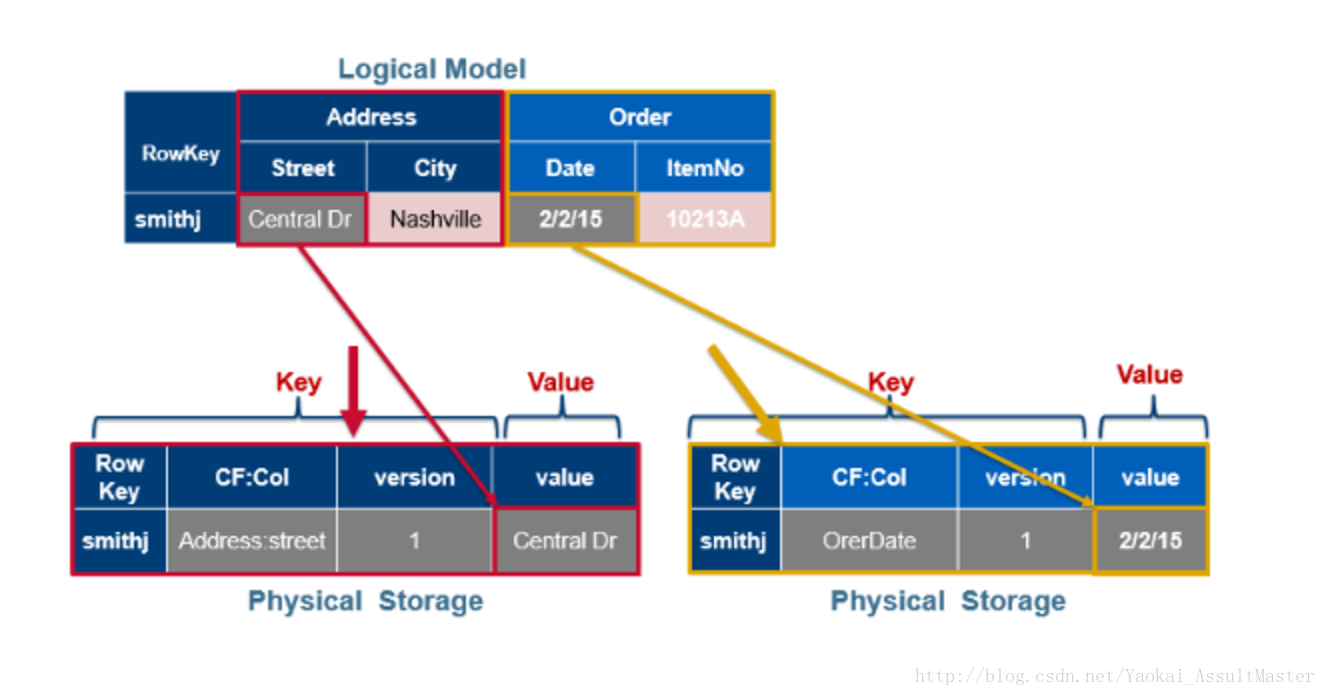
從邏輯上來看,row似乎是以表格的形式儲存的。但事實上,row是以一些cell的集合的形式儲存的。其所對應的每一個cell都儲存了其所對應的上述所有key資訊。
下圖中上半部分是HBase的資料的邏輯佈局,下半部分是檔案的物理佈局。Column family被分別儲存於不同的檔案中。我們每設定一個值,其對應的cell就會儲存所有的key資訊(row key, column family, column qualifier, timestamp)。
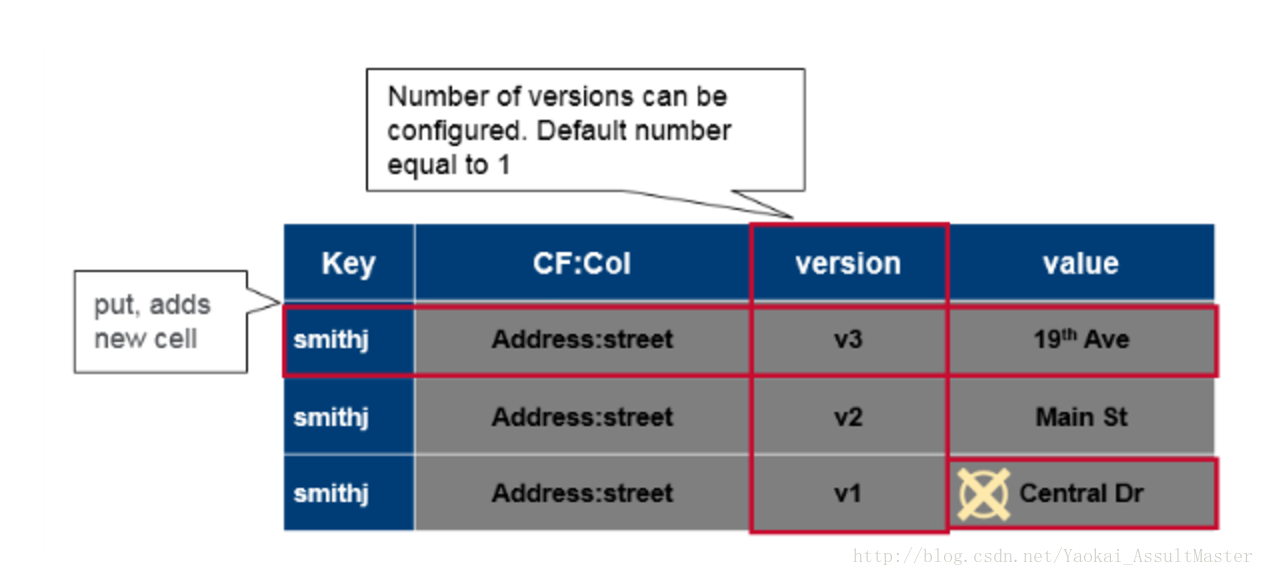
綜上所述,對於HBase中每一個cell的值,其完整的索引應當是Table::Row::Column family::Column::Timestamp –> Value。Hbase的表是稀疏的。如果某一列沒有資料,則其不會被儲存。表中的cell有其對應的連續改變的version。version預設參考timestamp,但我們也可以自己定製。對於每一個Table::Row::Column family::Column –> Value,資料庫中可能儲存了多個不同version的值。
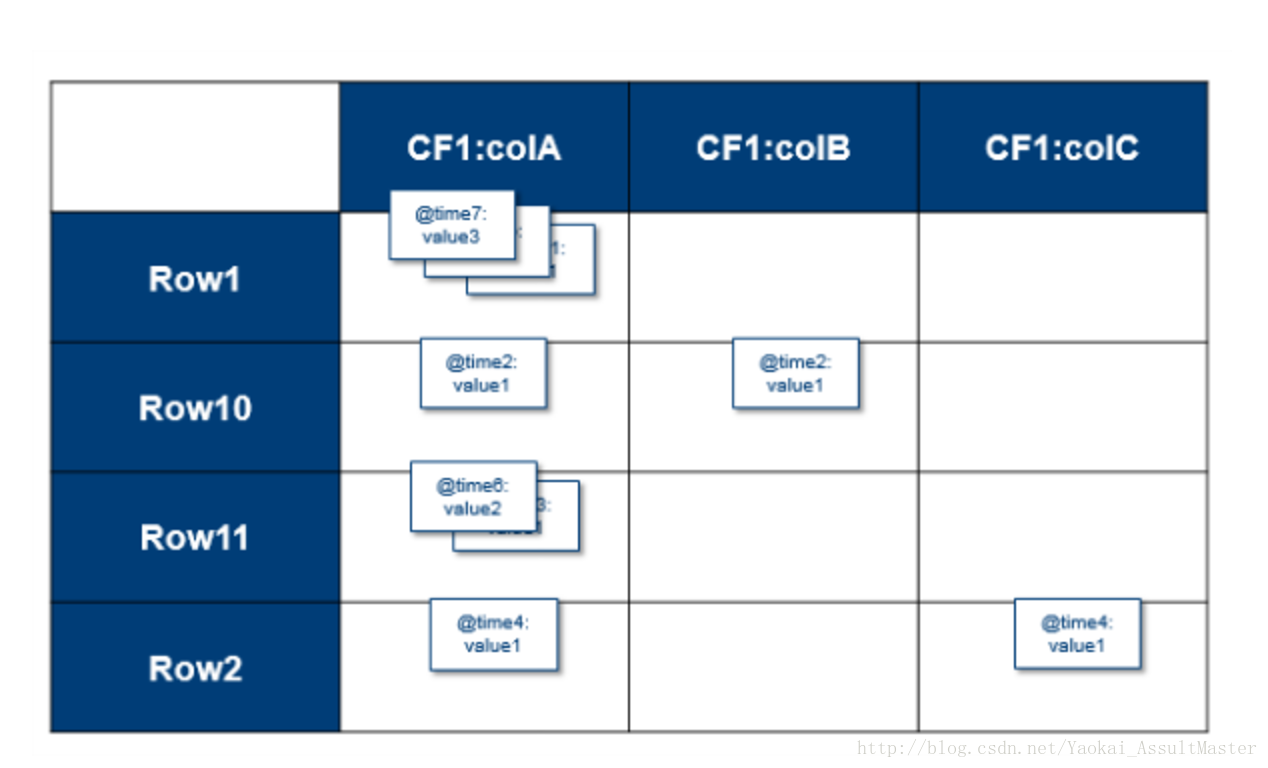
Version系統是HBase自動採用的。從CRUD的角度來說,一個put操作既是插入(insert/create),也是更新(Update)操作,每一個數據都會帶有其相應的version。Delete操作並不會立即在物理上刪除資料,而是會給資料加一個刪除標籤。這個標籤會保證資料不會在查詢時被返回。Get操作根據給定的引數返回特定version的資料。預設情況下最新版本的資料將會被返回。儲存在HBase中的同一個資料的不同version的數量也可以配置。這個數量是針對同一個column family而言的。預設情況下,HBase會儲存3個不同version的資料。當資料不同的version數目超過這個數字時,最早version的資料將會被刪除。
相關推薦
淺析HBase:為高效的可擴充套件大規模分散式系統而生
什麼是HBase Apache HBase是執行在Hadoop叢集上的資料庫。為了實現更好的可擴充套件性(scalability),HBase放鬆了對ACID(資料庫的原子性,一致性,隔離性和永續性)的要求。因此HBase並不是一個傳統的關係型資料庫
【積水成淵-逐步定製自己的Emacs神器】3:為Emacs安裝擴充套件
前言 本文介紹瞭如何使用Emacs的Package-Mode來為其安裝擴充套件包,講解如何新增新的Package源和如何安裝Package。以安裝一個新的主題包Solarizd和Markdown編輯擴充套件Markdown-Mode為例進行講解。 檢視P
Ceph:一種可擴充套件,高效能的分散式檔案系統
摘要 我們開發了 Ceph,一種分散式檔案系統。該檔案系統提供極佳的效能,可靠性以及擴充套件性。通過專為不可靠的物件儲存裝置(Object Storage Device,OSDs)所組成的異構、動態叢集而設計的準隨機資料分配演算法(CRUSH),利用其替代檔案分配表,Cep
【轉】編寫高質量代碼改善C#程序的157個建議——建議64:為循環增加Tester-Doer模式而不是將try-catch置於循環內
特殊 bsp 處理 註意 輸出 read seconds ise new 建議64:為循環增加Tester-Doer模式而不是將try-catch置於循環內 如果需要在循環中引發異常,你需要特別註意,應為拋出異常是一個相當影響性能的過程。應該盡量在循環當中對異常發生的
一張圖講清楚高可用、高效能、可擴充套件的WEB系統架構
前言:最近在與廣東網際網路基地一起進行無線城市集中平臺的建設,在系統設計、架構調優上做了很多的探索,也在系統整合測試和效能調優中遭遇了很多的煩惱,心裡有一些所得所悟,希望與大家共同學習探討。 WEB系統最容易出現效能故障的點在哪裡? 有很多人對此不知其然,或知其然而不
痞子衡嵌入式:MCUBootFlasher v3.0釋出,為真實的產線操作場景而生
-- 痞子衡維護的NXP-MCUBootFlasher工具(以前叫RT-Flash)距離上一個版本(v2.0.0)釋出過去一年半以上了,這一次痞子衡為大家帶來了全新版本v3.0.0,從這個版本開始,NXP-MCUBootFlasher將不再侷限於i.MXRT系列,也要開始支援經典的LPC,Kinetis系
GAIAWORLD為真正懂區塊鏈的你而生
區塊鏈 遊戲 微信公眾號: GAIAWorld 這是一個浮躁的時代,販賣新奇概念、講述動人故事、明星大佬站臺、營銷決定成敗!項目是否靠譜已經不再重要,"什麽時候上交易所"才是核心競爭力。對於一個幹實事的團隊,這似乎是一個暗無天日的殘酷時代。 然而,我們並不悲觀。 我們堅信,有那麽一
Google Dapper 大規模分散式系統的跟蹤方案
這是引用網上翻譯的谷歌在監控方面的重要論文,對於大規模分散式系統的監控和呼叫跟蹤,具有極強的指導意義。現有的很多分散式監控系統,如Spring Cloud 的 Sleuth+Zipkin,就是這種設計的一種實現。 概述 當代的網際網路的服務,通常都是用複雜的、大規模分散式叢
唯品會Microscope——大規模分散式系統的跟蹤、監控、告警平臺
最近的工作是在唯品會做監控平臺Microscope。我們的目標是:大規模分散式系統的跟蹤、監控、告警平臺。 對於鏈路監控這塊,業界的論文當屬Google Dapper這篇,它詳細的闡述瞭如何對請求呼叫鏈進行跟蹤,提出了理論模型,然後它沒有具體的程式碼實現。Twitter 的
Dapper,大規模分散式系統的跟蹤系統
概述 當代的網際網路的服務,通常都是用複雜的、大規模分散式叢集來實現的。網際網路應用構建在不同的軟體模組集上,這些軟體模組,有可能是由不同的團隊開發、可能使用不同的程式語言來實現、有可能布在了幾千臺伺服器,橫跨多個不同的資料中心。因此,就需要一些可以幫助理解系統行為、用於分析效能問題的工具。
分散式系統 (大規模分散式系統原理解析和架構實踐)
分散式系統的基礎理論: 分散式系統:多臺機器通過網路連線在一起,作為一個整體為上層提供服務。 一、基礎理論知識:資料分佈、複製、一致性、容錯。 1、異常 (1)伺服器宕機(記憶體錯誤,伺服器停電):如
《大規模分散式系統架構與設計實戰》
這本書,我看了兩遍。為什麼看兩遍呢,因為說實話,第一遍沒有完全看懂。 第一遍讀過來,感覺作者講了很多東西,但似乎又什麼都沒講,總之看完之後有一種很奇怪的感覺。於是,便看了第二遍。第二遍讀下來,才算是對這本書有了一個清楚的認識。 按照書中作者的說法,這本書不是講"如何使用H
如何進行高效的原始碼閱讀:以Spring Cache擴充套件為例帶你搞清楚
摘要 日常開發中,需要用到各種各樣的框架來實現API、系統的構建。作為程式設計師,除了會使用框架還必須要了解框架工作的原理。這樣可以便於我們排查問題,和自定義的擴充套件。那麼如何去學習框架呢。通常我們通過閱讀文件、檢視原始碼,然後又很快忘記。始終不能融匯貫通。本文主要基於Spring Cache擴充套件為例
HashiCorp:為任何應用程序提供安全和可運行的基礎架構
dev com 解決 進入 開源 adg 舊金山 虛擬機 產品 HashiCorp 由Mitchell Hashimoto和Armon Dadgar於2012年創辦,總部位於美國舊金山。 HashiCorp致力於解決基礎架構中的開發、維護及安全所面臨的挑戰。 HashiCo
Android 開發:(十)初識ExpandableListView(可擴充套件的下拉列表元件)
隨便扯點兒 前幾天做iOS仿QQ,其中好友列表頁面就有下拉列表的功能,iOS做法應該比安卓稍微複雜一點,其中佈局以及一些實現方法(協議方法)都類似,不一樣的應該是動畫切換效果,安卓提供現成的元件,用原生的就可以實現。 iOS示例 http://blog.
埃森哲研究報告顯示:區塊鏈技術可推動大規模交易轉型
據福布斯10月16日報道,為全球金融市場提供基礎設施服務的美國證券託管清算公司(Depository Trust & Clearing Corporation, DTCC)最近公佈了埃森哲的一份研究報告。埃森哲在該報告中表明,分散式賬本技術(DLT)能夠支援美國股票市場的日
第二十三章:XML可擴充套件標記語言
作者:java_wxid XML 簡介 什麼是 XML? XML 指可擴充套件標記語言(EXtensible Markup Language)。 XML 是一種很像HTML的標記語言。 XML 的設計宗旨是傳輸資料,而不是顯示資料。 XML 標籤沒有被預定義。您需要自行定義標籤。
xml(可擴充套件標記語言)dtd(xml約束,文件型別定義)schema(功能比dtd更強大,用以定義xml檔案。字尾名為xsd檔案)
xml:要理解什麼是xml檔案,和html(超文字標記語言)做比較,就很清晰了。 html:是一種可在瀏覽器中顯示的檔案,主要功能是將裡面的文字內容靜態的展示出來,用於顯示資料。 html使用的標籤html語言規定好的,每個
一種高效的android雙擊退出(可擴充套件多擊)
參考Google,安卓手機中在檢視安卓系統版本的地方,三擊或者多擊會出現彩蛋,可以借鑑其原始碼進行實現。 //利用陣列來儲存時間 long[] mHits = new long[3]; @Override pub
NetSuite專為現代高增長科技企業打造的可擴充套件基礎平臺
能夠隨著您的超高速發展而擴充套件的基礎平臺 在高科技行業中,遠見和擴充套件能力往往是決定成敗的分界線。有些科技公司深知,促進和應對增長的關鍵是具備一個既能應對當前挑戰、又能為未來奠定關鍵基礎的後端系統,於是 NetSuite 雲 ERP/財務套件成為這些企業的首選。 NetSuite 對於超