
分析9000部電影|一個簡單的電影推薦系統
不知道大家平時喜不喜歡看電影來消遣時光,我是比較喜歡看電影的。對我而言,當我看完一部電影,覺得很好看的時候,我就會尋找類似這部電影的其他電影。剛好有這麼一個數據集,包含了很多部的電影,於是打算對其進行一波簡單的分析並嘗試建一個簡單的“推薦系統”,一起來看一下吧~~
給大家整理了Python很全面的資料和教程可以下載,加群943752371即可
庫:
Pandas,Numpy,Re
工具:
Ipython Notebook
這邊插一句,小密圈曾經有一篇文章大家一起討論了常用的5種Python開發工具,Notebook做資料分析並且記錄筆記非常不錯!
1.資料集
本文使用的資料集來自於https://grouplens.org/datasets/movielens/,上面有多種版本,主要區別在於資料集的大小(即收錄的電影和使用者資訊的多少),這裡使用的是最小的一個數據集:

2.資料初探
資料集裡包含了4個檔案,本文只用到了其中的兩個:電影資訊movies.csv,使用者對電影的評分ratings.csv,先來看看這兩個檔案長什麼樣:
import pandas as pd
movies_data=pd.read_csv('movies.csv')
ratings_data=pd.read_csv('ratings.csv')
print (movies_data)
1).看一下movies_data裡的資料
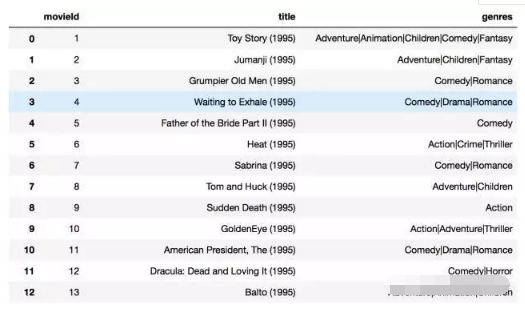
2).看一下使用者評分的資料:

顯然,如果單純從單個檔案裡來分析的話似乎得不到什麼有用或者是直觀的資訊,但是我們可以把這兩個資料幀(DataFrame)結合起來,合成新的,把使用者評分和電影資訊結合起來,方便我們後續的分析處理
3).合併兩個資料集
"#合併
data=pd.merge(movies_data,ratings_data)
"#刪除列,可寫可不寫,不會產生影響
data.drop('timestamp',1,inplace=True)

好了,完成了這一步,我們把重要的資訊都結合在一起了,可以開始我們真正的資料分析或探索了,接著看看那些電影收到的評分最多,我們只需一句(value_counts()是我在pandas裡最喜歡的一個函式之一)
4).看看評價最多的20名電影

嗯,經典就是經典,評價最多的前幾部都是有名的電影(阿甘正傳、低俗小說、肖申克的救贖、沉默的羔羊、星球大戰……)
看完評價最多的電影,但大多數人更加關心的是電影究竟好不好看,於是乎,我們就把目光轉向評分這裡. 那接著就來統計下使用者對每一部電影的平均評分吧
5).電影的平均評分

其中size是每部電影參評人數,mean是平均分.
6).繼續找一下評分最高的top5:

咦,我們可以看到,雖然評分是5分,但是……評分只有1人啊,這樣絕不是我們想看到的,因為不是很客觀,於是,我們再來改進下
這次我們把評價人數大於150人的電影找出來,在進行統計:

哈哈哈,這樣就客觀多了嗎,top5分別是:教父、肖申克的救贖、非常嫌疑犯、辛德勒的名單、冰血暴,都是經典電影(大家都看過沒有呢)
3.簡單的推薦系統
當我們看完一部覺得好看電影,是不是會有這樣的感覺,立馬看有沒有續集,沒有的話就會找相似的電影。
是的,這裡是基於這樣思想,當我們輸入一部電影,就找同樣的型別的電影,然後返回給我們結果
用程式碼實現也不多,主要思想是:我們輸入電影名或關鍵詞,我們就從資料幀裡匹配,然後找到這部電影的型別,再找出與其相同型別的電影,最後返回結果,具體程式碼為:
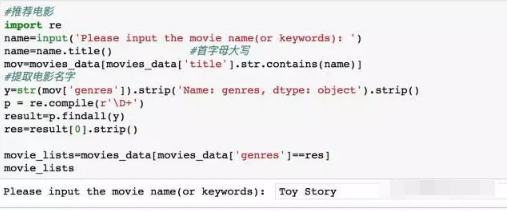
看看和Toy Story(玩具總動員)類似的動畫片有哪些

比如找一下星球大戰類似的電影:
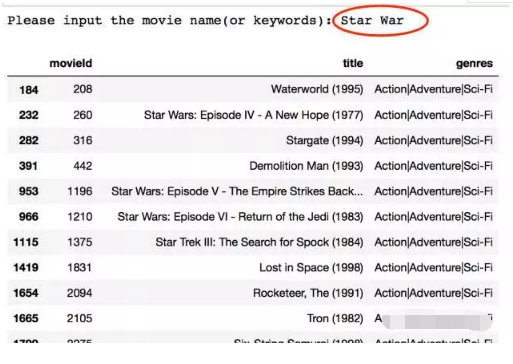
限於篇幅沒有完全截圖
結論:
正如前文剛剛提到過一樣,這個資料集還是比較小的,只有九千多條電影記錄,當然網站上可以下載更多的資料和更多有趣的資訊。另外這個“推薦系統”比較簡單,各位小夥伴可以根據自身的要求,再進一步的優化升級,這裡就當做是拋磚引玉吧!