
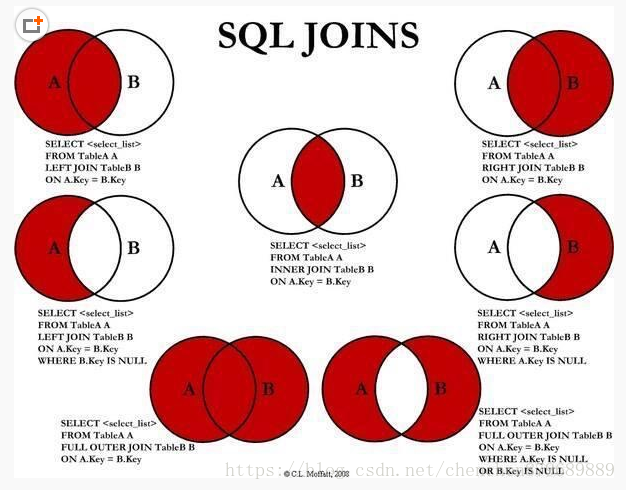
sql joins 與 in
in: 先篩查出結果集,再在結果集中篩選。 select * from A where A.id in(select B.id from B where B.DZ='110' ) and A.DZ='110'
這個的結果是 B.DZ=110 與 A.DZ=110 都得滿足的條件
相關推薦
sql joins 與 in
in: 先篩查出結果集,再在結果集中篩選。 select * from A where A.id in(select B.id from B where B.DZ='110' ) and A.DZ='110'
Sql中EXISTS與IN的使用及效率
in 和exists 對於以上兩種查詢條件,in是把外表和內表作hash 連線,而exists 是對外表作loop 迴圈,每次loop 迴圈再對內表進行查詢。 一直以來認為exists 比in 效率高的說法是不準確的。在不同的情況下,exists與in的效能各有優缺項,如果查詢的兩個表大小相當,那麼用in
面試被問之-----sql優化中in與exists的區別 Mysql中 in or exists not exists not in區別 (網路整理) Sql語句中IN和exists的區別及應用 [筆記] SQL效能優化 - 避免使用 IN 和 NOT IN
曾經一次去面試,被問及in與exists的區別,記得當時是這麼回答的:''in後面接子查詢或者(xx,xx,xx,,,),exists後面需要一個true或者false的結果",當然這麼說也不算錯,但別人想聽的是sql優化相關,肯定是效率的問題,只是那個時候確實不知道它們在sql優化上的區別,只知道用in會進
sql優化之in與
在我們開發過程中,初期可能不會去太關注我們自己寫的sql語句的效率怎麼樣,因為總是覺得可以拿取到資料就算是ok了,可能也會注意一下你的sql執行的時間,但是在開發的過程中因為資料量的原因,其實你不去了解一下sql的一些優化的手段其實是無法感知你的sql的效率問題
資料庫SQL查詢效率in、exists、left join on、right join on 適用場景與比較
in 與 join例 select t1.id,sum(t1.num) from (select * from t2 where num =2) as t3 LEFT JOIN t1 on t3.id=t1.id GROUP BY t1.id; join 時間: 0.005
淺談sql中的in與not in,exists與not exists的區別以及效能分析
1、in和exists in是把外表和內表作hash連線,而exists是對外表作loop迴圈,每次loop迴圈再對內表進行查詢,一直以來認為exists比in效率高的說法是不準確的。如果查詢的兩個表大小相當,那麼用in和exists差別不大;如果兩個表中一個較小一個較大,則子查詢表大的用exists,子查
sql中的in與not in,exists與not exists的區別
1、in和exists in是把外表和內表作hash連線,而exists是對外表作loop迴圈,每次loop迴圈再對內表進行查詢,一直以來認為exists比in效率高的說法是不準確的。如果查詢的兩個表大小相當,那麼用in和exists差別不大;如果兩個表中一個較小一個較
遍歷資料庫表(ACCESS/SQL SERVER)的方法。SQL中IN,NOT IN,EXISTS,NOT EXISTS的用法和差別。資料庫中的exists與in
遍歷資料庫表(ACCESS/SQL SERVER)的方法 以前在網上查詢遍歷SQL資料庫表的方法,可以用 select name from sysobjects where xtype='u' and (not name LIKE 'dtproperties') 來查詢SQL的系
SQL中EXISTS與IN的效率問題
一起學習一下;有兩個簡單例子,以說明 “exists”和“in”的效率問題1) select * from T1 where exists(select 1 from T2 where T1.a=T2.a) ; T1資料量小而T2資料量非常大時,T1<<T
SQL優化關於or與in使用
網上有很多人都在談論or與in的使用,有的說二者沒有什麼區別,其實不然,估計是測試做的不夠,其實or的效率為O(n),而in的效率為O(log2n),當基數越大時,in的效率就能凸顯出來了。有人做了這麼一組實驗(測試庫資料為1000萬條記錄):A組分別用or與in查詢3條記錄
淺談sql中的in與not in,exists與not exists的區別
1、in和exists in是把外表和內表作hash連線,而exists是對外表作loop迴圈,每次loop迴圈再對內表進行查詢,一直以來認為exists比in效率高的說法是不準確的。如果查詢的兩個表大小相當,那麼用in和exists差別不大;如果兩個表中一個較小一個較
SQL查詢中in、exists、not in、not exists的用法與區別
1、in和exists in是把外表和內表作hash(字典集合)連線,而exists是對外表作迴圈,每次迴圈再對內表進行查詢。一直以來認為exists比in效率高的說法是不準確的,如果查詢的兩個表大小相當,那麼用in和exists差別不大;如果兩個表中一個較小一
sql當中NOT IN和IN,exists與not exists的區別
相同 eno select 意思 note pre 區別 有一點 不同 1、EXISTS=IN,意思差不多相同,但是語法上有一點不同,好像使用IN效率要差點,應該是不會執行索引的原因 1 SELECT ID,NAME FROM A WHERE ID IN (SELECT
Sql語句中IN和exists的區別及應用
應用場景 將不 集中 pre 代碼 根據 gif 效率 .cn 表展示 首先,查詢中涉及到的兩個表,一個user和一個order表,具體表的內容如下: user表: order表: in 確定給定的值是否與子查
如何用Elasticsearch實現類似SQL中的IN查詢實例
red ast last .cn lte style sea ges logs 我想實現類似如下sql語句的效果: select * from table1 where rw_id in (‘7a482589-e52e-0887-4dd5-5821aab77eea‘,‘c
初識關系型數據庫(SQL)與非關系型數據庫(NOSQL)
edi 關系型數據庫 底層 手機 col 效率 name 項目 去掉 一.關系型數據庫(SQL): Mysql,oracle 特點:數據和數據之間,表和字段之間,表和表之間是存在關系的 例如:部門表 001部分, 員工表 001 用戶表,用戶名、密碼
PL/SQL簡介與基本語法
rep round 子程序 package 符號 編程語言 類型 運算符 授權 PL/SQL的簡介: PLSQL 是Oracle公司在SQL基礎上進行擴展而成的一種過程語言。PLSQL提供了典型的高級語言特 性,包括封裝,例外處理機制,信息隱藏,面向對象等;並
sql中的in
創建索引 nbsp oracl all my.ini rac allow 使用 如果 在sql中謹慎使用 oracle10g要求in裏面最多1000個元素 mysql中為可在my.ini中配置選項,參數名max_allowed_packet 使用show var
Sql server not in優化
size ccs pan tracking read in子句 class 1.2 oracle 使用EXISTS(或NOT EXISTS)通常將提高查詢的效率,由於NOT IN子句將對子查詢中的表執行了一個全表遍歷。 oracle在執行IN子查詢過程中,先執行子查詢
hasOwnProperty()與in操作符的區別
per 返回 true 屬性 images com blog 操作符 src hasOwnProperty() 判斷屬性是否是實例化(不包括原型)的屬性, 存在會返回true; 否則, 返回false in 無論屬性是存在實例本身中, 還是原型對象中, 存在會返回tru