
利用NetCat實現sparkstreaming按批次累加小練習
阿新 • • 發佈:2018-12-25
netcat是網路工具中的瑞士軍刀,它能通過TCP和UDP在網路中讀寫資料。netcat所做的就是在兩臺電腦之間建立連結並返回兩個資料流,通過與其他工具結合和重定向,你可以在指令碼中以多種方式使用,你能建立一個伺服器,傳輸檔案,與朋友聊天,傳輸流媒體或者用它作為其它協議的獨立客戶端。
首先在centos7上安裝netCat,聯網情況下執行命令yum install nmap-ncat.x86_64。
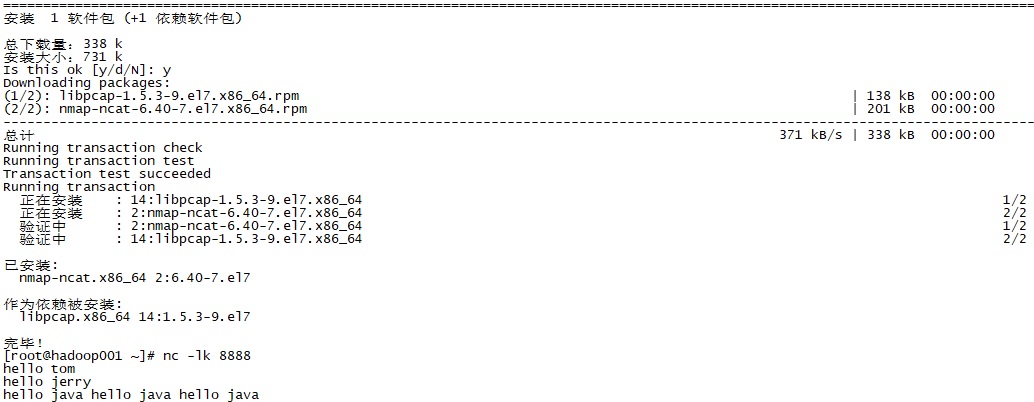
安裝完畢後,執行命令nc -lk 8888,將標準輸入轉發到192.168.119.51(安裝natcat的機器)的8888埠,,並將返回輸出到標準輸出。
測試程式如下:
package cn.allengao.stream import org.apache.spark.{HashPartitioner, SparkConf} import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.{Seconds, StreamingContext} /** * class_name: * package: * describe: 實現按批次累加的功能,實現WordCount * creat_user: Allen Gao * creat_date: 2018/2/11 * creat_time: 11:19 **/ /* maven裡面新增依賴: */ object StreamWC { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("StreamWC").setMaster("local[*]") val ssc = new StreamingContext(conf, Seconds(5)) // 如果要使用updateStateByKey運算元,就必須設定一個checkpoint目錄,開啟checkpoint機制。 // ssc.checkpoint("hdfs://hadoop001:9000/ck-20180211") ssc.checkpoint("j://Dstream/ck-20180211") val dStream = ssc.socketTextStream("192.168.119.51", 8888) val tuples: DStream[(String, Int)] = dStream.flatMap(_.split(" ")).map((_, 1)) //按照批次累加需要呼叫updateStateByKey的方法 /* 引數1:狀態更新函式 引數2:分割槽演算法 引數3:是否在接下來的操作中產生的RDD呼叫相同的分割槽演算法 引數4:初始的(K,V)對型別的RDD */ val res: DStream[(String, Int)] = tuples.updateStateByKey(func, new HashPartitioner(ssc.sparkContext.defaultParallelism), false) res.print() ssc.start() ssc.awaitTermination() } /* (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)]如何解讀: 入參:三元組迭代器,三元組中K表示Key,Seq[V]表示一個時間間隔中產生的Key對應的Value集合(Seq型別,需要對這個集合定義累加函式邏輯進行累加), Option[S]表示上個時間間隔的累加值(表示這個Key上個時間點的狀態) 出參:二元組迭代器,二元組中K表示Key,S表示當前時間點執行結束後,得到的累加值(即最新狀態) */ // val func = (it: Iterator[(String, Seq[Int], Option[Int])]) => { it.map(t => { (t._1, t._2.sum + t._3.getOrElse(0)) }) } }
執行程式,在netcatch中輸入hello tom hello jerry
輸出結果:
-------------------------------------------
Time: 1518332160000 ms
-------------------------------------------
(tom,1)
(hello,2)
(jerry,1)
過5秒鐘再輸入hello java hello java hello java
輸出結果:
-------------------------------------------
Time: 1518332165000 ms
-------------------------------------------
(tom,1)
(hello,5)
(java,3)
(jerry,1)
這樣就用sparkstreaming實現了資料的累加。