
Hadoop 核心概念解析
Hadoop 權威指南讀書筆記 - 入門
前言
在大學裡曾經使用過Nutch,實現了一個簡單的搜尋引擎。工作之後,公司裡有同事使用Lucene來做站內搜尋。這些年伴隨著大資料的興起,Hadoop已經成為了靜態資料處理的標準,號稱效能更優且可以處理
流式資料的Spark也發展得如火如荼。記得那時候搜尋引擎還是一個高階的技術,是一種非常神祕的存在,能夠從紛繁複雜的資料海洋中精確地找到使用者想要的資訊,這確實能夠直觀地體現技術的價值。這些年
過去之後,發現搜尋這個詞不見了,更為的是智慧推送。從你希望系統告訴你什麼,變成了系統知道你需要什麼,這是一步很大的跨越,相信將來沒有大資料處理的概念,因為大資料處理是基本的技術。
Hadoop的歷史
Hadoop 並不是從石頭裡面蹦出來的,而是從其他專案演化過來的。其中有兩個專案不得不提-Lucence和Nutch。
Lucene其實是一個提供全文文字搜尋的函式庫,它不是一個應用軟體。它提供很多API函式,是一個開放原始碼的全文檢索引擎工具包,讓你可以運用到各種實際應用程式中。它提供了完整的查詢引擎和索引引擎
以及部分的文字分析功能。Lucene的目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實現全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎。
Nutch是一個建立在Lucene核心之上的Web搜尋的實現,它是一個真正的應用程式。也就是說,你可以直接下載下來拿過來用。它在Lucene的基礎上加了網路爬蟲和一些和Web相關的內容。其目的就是想從一個
簡單的站內索引和搜尋推廣到全球網路的搜尋上,就像Google和Yahoo一樣。
Hadoop 是一個分散式計算的基礎架構,使用者在不需要了解底層細節的情況下,開發分散式的應用。Hadoop 最重要的是實現了一個分散式的檔案系統,這樣的檔案系統可以架構在價格低廉的叢集之上。Hadoop
另外一個重要內容就是MapReduce,一種分散式任務處理的架構。這兩個部分構成了Hadoop的基石,Hadoop在創新在於從以前的以應用為中心,轉變為以資料為中心。以前是應用獲取資料進行處理,現在是將
計算任務傳送給資料,然後進行處理。
它主要有以下幾個優點:
1. 高可靠性。Hadoop按位儲存和處理資料的能力值得人們信賴。
2. 高擴充套件性。Hadoop是在可用的計算機集簇間分配資料並完成計算任務的,這些集簇可以方便地擴充套件到數以千計的節點中。
3. 高效性。Hadoop能夠在節點之間動態地移動資料,並保證各個節點的動態平衡,因此處理速度非常快。
4. 高容錯性。Hadoop能夠自動儲存資料的多個副本,並且能夠自動將失敗的任務重新分配。
5. 低成本。與一體機、商用資料倉庫以及QlikView、Yonghong Z-Suite等資料集市相比,hadoop是開源的,專案的軟體成本因此會大大降低。
Hadoop 也是由諸多的子專案構成的,下面是組成Hadoop的核心專案:
1. HDFS: Hadoop分散式檔案系統(Distributed File System) - HDFS (Hadoop Distributed File System)
2. MapReduce:平行計算框架,0.20前使用 org.apache.hadoop.mapred 舊介面,0.20版本開始引入org.apache.hadoop.mapreduce的新API
3. HBase: 類似Google BigTable的分散式NoSQL列資料庫。(HBase和Avro已經於2010年5月成為頂級 Apache 專案)
4. Hive:資料倉庫工具,由Facebook貢獻。
5. Zookeeper:分散式鎖設施,提供類似Google Chubby的功能,由Facebook貢獻。
6. Avro:新的資料序列化格式與傳輸工具,將逐步取代Hadoop原有的IPC機制。
7. Pig: 大資料分析平臺,為使用者提供多種介面。
8. Ambari:Hadoop管理工具,可以快捷的監控、部署、管理叢集。
9. Sqoop:於在HADOOP與傳統的資料庫間進行資料的傳遞。
HDFS
HDFS 絕對是Hadoop的創舉,因為要對大批量的資料進行處理,如果採取集中的方式,那麼一定會受限於計算資源的限制,必須採取分散式的架構,利用分而治之的思想才能將負載分發到整個叢集中去,分散式
檔案系統就應運而生了。分散式的儲存使得檔案存放在眾多的節點上,而只需要一個節點去記錄這些檔案的元資料資訊(主要是檔案的位置),在訪問檔案的時候,先訪問這個元資料節點,獲取檔案所在的位置,
然後再獲取檔案。使用者不必關心檔案儲存在哪個節點上,而且由於分散式儲存已經解決了高可用的問題,所以使用者不必擔心資料儲存的可用性。
HDFS的設計思想來源於谷歌的GFS(Google File System),Google釋出的MapReduce論文中提出了基本的框架,在HDFS中得到了充分的體現。HDFS中的檔案預設儲存三份,所以一份丟失不會造成資料丟失,可以
根據另外兩份恢復回來。HDFS儲存資料的基本單元是塊(Block),大小為64M。
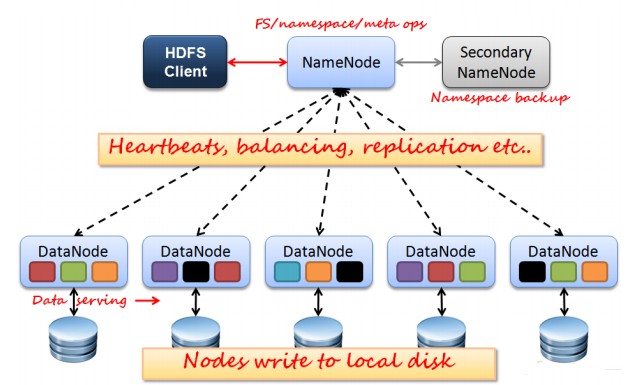
HDFS 有兩種Node,一種是NameNode,負責記錄具體資料的元資料資訊,另一種是DataNode,真正的資料節點。這裡的NameNode有兩個,另一個主要作用是分擔主NameNode的一部分工作負載。每一個檔案的副本
儲存在不同的節點上,可以通過配置,讓HDFS感知機架,這樣副本會儲存在不通的機架上,即使整個機架壞掉,資料也是可以恢復的。不同副本之間的資料複製由HDFS負責。在NameNode和DataNode之間維持著心跳
NameNode能夠感知DataNode的狀態,DataNode變得不可用,會啟用副本複製。
MapReduce
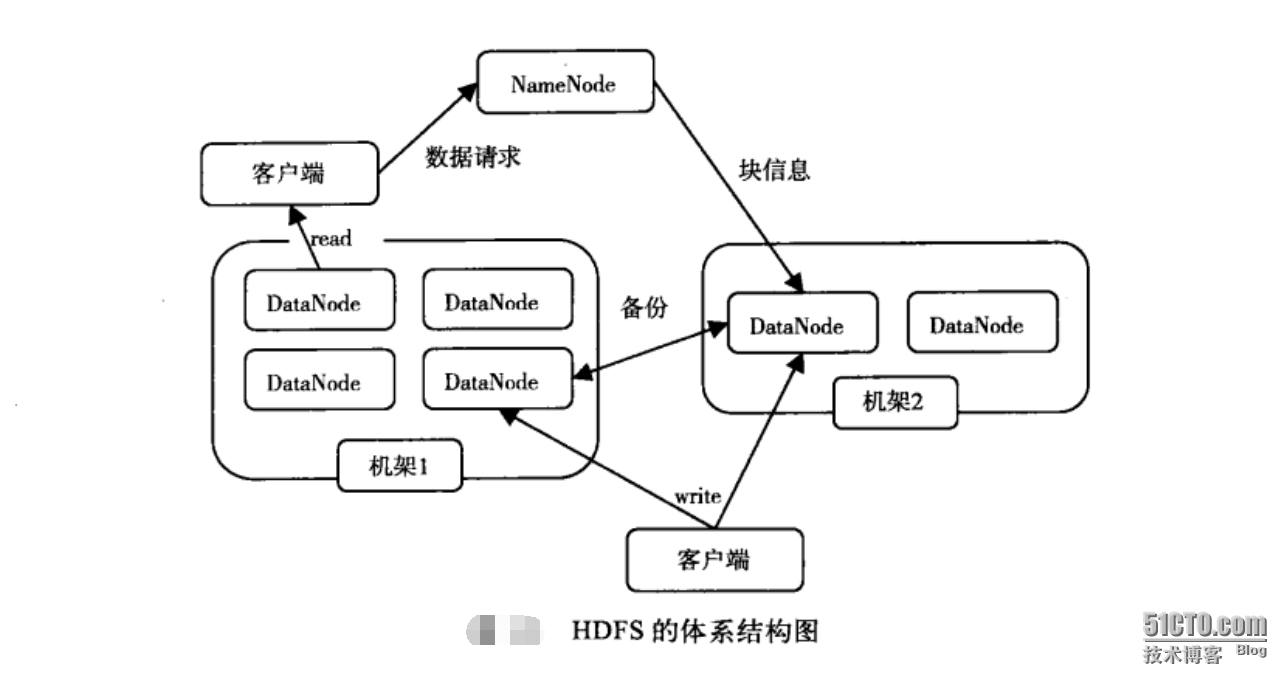
從請求處理的流程來看,資料寫入時,資料會在不同機架上的節點上進行寫入。資料讀取的時候,NameNode會查詢這個資料的塊資訊,根據這些資訊去相應節點上獲取資料,返回給客戶端。建立檔案時,先在NameNode
上建立檔案,然後寫入資料到DataNode,資料在DataNode之間進行復制,寫入成功後,返回資訊給NameNode,確認檔案建立成功後,記錄檔案的相關資訊(儲存位置等等)。
MapReduce 是一種分而治之的思想,谷歌在論文中提出的這種思想成為了後來分散式任務處理的標準。Map是對映,Reduce則是歸約,對於輸入的資料來說,先需要分片,然後通過Map對資料進行處理,處理的結果是k/v
這個k/v是針對每個map接收到的分片進行的操作,每一個map操作輸出至少一個key/value對,根據map的key對map的輸出先進行合併,每一個key對應一個reduce,各個reduce做各自的處理。
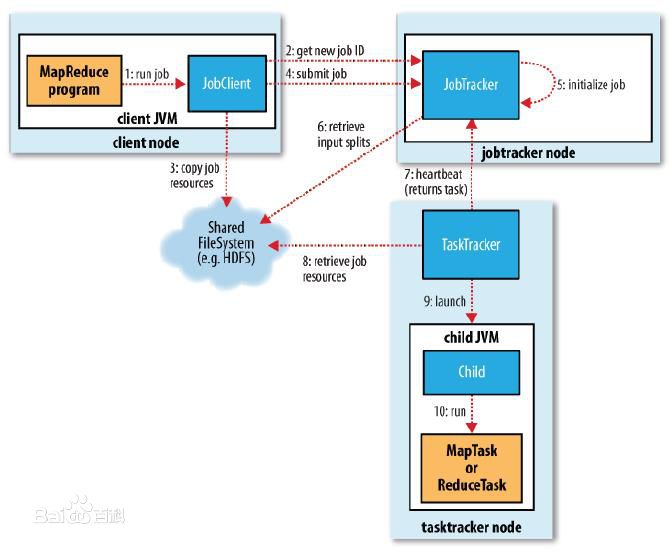
MapReduce由JobTracker接收使用者提交的Job,然後下發任務到各個節點上,由節點上的Task Tracker負責具體執行。當然這只是一個大概的流程,實際情況下會有更多具體的細節。這個例子中,我們可以看出Map和
Reduce的原理。Map對每一個接收到的內容做相同的處理,即記錄每個單詞的次數,然後列一個清單進行輸出,在進入到Reduce之前有一個合併key的過程,即將各個Map輸出的相同的Key進行合併(shuffle),這個過程
彙總所有Map輸出的Key和Value,彙總之後的key就是最終reduce的輸入的key,那麼value則很可能是多個值的集合,因為map合併的時候,相同的key作為一個key,但是value會存入一個數組作為這個key的value。
每個Reduce從Map的輸出中獲取資料,然後彙總每個key對應的值,最終多個Reduce的結果再做一次彙總就輸出為最終的內容。在整個過程中,只有map操作和reduce操作是使用者需要關係的,其他的部分全部交給Hadoop。
通俗易懂的例子
在講到MapReduce時,總是會講到wordcount的例子,之後再想想,貌似腦海裡又不清晰了。網上有個人分享了一個撲克牌分類的例子,非常貼切。
需要在一堆撲克牌(張數未知)中統計四種花色的牌有多少張,只需要找幾個人,每人給一堆,數出來四種花色的張數,然後彙總給另外一個人就可以了。比如兩個人每人一堆撲克牌,查出紅桃、黑桃、梅花、方片之
後四個人,每個人只負責統計一種花色,最終將結果彙報給一個人,這是典型的map-reduce模型。
細節探討
- split 的機制
在Map之前,資料會被分片(split),分片的結果決定了map的個數,那麼分片的機制如何呢?
Hadoop 2.x預設的block大小是128MB,Hadoop 1.x預設的block大小是64MB,可以在hdfs-site.xml中設定dfs.block.size,注意單位是byte。
分片大小範圍可以在mapred-site.xml中設定,mapred.min.split.size mapred.max.split.size,minSplitSize大小預設為1B,maxSplitSize大小預設為Long.MAX_VALUE = 9223372036854775807
在我們沒有設定分片的範圍的時候,分片大小是由block塊大小決定的,和它的大小一樣。比如把一個258MB的檔案上傳到HDFS上,假設block塊大小是128MB,那麼它就會被分成三個block塊,與之對應產生三個split,所以最終會產生三個map task。我又發現了另一個問題,第三個block塊裡存的檔案大小隻有2MB,而它的block塊大小是128MB,那它實際佔用Linux file system的多大空間?答案是實際的檔案大小,而非一個塊的大小。
- shuffle 的原理
hadoop的核心思想是MapReduce,但shuffle又是MapReduce的核心。shuffle的主要工作是從Map結束到Reduce開始之間的過程。首先看下這張圖,就能瞭解shuffle所處的位置。圖中的partitions、copy phase、sort phase所代表的就是shuffle的不同階段。
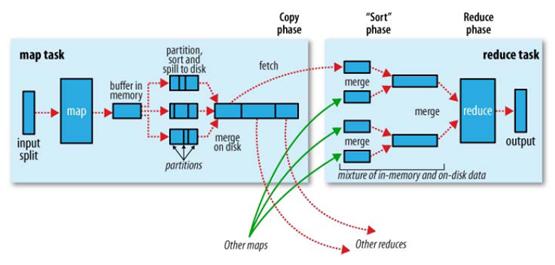
shuffle階段又可以分為Map端的shuffle和Reduce端的shuffle。
1.Map端的shuffle
Map端會處理輸入資料併產生中間結果,這個中間結果會寫到本地磁碟,而不是HDFS。每個Map的輸出會先寫到記憶體緩衝區中,當寫入的資料達到設定的閾值時,系統將會啟動一個執行緒將緩衝區的資料寫到磁碟,這個過程叫做spill。
在spill寫入之前,會先進行二次排序,首先根據資料所屬的partition進行排序,然後每個partition中的資料再按key來排序。partition的目是將記錄劃分到不同的Reducer上去,以期望能夠達到負載均衡,以後的Reducer就會根據partition來讀取自己對應的資料。接著執行combiner(如果設定了的話),combiner的本質也是一個Reducer,其目的是對將要寫入到磁碟上的檔案先進行一次處理,這樣,寫入到磁碟的資料量就會減少。最後將資料寫到本地磁碟產生spill檔案(spill檔案儲存在{mapred.local.dir}指定的目錄中,Map任務結束後就會被刪除)。
最後,每個Map任務可能產生多個spill檔案,在每個Map任務完成前,會通過多路歸併演算法將這些spill檔案歸併成一個檔案。至此,Map的shuffle過程就結束了。
2.Reduce端的shuffle
Reduce端的shuffle主要包括三個階段,copy、sort(merge)和reduce。
首先要將Map端產生的輸出檔案拷貝到Reduce端,但每個Reducer如何知道自己應該處理哪些資料呢?因為Map端進行partition的時候,實際上就相當於指定了每個Reducer要處理的資料(partition就對應了Reducer),所以Reducer在拷貝資料的時候只需拷貝與自己對應的partition中的資料即可。每個Reducer會處理一個或者多個partition,但需要先將自己對應的partition中的資料從每個Map的輸出結果中拷貝過來。
接下來就是sort階段,也稱為merge階段,因為這個階段的主要工作是執行了歸併排序。從Map端拷貝到Reduce端的資料都是有序的,所以很適合歸併排序。最終在Reduce端生成一個較大的檔案作為Reduce的輸入。
最後就是Reduce過程了,在這個過程中產生了最終的輸出結果,並將其寫到HDFS上。
總結
Hadoop 的資料處理過程的細節在實際專案中進行運用時,才會真正體會到深刻的原理,希望能遇到更多的有價值的例項。本篇借鑑了很多有價值的部落格內容,在此表示感謝。
部分內容引用自: